Hoe Azure Data Explorer werkt
In deze les kijken we hoe Azure Data Explorer achter de schermen werkt door de belangrijkste onderdelen van het systeem te bespreken. Vervolgens leert u hoe u met de service kunt werken door een algemene werkstroom te verkennen:
- Gegevensopname
- Kusto-querytaal
- Gegevensvisualisatie
Met deze kennis kunt u bepalen of Azure Data Explorer geschikt is voor uw gegevensbehoeften.
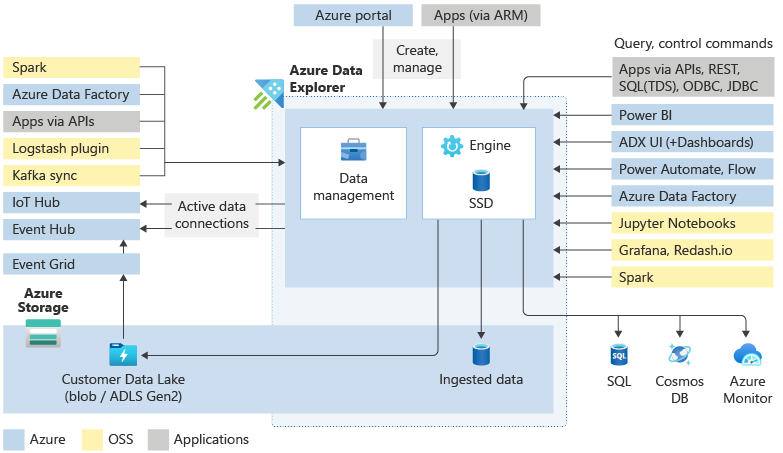
Belangrijke onderdelen
Een Azure Data Explorer-cluster doet al het werk om uw gegevens op te nemen, te verwerken en er query's op uit te voeren. De clusters zijn automatisch schaalbaar volgens uw behoeften. Azure Data Explorer slaat ook de gegevens op in Azure Storage en slaat enkele van deze gegevens op de rekenknooppunten van het cluster in de cache op om optimale queryprestaties te bereiken.
Wat bevindt zich in een Azure Data Explorer-cluster?
Elk Azure Data Explorer-cluster kan maximaal 10.000 databases en elke database maximaal 10.000 tabellen bevatten. De gegevens in elke tabel worden opgeslagen in gegevensshards, ook wel gebieden genoemd. Alle gegevens worden automatisch geïndexeerd en gepartitioneerd op basis van de opnametijd. In tegenstelling tot een relationele database zijn er geen beperkingen voor primaire refererende sleutels of andere beperkingen, zoals uniekheid. Dit ontwerp betekent dat u grote hoeveelheden gevarieerde gegevens kunt opslaan. En vanwege de manier waarop het wordt opgeslagen, krijgt u snel toegang tot het uitvoeren van query's.
De logische structuur van een database is vergelijkbaar met veel andere relationele databases. Een Azure Data Explorer-database kan het volgende bevatten:
- Tabellen: Bestaat uit een set kolommen. Elke kolom heeft een van negen verschillende gegevenstypen.
- Externe tabellen: tabellen waarvan de onderliggende opslag zich op andere locaties bevindt, zoals Azure Data Lake.
Kennismaken met de algemene werkstroom
Over het algemeen gaat u, wanneer u met Azure Data Explorer werkt, door de volgende werkstroom: Eerst neemt u uw gegevens op om deze in het systeem op te halen. Vervolgens analyseert u uw gegevens. Vervolgens visualiseert u de resultaten van uw analyse. U kunt op elk gewenst moment ook contact opnemen met de functies voor gegevensbeheer. Dit werk met Azure Data Explorer wordt uitgevoerd via interactie met het cluster. U hebt toegang tot deze resources in de webgebruikersinterface of via SDK's.
Hoe kan ik mijn gegevens ophalen in Azure Data Explorer?
Gegevensopname is het proces dat wordt gebruikt voor het laden van gegevensrecords uit een of meer bronnen in een tabel in Azure Data Explorer. Verdere gegevensmanipulatie omvat het overeenkomende schema, organiseren, indexeren, coderen en comprimeren van de gegevens. Data Manager voert vervolgens de gegevensopname door naar de engine, waar deze beschikbaar is voor query's.
Naast de systeemeigen wizard webgebruikersinterface zijn er verschillende opnamehulpprogramma's beschikbaar. Inclusief de beheerde pijplijnen, Event Grid, IoT Hub en Azure Data Factory. U kunt connectors en invoegtoepassingen gebruiken, zoals de Logstash-invoegtoepassing, De Kafka-connector, Power Automate en de Apache Spark-connector. U kunt ook programmatische opname gebruiken met SDK's of LightIngest.
Gegevens kunnen in twee modi worden opgenomen: Batching of Streaming. Batchopname is geoptimaliseerd voor een hoge opnamedoorvoer en snelle queryresultaten. Streamingopname maakt bijna realtime latentie mogelijk voor kleine gegevenssets per tabel.
Hoe kan ik mijn gegevens analyseren?
Azure Data Explorer maakt gebruik van de eigen Kusto-querytaal (KQL) om gegevens te analyseren. Het wordt veel gebruikt in Microsoft (Azure Monitor - Log Analytics en Application Insights, Microsoft Sentinel en Microsoft Defender XDR). KQL is geoptimaliseerd voor snelstromen, diverse big data-verkenning. Query's verwijzen naar tabellen, weergaven, functies en andere tabellaire expressies. Tabellen opnemen in verschillende databases of zelfs clusters. Query's kunnen worden uitgevoerd met behulp van de webgebruikersinterface, verschillende queryhulpprogramma's of met een van de Azure Data Explorer SDK's.
Hoe werkt de Kusto-querytaal?
Kusto-querytaal is een expressieve, intuïtieve en zeer productieve querytaal. Het biedt een soepele overgang van eenvoudige one-liners naar complexe gegevensverwerkingsscripts en biedt ondersteuning voor het uitvoeren van query's op gestructureerde, semi-gestructureerde en ongestructureerde (tekstzoekopdrachten). Er is een groot aantal operatoren en functies voor querytaal (aggregatie, filteren, tijdreeksfuncties, georuimtelijke functies, joins, samenvoegingen en meer) in de taal. KQL biedt ondersteuning voor query's voor meerdere clusters en databases en is voorzien van een parseringsperspectief (json, XML, enzovoort). Daarnaast biedt de taal systeemeigen ondersteuning voor geavanceerde analyses.
Hoe kan ik mijn queryresultaten weergeven?
De webgebruikersinterface van Azure Data Explorer is ontworpen met big data in het achterhoofd, zodat u query's kunt uitvoeren en dashboards kunt bouwen. Het ondersteunt een weergave van maximaal 500 K records en duizenden kolommen. Het is zeer schaalbaar en rijk aan functionaliteit waarmee u snelle inzichten kunt trekken uit uw gegevens. U kunt ook verschillende visuele weergaven van uw gegevens gebruiken in uw Azure Data Explorer-dashboards. U kunt uw resultaten ook weergeven met behulp van systeemeigen connectors voor enkele van de toonaangevende visualisatieservices die momenteel beschikbaar zijn, zoals Power BI en Grafana. Azure Data Explorer biedt ook ondersteuning voor ODBC- en JDBC-connectoren voor hulpprogramma's zoals Tableau en Qlik.
Hoe kan ik mijn gegevens beheren?
Beheerders willen verschillende onderhouds- en beleidstaken uitvoeren op hun Azure Data Explorer-clusters en besturingsopdrachten bieden hen de mogelijkheid om dit te doen. Met behulp van besturingsopdrachten kunnen ze nieuwe clusters of databases maken, gegevensverbindingen tot stand brengen, automatisch schalen uitvoeren en clusterconfiguraties aanpassen. Ze kunnen ook entiteiten, metagegevensobjecten, machtigingen en beveiligingsbeleid beheren en beheren. Daarnaast kunnen ze gerealiseerde weergaven wijzigen (voortdurend gefilterde weergaven van andere tabellen), functies (opgeslagen functies en door de gebruiker gedefinieerde functies) en het updatebeleid (functies die worden geactiveerd na opname).
Besturingsopdrachten worden rechtstreeks op de engine uitgevoerd met behulp van de WebUI, Azure Portal, verschillende queryhulpprogramma's of een van de Azure Data Explorer SDK's.