Gegevens combineren en optimaliseren
Organisaties sorteren vaak verschillende soorten informatie uit veel bronnen. De informatie wordt opgeslagen in een groot aantal tabellen. Soms moet u tabellen samenvoegen op basis van logische relaties tussen deze tabellen voor een diepere analyse of rapportage. In het scenario van het retailbedrijf gebruikt u tabellen voor klanten, producten en verkoopgegevens.
In deze module leert u over verschillende manieren om gegevens in Kusto-query's te combineren om uw teamleden de informatie te geven die ze nodig hebben om de productbewustzijn te vergroten en de verkoop te vergroten.
Inzicht in uw gegevens
Voordat u query's gaat schrijven die informatie uit uw tabellen combineren, moet u uw gegevens begrijpen. Wanneer u met Kusto-query's werkt, wilt u tabellen beschouwen als een van de volgende twee categorieën:
- Feitentabellen: tabellen waarvan records onveranderbaar zijn feiten, zoals de tabel SalesFact in het scenario van het detailhandelbedrijf. In deze tabellen worden records geleidelijk op een streamende manier of in grote segmenten toegevoegd. De records blijven in de tabel staan totdat ze worden verwijderd en ze worden nooit bijgewerkt.
- dimensietabellen: tabellen waarvan de records veranderlijk zijn dimensies, zoals de tabellen Klanten en Producten in het scenario van het retailbedrijf. Deze tabellen bevatten referentiegegevens, zoals opzoektabellen van een entiteits-id naar de eigenschappen ervan. Dimensietabellen worden niet regelmatig bijgewerkt met nieuwe gegevens.
In ons retailbedrijfsscenario gebruikt u dimensietabellen om de tabel SalesFact te verrijken met aanvullende informatie of om meer opties te bieden voor het filteren van de gegevens voor query's.
U wilt ook inzicht hebben in de volumes met gegevens waarmee u werkt en de bijbehorende structuur of het schema (kolomnamen en -typen). U kunt de volgende query's uitvoeren om die informatie op te halen door TABLE_NAME te vervangen door de naam van de tabel die u bekijkt:
Gebruik de operator
countom het aantal records in een tabel op te halen:TABLE_NAME | countGebruik de operator
getschemaom het schema van een tabel op te halen:TABLE_NAME | getschema
Als u deze query's uitvoert op feiten- en dimensietabellen in het scenario van het retailbedrijf, krijgt u informatie zoals in het volgende voorbeeld:
| Tafel | Gegevens | Schema |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (echt) - TotalCost (reëel) - DateKey (datum/tijd) - ProductKey (long) - CustomerKey- (lang) |
| Klanten | 18,484 | - CityName (tekenreeks) - CompanyName (tekenreeks) - ContinentName (tekenreeks) - CustomerKey (lang) - Onderwijs - Voornaam (tekenreeks) - Geslacht (tekenreeks) - Achternaam (tekenreeks) - MaritalStatus (tekenreeks) - Beroep (string) - RegionCountryName (tekenreeks) - StateProvinceName (tekenreeks) |
| Producten | 2,517 | - ProductName (tekenreeks) - Fabrikant (string) - ColorName (tekenreeks) - ClassName (tekenreeks) - ProductCategoryName (tekenreeks) - ProductSubcategoryName (tekenreeks) - ProductKey (lang) |
In de tabel hebben we de unieke id's CustomerKey en ProductKey gemarkeerd die worden gebruikt om records tussen tabellen te combineren.
Inzicht in query's met meerdere tabellen
Nadat u uw gegevens hebt geanalyseerd, moet u weten hoe u tabellen combineert om de informatie te verstrekken die u nodig hebt. Kusto-query's bieden verschillende operators die u kunt gebruiken om gegevens uit meerdere tabellen te combineren, waaronder de operatoren lookup, joinen union.
De operator join voegt de rijen van twee tabellen samen door overeenkomende waarden van de opgegeven kolommen uit elke tabel te vergelijken. De resulterende tabel is afhankelijk van het type join dat u gebruikt. Als u bijvoorbeeld een inner join-gebruikt, heeft de tabel dezelfde kolommen als de linkertabel (ook wel de buitenste tabelgenoemd), plus de kolommen uit de rechtertabel (ook wel de interne tabelgenoemd). In het volgende gedeelte leert u meer over soorten joins. Voor de beste prestaties: als de ene tabel altijd kleiner is dan de andere, gebruik deze dan als de linkerkant van de operator join.
De operator lookup is een speciale implementatie van een join-operator die de prestaties van query's optimaliseert waarbij een feitentabel wordt verrijkt met gegevens uit een dimensietabel. Hiermee wordt de feitentabel uitgebreid met waarden die in een dimensietabel worden opgezoekd. Voor de beste prestaties gaat het systeem standaard ervan uit dat de linkertabel de grotere (feitentabel) is en dat de rechtertabel de kleinere (dimensietabel) is. Deze aanname is precies het tegenovergestelde van de veronderstelling die wordt gebruikt door de operator join.
De operator union retourneert alle rijen uit twee of meer tabellen. Het is handig als u gegevens uit meerdere tabellen wilt combineren.
De materialize()-functie slaat resultaten in een queryuitvoering op voor later hergebruik in de query. Het is alsof u een momentopname maakt van de resultaten van een subquery en deze meerdere keren in de query gebruikt. Deze functie is handig bij het optimaliseren van query's voor scenario's waarin de resultaten worden weergegeven:
- Zijn duur om te berekenen
- Niet-deterministisch zijn
Kortom, u leert meer over de verschillende operatoren voor het samenvoegen van tabellen en de functie materialize() en hoe u deze kunt gebruiken.
Soorten van verbindingen
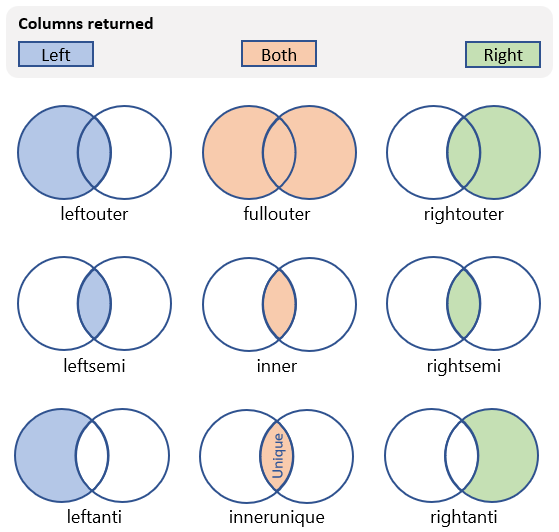
Er zijn veel verschillende soorten joins die kunnen worden uitgevoerd die van invloed zijn op het schema en de rijen in de resulterende tabel. In de volgende tabel ziet u de soorten joins die worden ondersteund door de Kusto-querytaal en het schema en de rijen die ze retourneren:
| Soort join | Beschrijving | Illustratie |
|---|---|---|
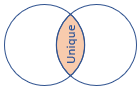
innerunique (standaard) |
Inner join met verwijderen van duplicaten aan de linkerkant Schema: alle kolommen uit beide tabellen, inclusief de overeenkomende sleutels rijen: alle ontdubbelde rijen uit de linkertabel die overeenkomen met rijen uit de rechtertabel |
|
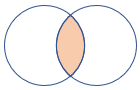
inner |
Standaard inner join Schema: alle kolommen uit beide tabellen, inclusief de overeenkomende sleutels rijen: alleen overeenkomende rijen uit beide tabellen |
|
leftouter |
Linker buitenste join Schema: alle kolommen uit beide tabellen, inclusief de overeenkomende sleutels rijen: alle records uit de linkertabel en alleen overeenkomende rijen uit de rechtertabel |

|
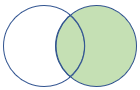
rightouter |
rechterbuitenjoin Schema: alle kolommen uit beide tabellen, inclusief de overeenkomende sleutels rijen: alle records uit de rechtertabel en alleen overeenkomende rijen uit de linkertabel |
|
fullouter |
Volledige buitenste join Schema: alle kolommen uit beide tabellen, inclusief de overeenkomende sleutels rijen: alle records uit beide tabellen met niet-overeenkomende cellen gevuld met null |
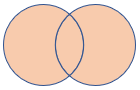
|
leftsemi |
Linker semi-join Schema-: alle kolommen uit de linkertabel rijen: alle records uit de linkertabel die overeenkomen met records uit de rechtertabel |
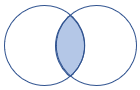
|
leftanti, anti, leftantisemi |
Linker anti-join en semi-variant Schema-: alle kolommen uit de linkertabel rijen: alle records uit de linkertabel die niet overeenkomen met records uit de rechtertabel |
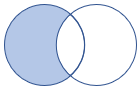
|
rightsemi |
Rechter semijoin Schema: alle kolommen uit de rechtertabel rijen: alle records uit de rechtertabel die overeenkomen met records uit de linkertabel |
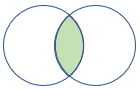
|
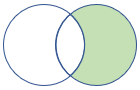
rightanti, rightantisemi |
Rechter anti-join en semi-variant Schema: alle kolommen uit de rechtertabel rijen: alle records uit de rechtertabel die niet overeenkomen met records uit de linkertabel |
|
U ziet dat het standaardtype join is inneruniqueen niet hoeft te worden opgegeven. Toch is het een best practice om altijd expliciet het soort join voor duidelijkheid op te geven.
Tijdens het doorlopen van deze module leert u ook meer over de arg_min()- en arg_max()-aggregatiefuncties, de operator as als alternatief voor de let-instructie en de startofmonth()-functie om u te helpen bij het groeperen van gegevens per maand.