Inleiding
Machine learning transformeert de manier waarop bedrijven werken door gegevensgestuurde besluitvorming en automatisering mogelijk te maken. Het ontwikkelen van een machine learning-model is echter slechts het begin. De echte uitdaging is het implementeren van deze modellen in productieomgevingen waar ze realtime inzichten en voorspellingen kunnen leveren.
Azure Databricks is een veelzijdig platform dat data engineering en data science combineert. Het biedt een geïntegreerd analyseplatform dat het proces van het bouwen, trainen en implementeren van machine learning-modellen op schaal vereenvoudigt. Met de samenwerkingsomgeving kunnen gegevenswetenschappers en technici samenwerken om effectieve machine learning-oplossingen te maken.
Als u de mogelijkheden van Azure Databricks volledig wilt gebruiken, is het essentieel om inzicht te hebben in de volledige machine learning-werkstroom.
De machine learning-werkstroom verkennen
De machine learning-werkstroom is een uitgebreid proces dat verschillende kritieke taken omvat, die elk een essentiële rol spelen bij het ontwikkelen en implementeren van effectieve machine learning-modellen. De machine learning-werkstroom bevat de volgende taken:
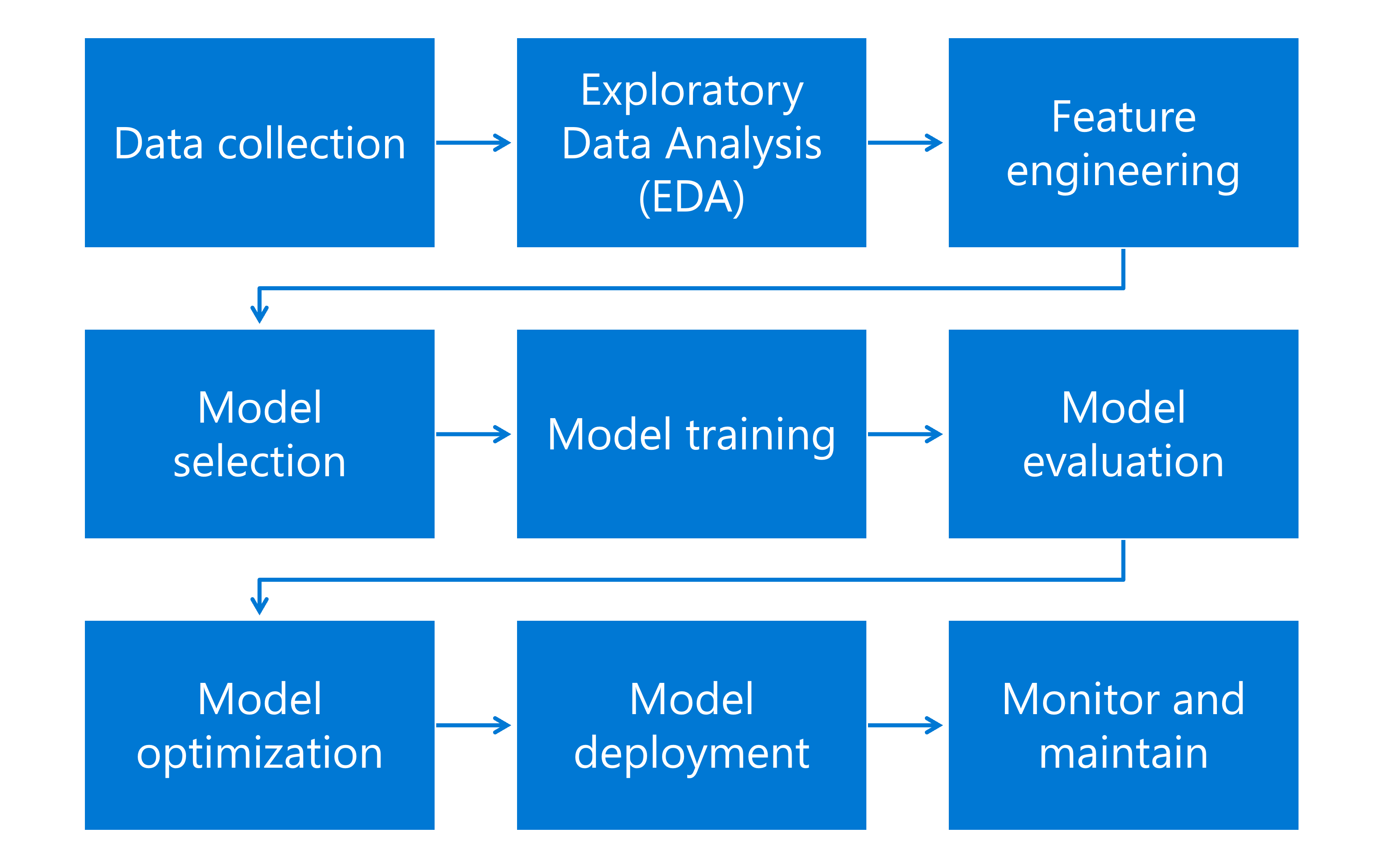
- Gegevensverzameling: De gegevens kunnen van alles zijn, van getallen en afbeeldingen tot tekst, afhankelijk van wat de computer moet leren.
- EDA (Exploratory Data Analysis): analyseer de gegevens om de belangrijkste kenmerken ervan samen te vatten en patronen te ontdekken.
- Functie-engineering: nieuwe functies maken of bestaande functies wijzigen om de modelprestaties te verbeteren.
- Modelselectie: Het model is een wiskundige formule of algoritme die voorspellingen doet door patronen in gegevens te vinden.
- Modeltraining: Het machine learning-algoritme gebruikt gegevens om de patronen te leren die de invoer (functies) verbinden met de uitvoer (doel). Het model past de parameters aan om het verschil tussen de voorspellingen en de werkelijke resultaten in de trainingsgegevens te minimaliseren.
- Modelevaluatie: de prestaties van het model worden geëvalueerd met behulp van een nieuwe set gegevens, de testset genoemd. Metrische gegevens, zoals nauwkeurigheid, precisie, relevante overeenkomsten en het gebied onder de ROC-curve, worden gebruikt om verschillende typen modellen te evalueren.
- Modeloptimalisatie: de parameters en het algoritme van het model zijn nauwkeurig afgestemd om de nauwkeurigheid en efficiëntie ervan te verbeteren.
- Modelimplementatie: het model wordt geïmplementeerd in een productieomgeving waarin batch- of realtime voorspellingen worden gemaakt.
- Bewaken en onderhouden: continue bewaking is van cruciaal belang om ervoor te zorgen dat het model effectief blijft naarmate er nieuwe gegevens en potentiële verschuivingen in de onderliggende gegevensdistributie plaatsvinden.
Als u door elke fase van de machine learning-werkstroom wilt navigeren en modellen in productie wilt brengen, is het belangrijk om de juiste hulpprogramma's en technologieën te gebruiken. Azure Databricks biedt samen met andere Azure-services een set hulpprogramma's die elke stap van dit proces ondersteunen. Van gegevensverzameling en functie-engineering tot modelimplementatie en bewaking biedt Azure hulpprogramma's die een soepele integratie en efficiënte werkstromen mogelijk maken.
Laten we eens kijken naar de hulpprogramma's waarmee u uw machine learning-werkstromen in productie kunt brengen.