Wat is Azure HDInsight?
Laten we de functies en het gebruik van HDInsight bekijken. Dit overzicht helpt u te evalueren of HDInsight voldoet aan de vereisten van uw organisatie.
What is big data? (Wat is big data?)
De term big data beschrijft de grote hoeveelheden gestructureerde en ongestructureerde gegevens die organisaties verzamelen. Deze gegevens kunnen zeer nuttig zijn voor organisaties. Als een organisatie de gegevens voor inzichten kan analyseren, is het beter in staat om beslissingen te nemen. Het resultaat is dat deze beslissingen een organisatie kunnen helpen succesvoller te worden. Met big data-analyse kan een commerciële organisatie bijvoorbeeld klantgewoonten herkennen, wat kan leiden tot een grotere verkoop.
Azure HDInsight-definitie
Azure HDInsight is een volledig beheerde opensource-analyseservice in de cloud voor ondernemingen. Met HDInsight kunt u uw big data beheren en beheren. HDInsight:
Is een clouddistributie van Hadoop-onderdelen.
Maakt het eenvoudiger, sneller en rendabeler om enorme hoeveelheden gegevens te verwerken.
Ondersteunt het gebruik van opensource-frameworks, zoals:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Notitie
Met deze kaders kunt u ook een breed scala aan scenario's inschakelen, zoals extraheren, transformeren en laden (ETL), gegevensopslag, machine learning en IoT.
HDInsight biedt verschillende voordelen voor organisaties die werken met big data. T is:
Opensource: hiermee kunt u geoptimaliseerde clusters maken voor verschillende opensource-frameworks.
Betrouwbaar: biedt een end-to-end SLA voor alle productieworkloads.
Schaalbaar: Hiermee kunt u workloads schalen om te reageren op wijzigingen in de vraag.
Tip
Door clusters op aanvraag te maken, kunt u uw kosten verlagen. U betaalt alleen voor wat u gebruikt.
Beveiligd: Hiermee kunt u uw zakelijke gegevensassets beveiligen via integratie met:
- Azure Virtual Network
- Versleutelingstechnologieën van Azure
- Microsoft Entra ID
Compatibel: voldoet aan populaire industrie- en overheidsnalevingsstandaarden.
Bewaakt: integreert met Azure Monitor-logboeken om één interface te bieden. Bewaak alle clusters met behulp van de enkele interface.
Hoe HDInsight u kan helpen met big data te werken
U kunt HDInsight gebruiken voor veel scenario's die gebruikmaken van verwerking van big data. Uw gegevens kunnen het volgende zijn:
- Historische gegevens: deze gegevens worden al verzameld en opgeslagen.
- Realtime gegevens: deze gegevens worden rechtstreeks vanuit de bron gestreamd.
In de volgende categorieën worden de verwerkingsscenario's voor deze gegevens samengevat:
- Batchverwerking
- Datawarehousing
- IoT
- Data Science
- Hybride
Laten we deze categorieën nader bekijken.
Batchverwerking
Organisaties gebruiken batchverwerkingstaken om big data voor te bereiden voor verdere analyse. Dit proces bestaat doorgaans uit drie fasen:
- Brongegevensbestanden lezen uit heterogene gegevensbronnen.
- De gegevens verwerken.
- De gegevens naar schaalbare opslag schrijven.
Notitie
Dit proces wordt vaak ETL genoemd.
U kunt de getransformeerde gegevens gebruiken voor datawarehousing of data science.
Tip
Een belangrijke vereiste voor ETL is uitschalen van rekenkracht. Hierdoor kunnen grote gegevensvolumes worden verwerkt.
Datawarehousing
Een datawarehouse biedt een organisatie ergens om big data op te slaan terwijl u wacht om deze te analyseren. Met datawarehousing kunt u het volgende doen:
- Sla uw gegevens op.
- Bereid uw gegevens voor op analyse.
- Geef de voorbereide gegevens op in een gestructureerde indeling. Vervolgens kunt u query's uitvoeren op de gegevens met behulp van analytische hulpprogramma's.
In het volgende diagram ziet u hoe Apache Hadoop in HDInsight gegevens uit verschillende bronnen verzamelt en opslaat. Apache Spark en Apache Hive bereiden de gegevens voor en analyseren. Ten slotte worden de gegevens gemodelleerd voor gebruik met BI-hulpprogramma's (Business Intelligence). Power BI wordt gebruikt voor gegevensvisualisatie.
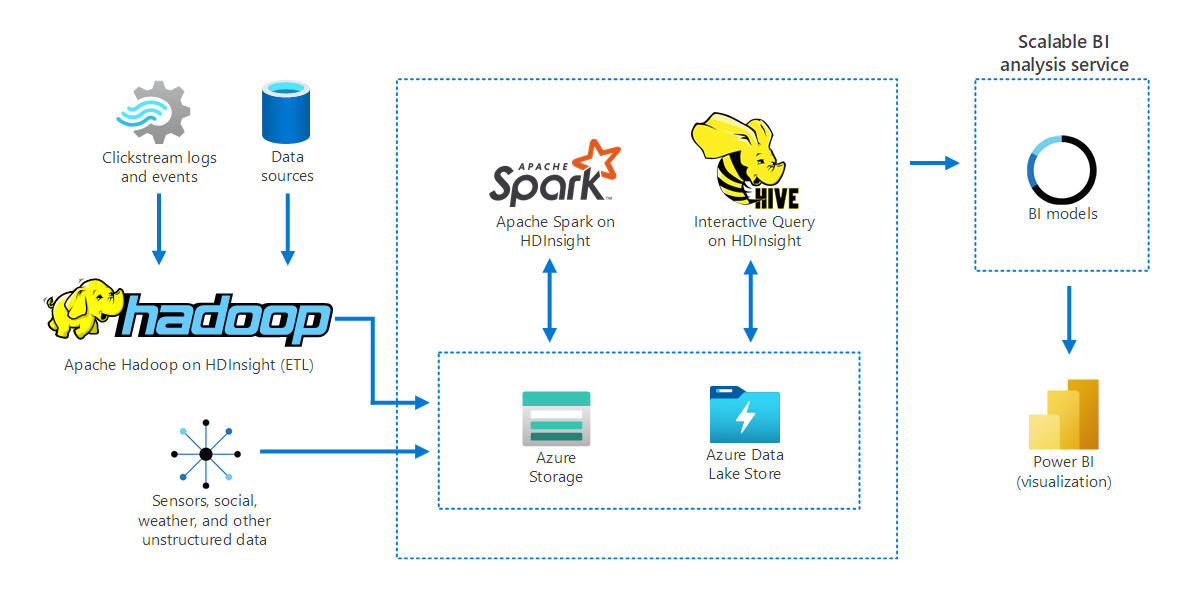
Onderdelen in dit scenario zijn onder andere:
- Apache Spark is een framework voor parallelle verwerking. Het biedt ondersteuning voor in-memory verwerking, waardoor de prestaties van analysetoepassingen voor big data worden verbeterd.
- Apache Hive in HDInsight is een datawarehousesysteem voor Apache Hadoop. Hive maakt het mogelijk om gegevenssamenvatting, query's en analyses uit te voeren. U kunt deze onderdelen gebruiken om query's uit te voeren op petabyte-schaalaanpassingen op gestructureerde en ongestructureerde gegevens, in elke indeling.
Tip
Hive-query's worden geschreven in HiveQL, een querytaal die vergelijkbaar is met SQL.
Internet of things
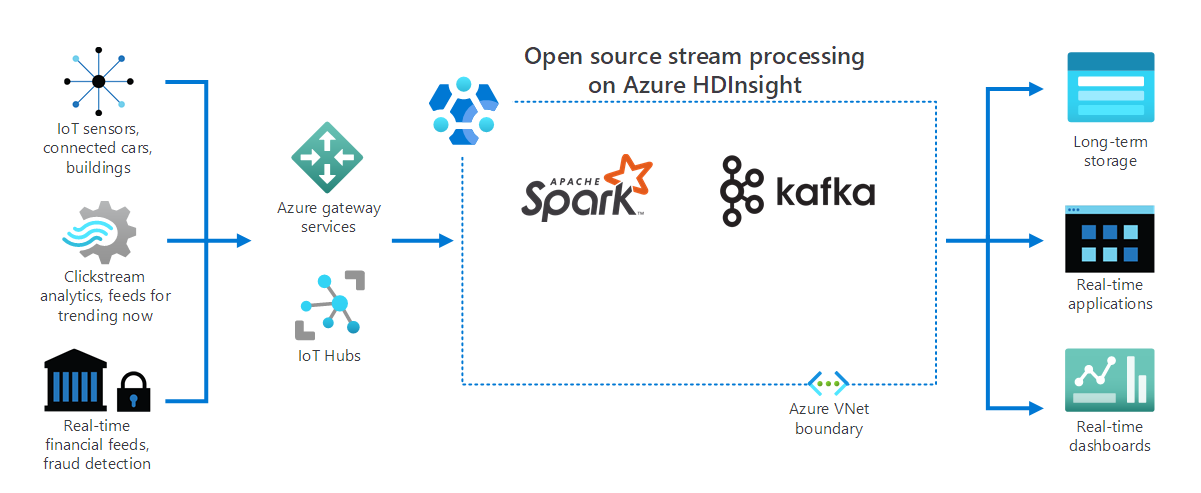
Zoals in het volgende diagram wordt weergegeven, verwerkt HDInsight streaminggegevens die in realtime worden ontvangen van verschillende apparaten en sensoren. In dit voorbeeld bieden verschillende opensource-frameworks stroomverwerking, waaronder Apache Spark en Apache Kafka.
Azure Gateway-services en IoT-hubs leiden gegevens van verschillende bronnen naar deze frameworks. De frameworks verwerken vervolgens de gegevens en worden doorgegeven aan:
- Langetermijnopslag.
- Realtime-apps.
- Realtime dashboards.
Data Science
U kunt HDInsight gebruiken om algemene gegevenswetenschapstaken te voltooien, zoals:
- Gegevensopname.
- Functie-engineering.
- Modeling.
- Modelevaluatie.
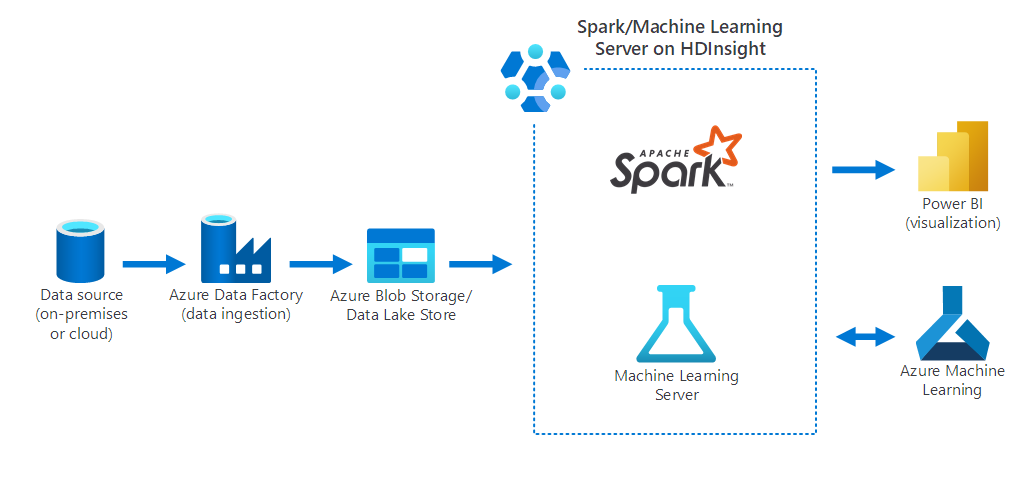
In het volgende diagram ziet u een data science-scenario waarin:
- Gegevens worden verzameld uit een on-premises gegevensbron met behulp van Azure Data Factory.
- De opgenomen gegevens worden vervolgens opgeslagen in Azure Storage (Azure Blob Storage of een Data Lake Store).
- Azure Spark in HDInsight verwerkt en bereidt de gegevens voor op Azure Machine Learning. Gegevens worden ook gevisualiseerd met behulp van Power BI.
Hybride
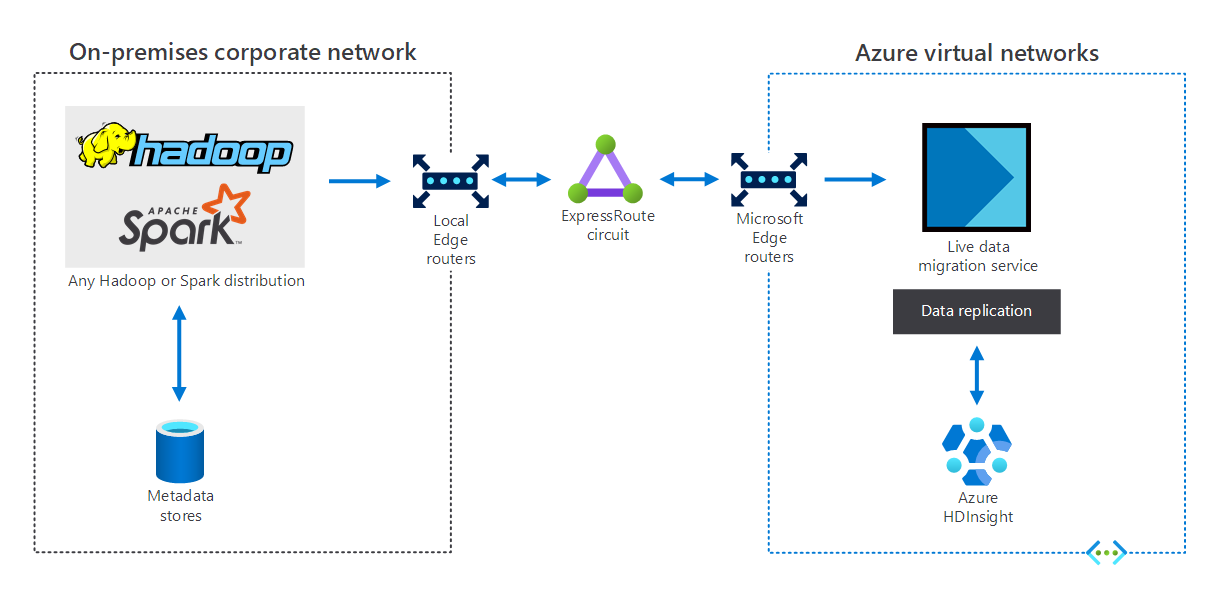
Organisaties met een on-premises big data-infrastructuur kunnen HDInsight gebruiken om uit te breiden naar Azure. Dit biedt u de voordelen van de geavanceerde analysemogelijkheden van de Azure-cloud. In het volgende diagram ziet u het hybride scenario, waarin:
- De on-premises big data-infrastructuur bestaat uit metagegevensarchieven en een Hadoop- of Spark-distributie op lokale VM's.
- Een Azure ExpressRoute-circuit verbindt de on-premises bedrijfsnetwerkomgeving met virtuele Azure-netwerken.
- Een live gegevensmigratie voor Azure repliceert de gegevens die van on-premises naar HDInsight zijn ontvangen.