Het bronsysteem optimaliseren - geavanceerd
Deze geavanceerdere richtlijnen kunnen nuttig zijn voor de bronexport van VLDB-systemen:
Tabel met Oracle-rij-id splitsen
SAP heeft SAP Note #1043380 uitgebracht, dat een script bevat waarmee de WHERE-component in een WHR-bestand wordt geconverteerd naar een rij-id-waarde. De nieuwste versies van SAPInst genereren ook automatisch RIJ-ID-gesplitste WHR-bestanden als SWPM is geconfigureerd voor migratie van Oracle naar Oracle R3load. De STR- en WHR-bestanden die door SWPM worden gegenereerd, zijn onafhankelijk van het besturingssysteem en de database (net als alle aspecten van het migratieproces van het besturingssysteem/de DATABASE).
De OSS-notitie bevat de instructie 'ROWID table splitting CANNOT be used if the target database is a non-Oracle database'. Technisch gezien zijn de R3load-dumpbestanden onafhankelijk van de database en het besturingssysteem. Er is echter één beperking. Het opnieuw opstarten van een pakket tijdens het importeren is echter niet mogelijk op SQL Server. In dit scenario moet de hele tabel worden verwijderd en moeten alle pakketten voor de tabel opnieuw worden gestart. Het wordt altijd aanbevolen om R3load-taken te beëindigen voor een specifieke gesplitste tabel, de tabel AFKAPPEN en het hele importproces opnieuw te starten als één gesplitste R3load afbreekt. De reden hiervoor is dat het herstelproces dat is ingebouwd in R3load, bestaat uit het uitvoeren van enkele rij-per-rij DELETE-instructies om de records te verwijderen die zijn geladen door het R3load-proces dat wordt afgebroken. Dit is traag en veroorzaakt vaak blokkerings-/vergrendelingssituaties in de database. Ervaring heeft aangetoond dat het sneller is om de import van deze specifieke tabel vanaf het begin te starten, daarom is de beperking die wordt vermeld in SAP Note #1043380 geen beperking.
RIJ-id heeft een nadeel dat de berekening van de splitsingen moet worden uitgevoerd tijdens downtime. Zie SAP-opmerking #1043380.
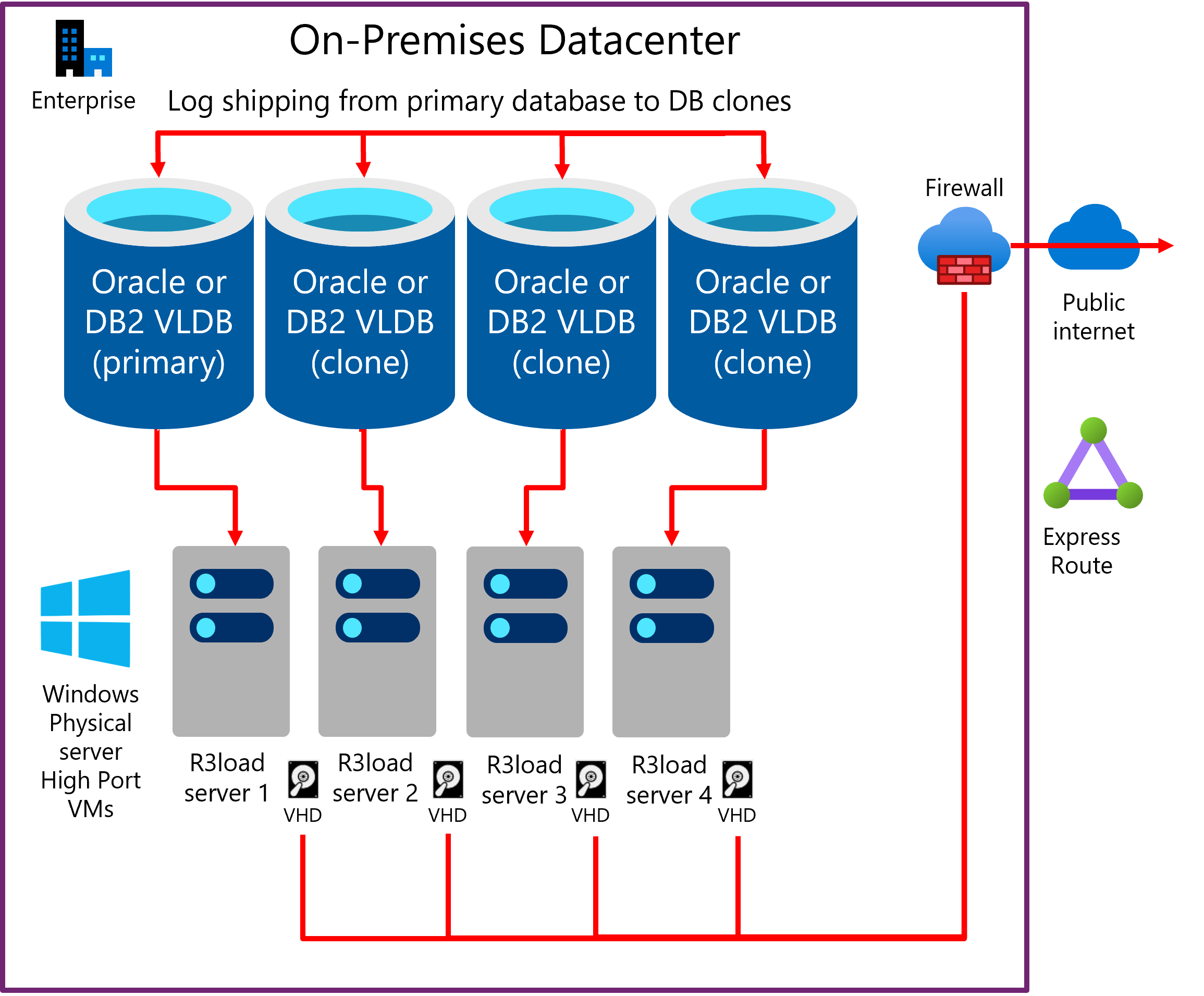
Meerdere klonen van de brondatabase maken en parallel exporteren
Een methode om de exportprestaties te verbeteren, is door te exporteren uit meerdere exemplaren van dezelfde database. Als de onderliggende infrastructuur, waaronder servers, netwerken en opslag schaalbaar zijn, is deze benadering doorgaans lineair schaalbaar. Exporteren vanuit twee exemplaren van dezelfde database is twee keer zo snel, vier exemplaren zijn vier keer zo snel. Migratiemonitor is geconfigureerd om te exporteren op een select aantal tabellen uit elke kloon van de database. In het volgende geval wordt de exportworkload ongeveer 25% gedistribueerd op elk van de vier databaseservers.
- DB-server 1 & exportserver 1 : toegewezen aan de grootste 1-4 tabellen (afhankelijk van hoe scheeftrekken van de gegevensdistributie zich in de brondatabase bevindt)
- DB-server 2 & exportserver 2 : toegewezen aan tabellen met tabelsplitsingen
- DB-server 3 & exportserver 3 : toegewezen aan tabellen met tabelsplitsingen
- DB-server 4 & exportserver 4 – alle resterende tabellen
Zorg ervoor dat de databases nauwkeurig worden gesynchroniseerd, anders kunnen gegevensverlies of inconsistenties optreden. Als de opgegeven stappen nauwkeurig worden gevolgd, blijft de gegevensintegriteit behouden.
De techniek is eenvoudig en goedkoop met standaard standaard Intel-hardware, maar is ook mogelijk voor klanten die eigen UNIX-hardware uitvoeren. Aanzienlijke hardwareresources zijn vrij in het midden van een besturingssysteem/DB-migratieproject wanneer sandbox-, ontwikkelings-, QAS-, trainings- en dr-systemen al zijn verplaatst naar Azure. Er is geen strikte vereiste dat de kloonservers identieke hardwarebronnen hebben. Met voldoende CPU-, RAM-, schijf- en netwerkprestaties verhoogt de toevoeging van elke kloon de prestaties.
Als er nog steeds extra exportprestaties nodig zijn, opent u een SAP-incident in BC-DB-MSS voor extra stappen om de exportprestaties te verbeteren (alleen geavanceerde consultants).
De stappen voor het implementeren van een meervoudige parallelle export zijn als volgt:
- Maak een back-up van de primaire database en herstel naar 'n' aantal servers (waarbij n = aantal klonen). In dit voorbeeld wordt ervan uitgegaan dat n = 3 servers zijn die in totaal vier DB-servers maken.
- Herstel de back-up op drie servers.
- Stel logboekverzending van de primaire brondatabaseserver in op drie doelservers voor klonen.
- Bewaak de logboekverzending gedurende enkele dagen en zorg ervoor dat logboekverzending betrouwbaar werkt.
- Sluit aan het begin van de downtime alle SAP-toepassingsservers af, behalve de PAS. Zorg ervoor dat alle batchverwerking is gestopt en al het RFC-verkeer is gestopt.
- Voer in transactie SM02 tekst 'Checkpoint PAS Running' in. Hiermee wordt tabel TEMSG bijgewerkt.
- Stop de primaire toepassingsserver. SAP is nu afgesloten. Er kan geen schrijfactiviteit meer plaatsvinden in de brondatabase. Zorg ervoor dat er geen niet-SAP-toepassing is verbonden met de brondatabase (er mag nooit zijn, maar controleer op niet-SAP-sessies op db-niveau).
- Voer deze query uit op de primaire DB-server:
SELECT EMTEXT FROM [schema].TEMSG; - Voer de instructie systeemeigen DBMS-niveau uit:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(de exacte syntaxis is afhankelijk van de bron-DBMS. INVOEGEN in EMTEXT) - Automatische back-ups van transactielogboeken stoppen. Voer handmatig een laatste back-up van transactielogboeken uit op de primaire DATABASE-server. Zorg ervoor dat de back-up van het logboek naar de kloonservers wordt gekopieerd.
- Herstel de laatste back-up van het transactielogboek op alle drie de knooppunten.
- Herstel de database op de 3 'kloonknooppunten'.
- Voer de volgende SELECT-instructie uit op alle vier de knooppunten:
SELECT EMTEXT FROM [schema].TEMSG; - Leg de schermresultaten van de SELECT-instructie vast voor elk van de vier DB-servers (de primaire en de drie klonen). Zorg ervoor dat u elke hostnaam zorgvuldig opneemt, om te dienen als bewijs dat de kloondatabase en de primaire database identiek zijn en dezelfde gegevens bevatten vanaf hetzelfde tijdstip.
- Start export_monitor.bat op elke Intel R3load-exportserver.
- Start het dumpbestand naar het Azure-proces (AzCopy of Robocopy).
- Start import_monitor.bat op de R3load Azure Virtual Machines.
In het volgende diagram ziet u een bestaande verzending van het productiedatabaselogboek naar 'kloon'-databases. Elke DB-server heeft een of meer Intel R3load-servers.