Gegevens streamen met Apache Kafka
Apache Kafka is in 2010 gemaakt door LinkedIn, met als doel gegevens op zeer hoge schaal te verplaatsen met een zeer lage latentie met een hoog fouttolerantieniveau. LinkedIn heeft het project vervolgens in 2012 aan de Apache-stichting gedoneerd, maar LinkedIn maakt nog steeds gebruik van Kafka in het hele ecosysteem voor het bijhouden van gebruikersactiviteiten, het uitwisselen van berichten en het verzamelen van metrische gegevens.
Kafka is een gedistribueerd streamingplatform dat is ontworpen om:
- Gegevenspijplijnen vereenvoudigen
- Grote hoeveelheden gegevens in een streamingpatroon verwerken
- Ondersteuning voor realtime- en batchsystemen
- Horizontaal schalen
Laten we eerst meer te weten komen over pure Apache Kafka en vervolgens over Kafka in Azure HDInsight.
Kafka-onderdelen
Voordat we begrijpen hoe Kafka werkt, gaan we kijken naar rollen van enkele van de belangrijkste onderdelen van Kafka en hoe ze samenkomen om een zeer schaalbaar en fouttolerant berichtensysteem te bieden.
Broker
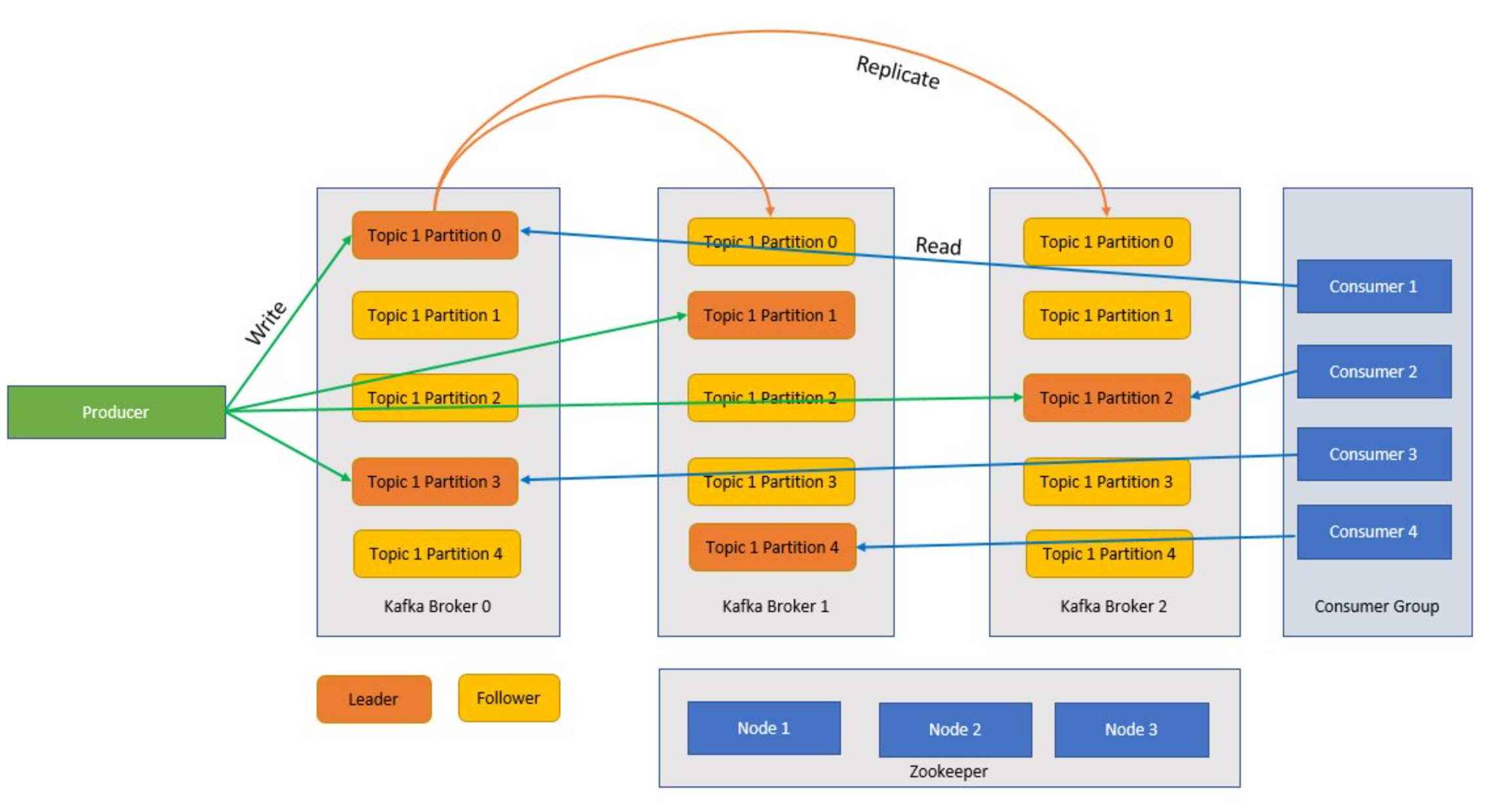
Kafka is een geclusterde service en één Kafka-cluster wordt ook wel een broker genoemd. Brokers ontvangen berichten van producenten en slaan deze berichten op schijf op. De broker reageert ook op het ophalen van aanvragen van consumenten. Binnen een cluster van brokers fungeert één broker als controller en is verantwoordelijk voor administratieve bewerkingen en het toewijzen van partities aan brokers.
Bericht
Een gegevenseenheid in een Kafka-cluster. Berichten in de meeste gevallen zijn sleutel-waardeparen.
Onderwerpen en partities
Onderwerpen en partities zijn categorieën berichten in Kafka. Onderwerpen worden normaal gesproken onderverdeeld in een aantal partities om het geheel te verbeteren, met een aanbevolen minimum van drie partities. Berichten worden alleen naar een onderwerppartitie geschreven. Partities worden verder gerepliceerd over meerdere brokers om redundantie te verbeteren in het geval van brokerfouten. Met partities kunnen onderwerpen parallel worden gelezen omdat ze gegevens kunnen splitsen tussen meerdere brokers. Er is een leiderreplica die alle lees-/schrijfaanvragen verwerkt en de volgers worden gerepliceerd van de leider. Als een leider mislukt, wordt een van de replica's de leider.
Producenten en consumenten
Producenten en consumenten zijn de klanten die berichten produceren en verbruiken van het Kafka-systeem. Producenten publiceren nieuwe berichten en sturen ze naar een specifiek onderwerp. Consumenten kunnen ook worden ontworpen om naar een specifieke onderwerppartitie te schrijven. Consumenten abonneren zich op een of meer onderwerpen en lezen berichten uit deze onderwerpen.
Consumentengroep
Een of meer consumenten kunnen samenwerken als een groep en berichten als groep gebruiken. Als het aantal consumenten gelijk is aan het aantal onderwerppartities, verbruikt elke consument één onderwerppartitie die parallellisme maakt.
Retentie
Berichten in Kafka kunnen gedurende een vooraf gedefinieerde periode worden bewaard in het Kafka-cluster. Nadat de bewaarlimieten zijn bereikt, kan Kafka deze berichten laten verlopen en verwijderen.
Verschuiving
Een offset is gewoon de positie van een bericht in een partitie. Het bijwerken van de huidige positie in een partitie wanneer berichten worden verwerkt, wordt een doorvoering genoemd. Nadat een bericht is verwerkt, voert Kafka de verschuiving van het bericht door naar een speciaal intern Kafka-onderwerp. Wanneer een producent een bericht naar een partitie publiceert, wordt het doorgestuurd naar de leider. De leider voegt het bericht toe aan het doorvoerlogboek en voegt de verschuiving van het bericht toe. De verschuiving van het bericht is de wijze waarop berichten in het onderwerp worden geïdentificeerd. Het bericht is alleen beschikbaar voor de consument nadat het bericht is doorgevoerd in het cluster.
Zookeeper
Zookeeper is een coördinatieservice en in een Kafka-cluster biedt zookeeper een synchroon overzicht van de status van het cluster. Kafka maakt gebruik van Zookeeper voor leiderverkiezing tussen broker- en onderwerppartities. Kafka maakt gebruik van Zookeeper voor het beheren van servicedetectie voor Kafka-brokers die het cluster vormen. Zookeeper verzendt wijzigingen van de topologie naar Kafka, dus elk knooppunt in het cluster weet wanneer een nieuwe broker is toegevoegd, een broker is overleden, een onderwerp is verwijderd of een onderwerp is toegevoegd.
Hoe komt het allemaal samen?
Toepassingen (ook wel producenten genoemd) verzenden berichten naar een Kafka-broker en deze berichten worden verwerkt door een of meer consumenten. Berichten in een cluster worden gecategoriseerd op onderwerpen. Een klant kan bijvoorbeeld een onderwerp 'Verkoop' maken om alle berichten te verzenden die relevant zijn voor verkoop, enzovoort. Naarmate onderwerpen groter worden met toenemende berichten, worden ze gesplitst in partities en worden deze partities verder gerepliceerd in Kafka-brokers voor redundantie. Partities worden gecategoriseerd als leiders en volgers. De leiderpartitie wordt geschreven naar en gelezen van waaruit de volgerpartities gewoon replica's zijn, die de status van de leider inhalen. Om te bepalen van welke partitie moet worden geschreven naar en gelezen van, moeten producenten en consumenten weten welke partities zijn ontworpen leiders. Zookeeper-knooppunten beheren de status van het Kafka-cluster en kiezen onder andere partitieleiders en bieden deze informatie aan producenten en consumenten.
Kafka biedt garanties dat berichten met een partitie worden geordend in dezelfde volgorde waarin ze zijn geleverd. Een specifiek bericht kan duidelijk worden geïdentificeerd via de offset die de positie binnen een partitie is. Consumenten lezen berichten van partities en naverwerking, voer de offset door die aangeeft dat het bericht is verwerkt. Kafka slaat alle records op schijf op en onderhoudt berichtpersistentie. Als de consument om een of andere reden wordt onderbroken en de verwerking stopt, behoudt Kafka deze berichten voor een vooraf vastgestelde bewaarperiode en nadat de consument weer online is gekomen, kan de verwerking opnieuw worden gestart vanaf de vastgelegde offset waar deze is gebleven vóór de onderbreking.
Kafka-onderwerpen
Een Kafka-onderwerp is een feed of een wachtrij waarin berichten worden opgeslagen en gepubliceerd. Producenten pushen berichten naar onderwerpen en consumenten lezen uit onderwerpen. Elk knooppunt in een Kafka-broker kan meerdere onderwerpen bevatten.
Wat zijn de voordelen van Kafka in Azure HDInsight?
De opensource-versie van Kafka biedt veel mogelijkheden, maar er is veel werk bij het instellen ervan. Azure HDInsight biedt het beste van opensource-analyseframeworks naar Azure en maakt het eenvoudig voor klanten om hun opensource-clusters binnen enkele minuten in te stellen, in plaats van weken of maanden deze clusters in te stellen en u kunt ze meteen gebruiken. HDInsight is ook geschikt voor ondernemingen met de volgende voordelen:
- Het is een beheerde service die een vereenvoudigd configuratieproces mogelijk maakt. Het resultaat is een configuratie die is getest en die wordt ondersteund door Microsoft.
- Microsoft biedt een SLA (Service Level Agreement) van 99,9% voor Spark en Kafka.
- Het gebruikt Azure Managed Disks als de externe opslag voor Kafka. Managed Disks kan maximaal 16 TB opslagruimte per Kafka-broker bieden, met meerdere Kafka-brokers.
- HDInsight biedt de beste bedrijfsbeveiliging met VNets, verfijnde beveiliging met Apache Ranger en BYOK-versleuteling (Bring Your Own Key) voor data-at-rest
- Naleving voor HIPAA, SOC en PCI
- De mogelijkheid om end-to-end streamingpijplijnen met Spark en Storage te implementeren via geautomatiseerde ARM-sjablonen (Azure Resource Manager) in hetzelfde VNet.
- Hoge beschikbaarheid kan worden bereikt met Kafka MirrorMaker, die records uit onderwerpen op het primaire cluster kan gebruiken en vervolgens een lokale kopie op het secundaire cluster kan maken.
- Met HDInsight kunt u het aantal werkknooppunten (waarop de Kafka-broker wordt gehost) wijzigen na het maken van het cluster. Schalen kan worden uitgevoerd vanuit Azure Portal, Azure PowerShell en andere interfaces voor Azure-beheer. Voor Kafka moet u partitiereplica's na het schalen herverdelen. Door herverdeling van partities kan Kafka gebruikmaken van het nieuwe aantal worker-knooppunten.
- Azure Monitor-logboeken kan worden gebruikt voor het bewaken van Kafka in HDInsight. Azure Monitor-logboeken bevatten informatie op het niveau van virtuele machines, zoals metrische gegevens over schijven en NIC's en metrische gegevens van JMX uit Kafka.