Een Kafka- en Spark-architectuur maken
Als u Kafka en Spark samen in Azure HDInsight wilt gebruiken, moet u deze in hetzelfde VNet plaatsen of de VNets peeren, zodat de clusters werken met DNS-naamomzetting.
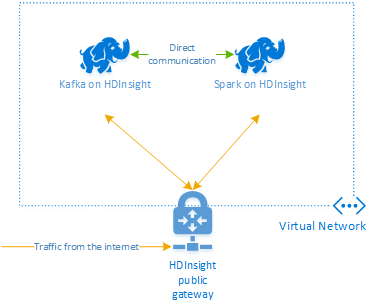
Voor het maken van clusters in hetzelfde VNet is de procedure:
- Een brongroep maken
- Een VNet toevoegen aan de resourcegroep
- Voeg een Kafka-cluster en een Spark-cluster toe aan hetzelfde VNet of koppel de VNets waarin deze services werken met DNS-naamomzetting.
De aanbevolen manier om het HDInsight Kafka- en Spark-cluster te verbinden, is de systeemeigen Spark-Kafka-connector, waarmee het Spark-cluster toegang heeft tot afzonderlijke partities van gegevens in het Kafka-cluster, waardoor de parallelle uitvoering die u in uw realtime verwerkingstaak hebt, toeneemt en zeer hoge doorvoer biedt.
Wanneer beide clusters zich in hetzelfde VNet bevinden, kunt u ook Kafka Broker-FQDN's gebruiken in de Spark-streamingcode en kunt u NSG-regels maken op het VNet voor bedrijfsbeveiliging.
Architectuur voor de oplossing
Realtime streaminganalysepatronen in Azure gebruiken doorgaans de volgende oplossingsarchitectuur.
- Opnemen: ongestructureerde of gestructureerde gegevens worden opgenomen in een Kafka-cluster in Azure HDInsight.
- Voorbereiden en trainen: gegevens worden voorbereid en getraind met Spark in HDInsight.
- Model en service: gegevens worden in een datawarehouse geplaatst, zoals Azure Synapse of HDInsight Interactive Query.
- Intelligentie: gegevens worden geleverd aan analysedashboards, zoals Power BI of Tableau.
- Opslag: Gegevens worden in een koude opslagoplossing geplaatst, zoals Azure Storage, en worden later verwerkt.
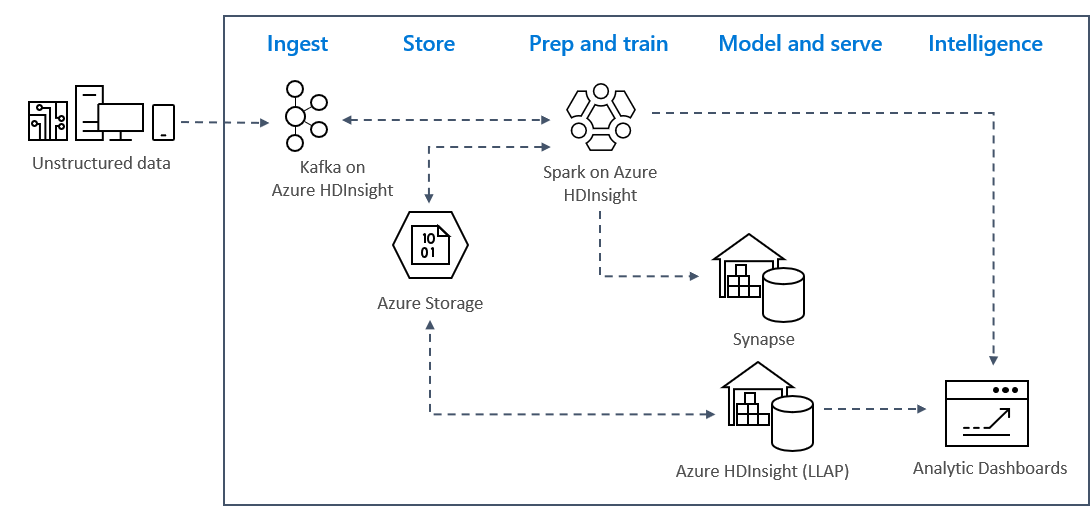
Voorbeeldscenarioarchitectuur
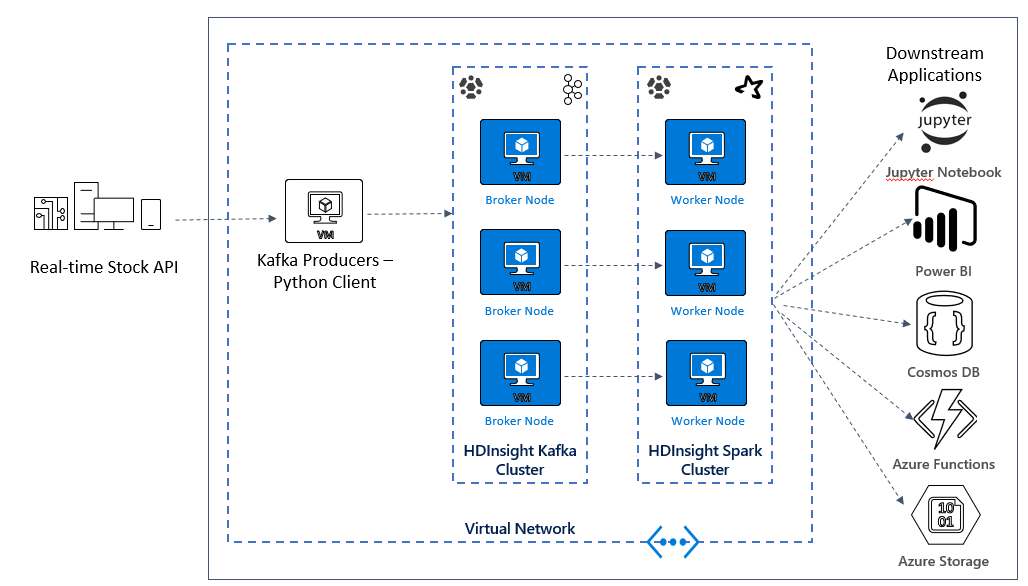
In de volgende les begint u met het bouwen van de oplossingsarchitectuur voor de voorbeeldtoepassing. In dit voorbeeld wordt een Azure Resource Manager-sjabloonbestand gebruikt om de resourcegroep, het VNET, het Spark-cluster en het Kafka-cluster te maken.
Zodra de clusters zijn geïmplementeerd, gaat u naar een van de Kafka-brokers en kopieert u het Python-producerbestand naar het hoofdknooppunt. Dat producentbestand biedt elke 10 seconden kunstmatige aandelenkoersen, maar schrijft ook het partitienummer en de offset van het bericht naar de console.
Zodra de producent wordt uitgevoerd, kunt u de Jupyter-notebook uploaden naar het Spark-cluster. In het notebook verbindt u de Spark- en Kafka-clusters en voert u enkele voorbeeldquery's uit op de gegevens, waaronder het vinden van de hoge en lage waarden voor een voorraad in een gebeurtenisvenster.