Azure Data Lake Storage Gen2 gebruiken in gegevensanalyseworkloads
Azure Data Lake Store Gen2 is een inschakelende technologie voor gebruiksscenario's voor meerdere gegevensanalyses. Laten we een paar veelvoorkomende typen analytische werkbelastingen verkennen en bepalen hoe Azure Data Lake Storage Gen2 werkt met andere Azure-services om deze te ondersteunen.
Verwerking en analyse van big data
Big data-scenario's verwijzen meestal naar analytische workloads die grote hoeveelheden gegevens bevatten in verschillendeindelingen die met een snelle snelheid moeten worden verwerkt: de zogenaamde 'drie v's'. Azure Data Lake Storage Gen 2 biedt een schaalbaar en veilig gedistribueerd gegevensarchief waarop big data-services zoals Azure Synapse Analytics, Azure Databricks en Azure HDInsight frameworks voor gegevensverwerking kunnen toepassen, zoals Apache Spark, Hive en Hadoop. Dankzij de gedistribueerde aard van de opslag en de verwerkingsreken kunnen taken parallel worden uitgevoerd, wat resulteert in hoge prestaties en schaalbaarheid, zelfs wanneer grote hoeveelheden gegevens worden verwerkt.
Datawarehousing
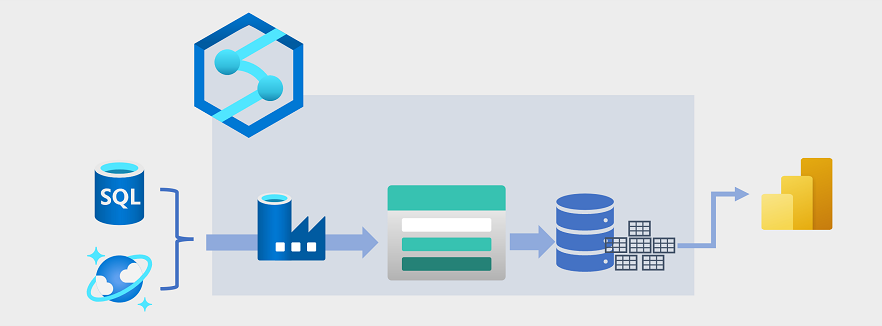
Datawarehousing is de afgelopen jaren ontwikkeld om grote hoeveelheden gegevens te integreren die zijn opgeslagen als bestanden in een data lake met relationele tabellen in een datawarehouse. In een typisch voorbeeld van een oplossing voor datawarehousing worden gegevens geëxtraheerd uit operationele gegevensarchieven, zoals Azure SQL-database of Azure Cosmos DB, en getransformeerd in structuren die geschikter zijn voor analytische workloads. Vaak worden de gegevens gefaseerd in een data lake om gedistribueerde verwerking te vergemakkelijken voordat ze in een relationeel datawarehouse worden geladen. In sommige gevallen maakt het datawarehouse gebruik van externe tabellen om een relationele metagegevenslaag te definiëren over bestanden in de data lake en een hybride data lakehouse- of lake-databasearchitectuur te maken. Het datawarehouse kan vervolgens analytische query's ondersteunen voor rapportage en visualisatie.
Er zijn meerdere manieren om dit soort datawarehousingarchitectuur te implementeren. In het diagram ziet u een oplossing waarin Azure Synapse Analytics pijplijnen host om ETL-processen (extract, transform, and load) uit te voeren met behulp van Azure Data Factory-technologie. Met deze processen worden gegevens uit operationele gegevensbronnen geëxtraheerd en geladen in een data lake die wordt gehost in een Azure Data Lake Storage Gen2-container. De gegevens worden vervolgens verwerkt en geladen in een relationeel datawarehouse in een toegewezen SQL-pool van Azure Synapse Analytics, waar ze gegevensvisualisatie en -rapportage kunnen ondersteunen met Behulp van Microsoft Power BI.
Realtime gegevensanalyse
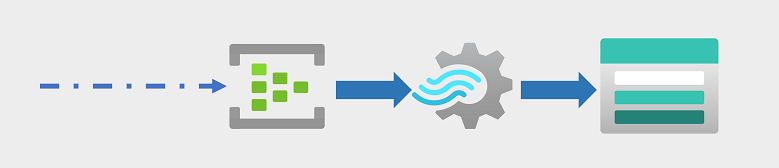
Steeds vaker moeten bedrijven en andere organisaties eeuwigdurende gegevensstromen vastleggen en analyseren en deze in realtime analyseren (of zo dicht mogelijk bij realtime). Deze gegevensstromen kunnen worden gegenereerd op basis van verbonden apparaten (vaak internet-of-things- of IoT-apparaten genoemd) of van gegevens die zijn gegenereerd door gebruikers in sociale mediaplatforms of andere toepassingen. In tegenstelling tot traditionele werkbelastingen voor batchverwerking is voor streaminggegevens een oplossing vereist waarmee een grenzeloze stroom gegevensgebeurtenissen kan worden vastgelegd en verwerkt wanneer deze zich voordoen.
Streaming-gebeurtenissen worden vaak vastgelegd in een wachtrij voor verwerking. Er zijn meerdere technologieën die u kunt gebruiken om deze taak uit te voeren, waaronder Azure Event Hubs, zoals wordt weergegeven in de afbeelding. Van hieruit worden de gegevens verwerkt, vaak om gegevens over tijdelijke vensters te aggregeren (bijvoorbeeld om het aantal sociale mediaberichten met een bepaalde tag om de vijf minuten te tellen of om het gemiddelde lezen van een sensor met internetverbinding per minuut te berekenen). Met Azure Stream Analytics kunt u taken maken waarmee query's worden uitgevoerd en gebeurtenisgegevens worden samengevoegd zodra deze binnenkomen en de resultaten in een uitvoersink schrijven. Een dergelijke sink is Azure Data Lake Storage Gen2; van waaruit de vastgelegde realtime gegevens kunnen worden geanalyseerd en gevisualiseerd.
Gegevenswetenschap en machine learning

Gegevenswetenschap omvat de statistische analyse van grote hoeveelheden gegevens, vaak met behulp van hulpprogramma's zoals Apache Spark en scripttalen zoals Python. Azure Data Lake Storage Gen 2 biedt een zeer schaalbaar gegevensarchief in de cloud voor de volumes gegevens die nodig zijn voor data science-workloads.
Machine learning is een subgebied van gegevenswetenschap dat betrekking heeft op het trainen van voorspellende modellen. Modeltraining vereist enorme hoeveelheden gegevens en de mogelijkheid om die gegevens efficiënt te verwerken. Azure Machine Learning is een cloudservice waarin gegevenswetenschappers Python-code in notebooks kunnen uitvoeren met behulp van dynamisch toegewezen gedistribueerde rekenresources. De rekenproces verwerkt gegevens in Azure Data Lake Storage Gen2-containers om modellen te trainen, die vervolgens kunnen worden geïmplementeerd als productiewebservices ter ondersteuning van voorspellende analytische workloads.