Hoe Azure HDInsight werkt
Hier leert u hoe Azure HDInsight werkt. U vindt meer informatie over de volgende onderdelen en hoe ze bij elkaar passen om gegevensbeheer en -beheer te bieden:
- Apache Hadoop
- HDInsight-opslag
- HDInsight-verwerking
Wat is Apache Hadoop?
Apache Hadoop is een in de cloud gedistribueerd systeem voor gegevensverwerking in de kern van HDInsight. Het bevat drie onderdelen, die in de volgende tabel worden beschreven:
| Apache Hadoop-onderdeel | Beschrijving |
|---|---|
| HDFS | Het Apache Hadoop Distributed File System (HDFS) biedt opslag voor het Hadoop-systeem. |
| GAREN | Het Yarn-onderdeel (Apache Hadoop Yet Another Resource Negotiator) biedt verwerking voor het systeem. |
| MapReduce | MapReduce is een programmeermodel waarmee u gegevens kunt verwerken en analyseren. |
Hoe werken de onderdelen?
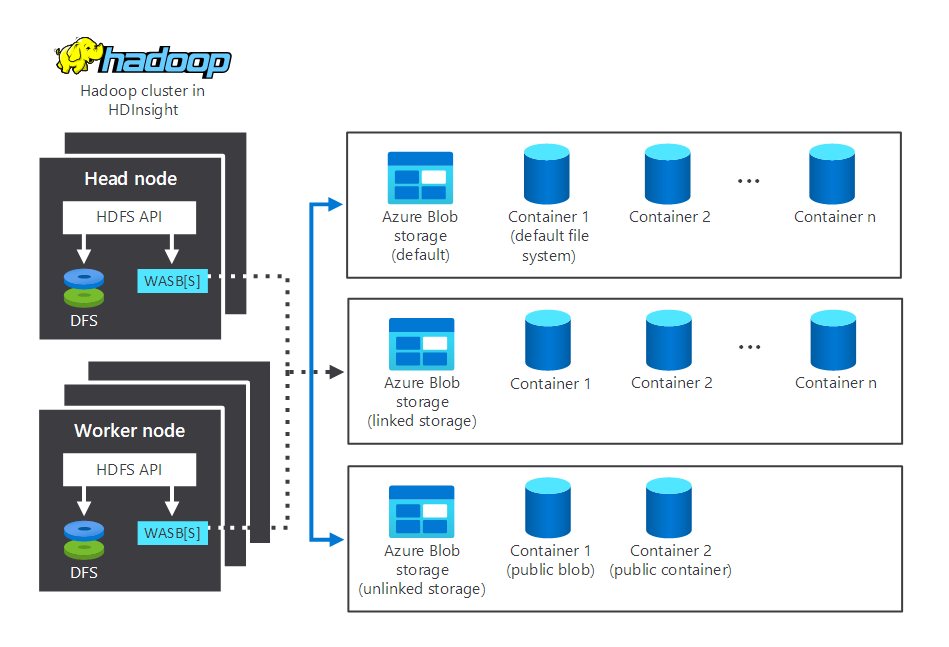
In het volgende diagram ziet u opslag- en verwerkingsonderdelen die communiceren in een typisch HDInsight Hadoop-cluster. Het illustreert de volgende onderdelen:
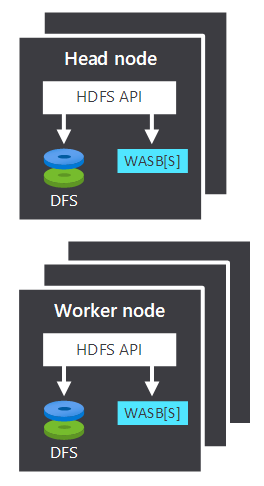
- Het hoofdknooppunt en de werkknooppunten, die de verwerking uitvoeren.
- Meerdere Opslagcentra van Windows Azure Storage Blob (WASB) binnen de knooppunten. HDFS communiceert met deze containers.
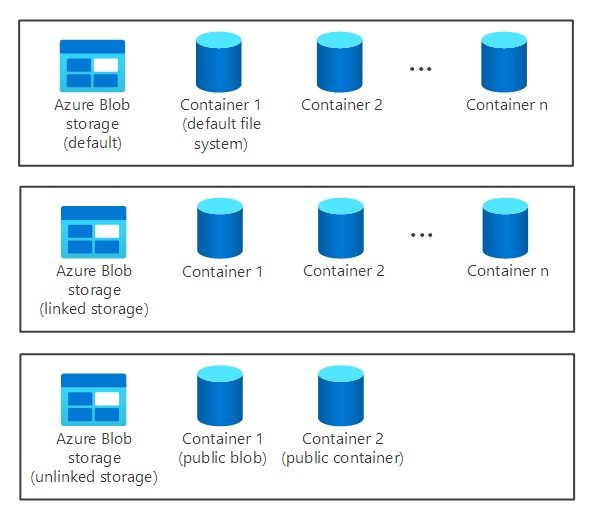
- Meerdere standaard-, gekoppelde en niet-gekoppelde opslagcontainers. Deze zijn beschikbaar voor de twee knooppunten.
Laten we nu eens kijken hoe opslag en verwerking werken.
Hoe werkt opslag?
Het opslagonderdeel van een cluster wordt niet automatisch gemaakt wanneer u een HDInsight-cluster inricht. In plaats daarvan wordt het geleverd door een HDFS-compatibel systeem, zoals Azure Storage of Azure Data Lake.
Er zijn voordelen bij het scheiden van het opslagonderdeel van een cluster van het verwerkingsonderdeel. U kunt bijvoorbeeld alle HDInsight-clusters die alleen worden gebruikt voor berekeningen veilig verwijderen zonder dat u zich zorgen hoeft te maken over het verlies van gegevens. Wanneer u een HDInsight-cluster toevoegt, moet u een standaardbestandssysteem definiëren.
Belangrijk
Voor Azure Storage moet u een blobcontainer opgeven als het standaardbestandssysteem.
Door een standaardbestandssysteem op te geven, zorgt u ervoor dat HDInsight relatieve bestandsverwijzingen kan oplossen bij het zoeken naar bestanden.
Tip
Als u de beschikbare opslag wilt vergroten, kunt u indien nodig extra bestandssystemen koppelen en ontkoppelen.
Hoe werkt de verwerking?
Bij het verwerken van gegevens wordt het rekenonderdeel van een Hadoop-cluster in HDInsight opgesplitst in twee logische gebieden. In de volgende tabel worden deze twee gebieden beschreven:
| Bestanddeel | Beschrijving |
|---|---|
| Hoofdknooppunt | Het hoofdknooppunt accepteert en beheert clientaanvragen en geeft de aanvragen door aan de werkknooppunten. |
| Werkknooppunt | De werkknooppunten verwerken gegevens. |
Notitie
Het hoofdknooppunt wordt soms een meesterknooppunt genoemd.
De meeste clusters bevatten twee hoofdknooppunten, waaronder:
- Een actief hoofdknooppunt, waarmee clientverbindingen worden beheerd.
- Een passief hoofdknooppunt, dat flexibiliteit biedt als het actieve knooppunt offline gaat.
Zowel de hoofd- als werkknooppunten kunnen rechtstreeks verbinding maken met een lokaal gekoppelde HDFS of toegang krijgen tot gegevens die zijn opgeslagen in Azure Blob of Azure Data Lake. Welke gegevens worden beheerd, is afhankelijk van twee factoren:
- Hoe het MapReduce-programmeermodel heeft gedefinieerd hoe de gegevens moeten worden gebruikt
- Hoe het hoofdknooppunt het werk toewijst
Wat doet YARN?
Het YARN voert resourcebeheer uit binnen een HDInsight-cluster. Wanneer u gegevens verwerkt, beheert deze service middelen en taakverdeling.
YARN bevindt zich tussen de HDFS en het rekensysteem van het HDInsight-cluster. Het werkt met het hoofdknooppunt om een taak te verdelen over de werkknooppunten van het cluster. Dit helpt ervoor te zorgen dat de gegevensverwerkingstaken parallel plaatsvinden.