Aangepaste AI-modellen maken met Azure Machine Learning
De beschikbaarheid van geavanceerde AI-modellen kan organisaties helpen om de intimiderende hoeveelheid resources die een data science-project kan vereisen aanzienlijk te verminderen. Laten we eens kijken hoe organisaties machine learning-uitdagingen en -bewerkingen kunnen aanpakken met Azure Machine Learning.
Machine learning-uitdagingen en behoefte aan machine learning-bewerkingen
Het onderhouden van AI-oplossingen vereist doorgaans het levenscyclusbeheer van Machine Learning om gegevens, code, modelomgevingen en de machine learning-modellen zelf te documenteren en te beheren. U moet processen opzetten voor het ontwikkelen, verpakken en implementeren van modellen, evenals het bewaken van hun prestaties en af en toe opnieuw trainen. En de meeste organisaties beheren tegelijkertijd meerdere modellen in productie, wat de complexiteit toevoegt.
Om effectief met deze complexiteit om te gaan, zijn er enkele aanbevolen procedures vereist. Ze richten zich op samenwerking tussen teams, het automatiseren en standaardiseren van processen en het garanderen dat modellen eenvoudig kunnen worden gecontroleerd, uitgelegd en hergebruikt. Hiervoor zijn data science-teams afhankelijk van de machine learning-bewerkingsbenadering . Deze methodologie is geïnspireerd op DevOps (ontwikkeling en bewerkingen), de industriestandaard voor het beheren van bewerkingen voor een toepassingsontwikkelingscyclus, omdat de problemen van ontwikkelaars en gegevenswetenschappers vergelijkbaar zijn.
Azure Machine Learning
Gegevenswetenschappers kunnen machine learning DevOps beheren en uitvoeren vanuit Azure Machine Learning, een platform van Microsoft om het beheer van de levenscyclus en operationele procedures voor machine learning eenvoudiger te maken. Dergelijke hulpprogramma's helpen teams samen te werken in een gedeelde, controleerbare en veilige omgeving waar veel processen kunnen worden geoptimaliseerd via automatisering.
De levenscyclus van machine learning beheren
Azure Machine Learning ondersteunt end-to-end levenscyclusbeheer van machine learning van vooraf getrainde en aangepaste modellen. De gebruikelijke levenscyclus omvat de volgende stappen: gegevensvoorbereiding, modeltraining, modelverpakking, modelvalidatie, modelimplementatie, modelbewaking en hertraining.
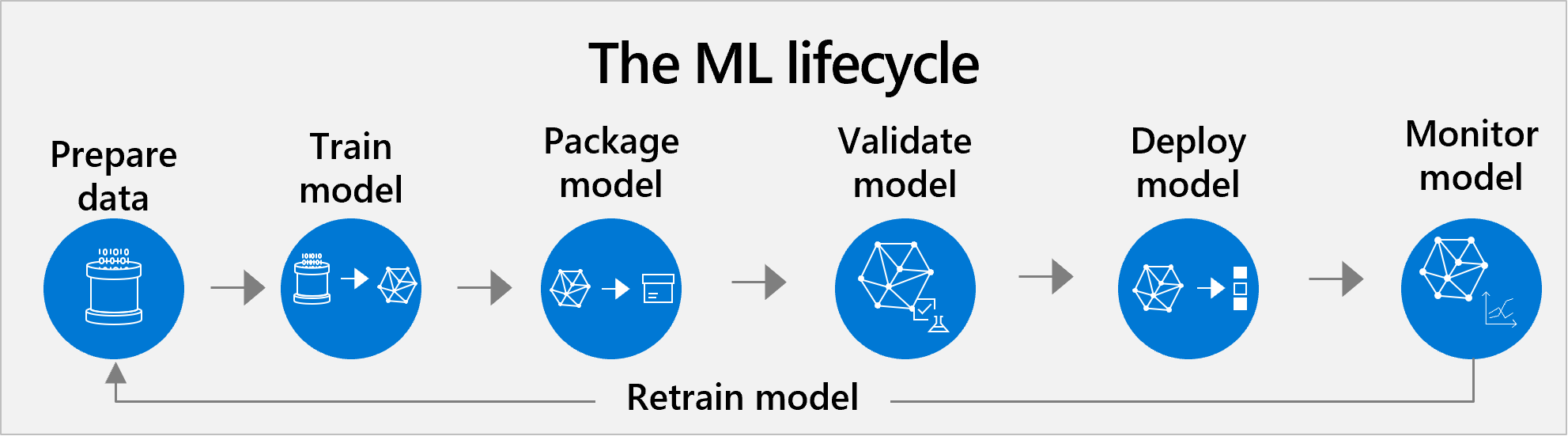
De klassieke benadering omvat alle gebruikelijke stappen van een data science-project.
- Gegevensset voorbereiden. AI begint bij gegevens. Eerst moeten gegevenswetenschappers gegevens voorbereiden waarmee het model moet worden getraind. Gegevensvoorbereiding is vaak de grootste tijdsverplichting in de levenscyclus. Deze taak omvat het zoeken of bouwen van uw eigen gegevensset en het opschonen ervan, zodat deze gemakkelijk leesbaar is door computers. U wilt ervoor zorgen dat de gegevens een representatief voorbeeld zijn, dat uw variabelen relevant zijn voor uw doel, enzovoort.
- Trainen en testen. Vervolgens passen gegevenswetenschappers algoritmen toe op de gegevens om een machine learning-model te trainen. Vervolgens testen ze deze met nieuwe gegevens om te zien hoe nauwkeurig de voorspellingen zijn.
- Pakket. Een model kan niet rechtstreeks in een app worden geplaatst. Het moet in een container worden geplaatst, zodat deze kan worden uitgevoerd met alle hulpprogramma's en frameworks waarop het is gebouwd.
- Valideer het. Op dit moment evalueert het team hoe de modelprestaties zich verhouden tot hun bedrijfsdoelen. Testen kan goed genoeg metrische gegevens retourneren, maar toch werkt het model mogelijk niet zoals verwacht wanneer het wordt gebruikt in een echt bedrijfsscenario.
- Herhaal stap 1-4. Het kan honderden trainingsuren duren om een bevredigend model te vinden. Het ontwikkelteam kan veel versies van het model trainen door trainingsgegevens aan te passen, hyperparameters van algoritmen af te stemmen of verschillende algoritmen uit te proberen. In het ideale instantie verbetert het model met elke aanpassingsronde. Uiteindelijk is het de rol van het ontwikkelingsteam om te bepalen welke versie van het model het beste past bij de business use-case.
- Deploy. Ten slotte implementeren ze het model. Opties voor implementatie zijn onder andere: in de cloud, op een on-premises server en op apparaten zoals camera's, IoT-gateways of machines.
- Bewaken en opnieuw trainen. Zelfs als een model in het begin goed werkt, moet het voortdurend worden bewaakt en opnieuw worden getraind om relevant en nauwkeurig te blijven.
Notitie
Voor het integreren van vooraf getrainde modellen en het aanpassen ervan aan uw bedrijfsbehoeften is een andere werkstroom vereist voor het integreren van aangepaste modellen. Met Azure Machine Learning kunt u vooraf getrainde modellen gebruiken of uw eigen modellen bouwen. Het kiezen van de ene benadering is afhankelijk van het scenario. Het werken met vooraf getrainde modellen heeft het voordeel dat u minder resources nodig hebt en sneller resultaten levert. Vooraf samengestelde modellen worden echter getraind om een breed scala aan gebruiksvoorbeelden op te lossen, zodat ze moeite hebben om te voldoen aan zeer specifieke behoeften. In dergelijke gevallen is een volledig aangepast model mogelijk een beter idee. Een flexibele combinatie van beide benaderingen is vaak de voorkeur en helpt bij het schalen. AI-teams kunnen resources opslaan met behulp van vooraf getrainde modellen voor de eenvoudigste gebruiksvoorbeelden, terwijl u deze resources investeert in het bouwen van aangepaste AI-modellen voor de moeilijkste scenario's. Verdere iteraties kunnen de vooraf gemaakte modellen verbeteren door ze opnieuw te trainen.
Machine learning-bewerkingen
Machine learning-bewerkingen (MLOps) passen de methodologie van DevOps (ontwikkeling en bewerkingen) toe om de levenscyclus van machine learning efficiënter te beheren. Het maakt een flexibelere, productievere samenwerking mogelijk in AI-teams tussen alle belanghebbenden. Deze samenwerkingen omvatten gegevenswetenschappers, AI-technici, app-ontwikkelaars en andere IT-teams.
MLOps-processen en -hulpprogramma's helpen deze teams samen te werken en zichtbaarheid te bieden via gedeelde, controleerbare documentatie. Met MLOps-technologieën kunnen gebruikers wijzigingen in alle resources opslaan en bijhouden, zoals gegevens, code, modellen en andere hulpprogramma's. Deze technologieën kunnen ook efficiëntie creëren en de levenscyclus versnellen met automatisering, herhaalbare werkstromen en herbruikbare assets. Al deze procedures maken AI-projecten flexibeler en efficiënter.
Azure Machine Learning ondersteunt de volgende MLOps-procedures:
Model reproduceerbaarheid: betekent dat verschillende teamleden modellen op dezelfde gegevensset kunnen uitvoeren en vergelijkbare resultaten kunnen krijgen. Reproduceerbaarheid is essentieel voor het maken van resultaten van modellen in productie betrouwbaar. Azure Machine Learning biedt ondersteuning voor modelproduceerbaarheid met centraal beheerde assets, zoals omgevingen, code, gegevenssets, modellen en machine learning-pijplijnen.
Modelvalidatie: voordat een model wordt geïmplementeerd, is het essentieel om de metrische prestatiegegevens te valideren. Mogelijk hebt u verschillende metrische gegevens die worden gebruikt om het 'beste' model aan te geven. Het valideren van metrische prestatiegegevens op manieren die relevant zijn voor de business use case is essentieel. Azure Machine Learning ondersteunt modelvalidatie met veel hulpprogramma's voor het evalueren van metrische modelgegevens, zoals verliesfuncties en verwarringsmatrixen.
Modelimplementatie: wanneer een model wordt geïmplementeerd, is het belangrijk dat gegevenswetenschappers en AI-technici samenwerken om de beste implementatieoptie te bepalen. Deze opties zijn onder andere cloud-, on-premises en edge-apparaten (camera's, drones, machines).
Modelhertraining: modellen moeten worden bewaakt en periodiek opnieuw worden getraind om prestatieproblemen op te lossen en te profiteren van nieuwere trainingsgegevens. Azure Machine Learning ondersteunt een systematisch en iteratief proces om voortdurend te verfijnen en de nauwkeurigheid van het model te garanderen.
Tip

Klantverhaal: Een gezondheidszorgorganisatie gebruikt Azure Machine Learning om aangepaste machine learning-modellen te trainen die de kans op complicaties voorspellen tijdens chirurgische procedures. De modellen worden getraind op enorme hoeveelheden gegevens, waaronder factoren zoals leeftijd, etniciteit, rookgeschiedenis, lichaamsmassa-index en bloedplaatjetelling. Met behulp van deze modellen kunnen medische professionals risico's beter beoordelen en opties bepalen voor chirurgie of levensstijlveranderingsaanbevelingen voor individuele patiënten. Het verantwoordelijke AI-dashboard in Azure Machine Learning helpt voorspellende factoren uit te leggen en de vooroordelen van demografische factoren te beperken. Uiteindelijk helpt de voorspellende modelleringsoplossing risico's en onzekerheid te verminderen en chirurgische resultaten te verbeteren. Lees hier het volledige klantverhaal: https://aka.ms/azure-ml-customer-story.
Tip
Neem even de tijd om na te gaan hoe uw organisatie gebruik kan maken van data science- en machine learning-expertise om aangepaste modellen te bouwen.

Laten we vervolgens alles inpakken met een kennistoets.