Modellen registreren en bedienen met MLflow
Met modelregistratie kunnen MLflow en Azure Databricks modellen bijhouden; dat om twee redenen belangrijk is:
- Door een model te registreren, kunt u het model bedienen voor realtime, streaming of batchdeductie. Registratie maakt het proces van het gebruik van een getraind model eenvoudig, omdat gegevenswetenschappers nu geen toepassingscode hoeven te ontwikkelen; het verwerkende proces bouwt die wrapper en maakt automatisch een REST API of methode beschikbaar voor batchgewijs scoren.
- Als u een model registreert, kunt u in de loop van de tijd nieuwe versies van dat model maken; geeft u de mogelijkheid om modelwijzigingen bij te houden en zelfs vergelijkingen uit te voeren tussen verschillende historische versies van modellen.
Een model registreren
Wanneer u een experiment uitvoert om een model te trainen, kunt u het model zelf registreren als onderdeel van de uitvoering van het experiment, zoals hier wordt weergegeven:
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model = model,
artifact_path=unique_model_name,
conda_env=mlflow.spark.get_default_conda_env())
Wanneer u de uitvoering van het experiment bekijkt, inclusief de vastgelegde metrische gegevens die aangeven hoe goed het model voorspelt, wordt het model opgenomen in de runartefacten. Vervolgens kunt u de optie selecteren om het model te registreren met behulp van de gebruikersinterface in de experimentviewer.
Als u het model wilt registreren zonder de metrische gegevens in de uitvoering te controleren, kunt u de parameter registered_model_name opnemen in de methode log_model . In dat geval wordt het model automatisch geregistreerd tijdens de uitvoering van het experiment.
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model=model,
artifact_path=unique_model_name
conda_env=mlflow.spark.get_default_conda_env(),
registered_model_name="my_model")
U kunt meerdere versies van een model registreren, zodat u de prestaties van modelversies gedurende een bepaalde periode kunt vergelijken voordat u alle clienttoepassingen naar de best presterende versie verplaatst.
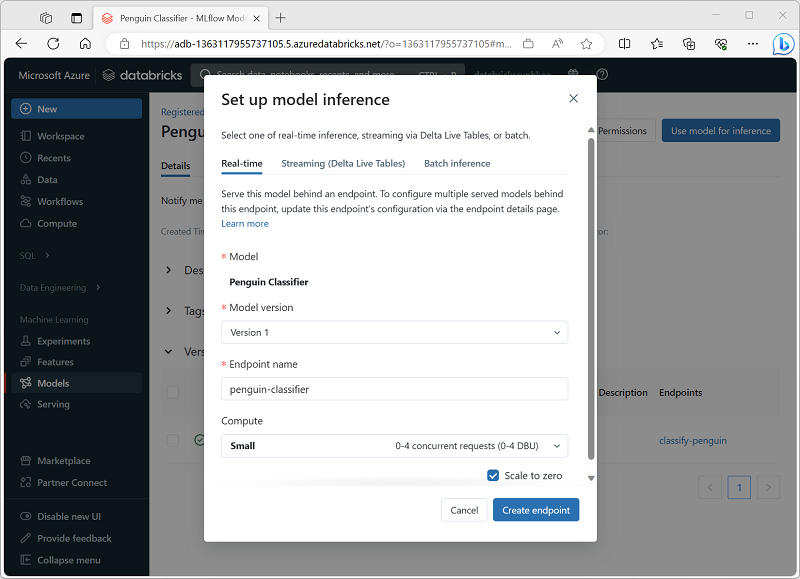
Een model gebruiken voor deductie
Het proces van het gebruik van een model om labels van nieuwe functiegegevens te voorspellen, wordt deductie genoemd. U kunt MLflow in Azure Databricks gebruiken om modellen op de volgende manieren beschikbaar te maken voor deductie:
- Host het model als een realtime-service met een HTTP-eindpunt waarnaar clienttoepassingen REST-aanvragen kunnen indienen.
- Gebruik het model om eeuwigdurende streamingdeductie van labels uit te voeren op basis van een deltatabel met functies, waarbij de resultaten naar een uitvoertabel worden geschreven.
- Gebruik het model voor batchdeductie op basis van een deltatabel en schrijf de resultaten van elke batchbewerking naar een specifieke map.
U kunt een model voor deductie implementeren vanaf de pagina in de sectie Modellen van de Azure Databricks-portal, zoals hier wordt weergegeven: