Testautomatisering en de leveringspijplijn
U hebt geleerd over continue implementatie en levering van software en services, maar de twee maken eigenlijk deel uit van een triad. DevOps-methoden zijn gericht op het bereiken van continue integratie, implementatie en levering.
Nu is het tijd om een back-up te maken van de eerste van deze: integratie. Dit maakt deel uit van het ontwikkelingsproces dat voor de implementatie plaatsvindt. DevOps beveelt een ontwikkelingsprocedure aan waarbij teamleden code vaak integreren in een gedeelde opslagplaats met een enkelvoudige 'main'- of 'trunk'-codebasis. Het doel is dat iedereen bijdraagt aan de code die wordt verzonden in plaats van aan hun eigen kopie te werken en alles op het laatste moment samen te voegen.
Geautomatiseerde tests kunnen vervolgens de integratie van elk teamlid verifiëren. Deze tests helpen na elke wijziging en toevoeging vast te stellen of de code in orde is. Het testen maakt deel uit van wat we een pijplijn noemen. We praten over pijplijnen in slechts een ogenblik, omdat deze eenheid zich richt op geïntegreerde test- en leveringspijplijnen.
De doorlopende leveringspijplijn
Als u de rol van geautomatiseerde tests in het implementatiemodel voor continue levering wilt begrijpen, moet u kijken waar deze in de leveringspijplijn past. Een doorlopende leveringspijplijn is de implementatie van de reeks stappen die code doorloopt wanneer er wijzigingen worden ingevoerd tijdens het ontwikkelingsproces voordat de code wordt geïmplementeerd in de productieomgeving. Hier volgt een grafische weergave van voorbeeldstappen in een vereenvoudigde leveringspijplijn:
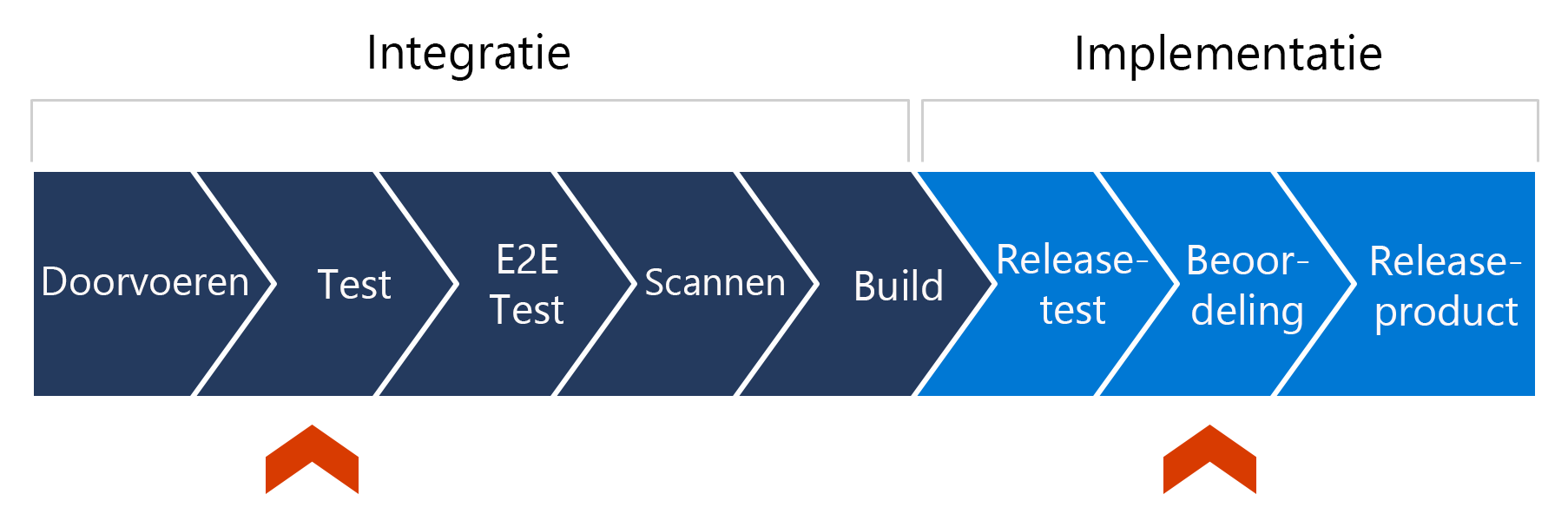
Laten we deze pijplijn stap voor stap doorlopen.
Een exemplaar van de pijplijn start wanneer code- of infrastructuurwijzigingen worden doorgevoerd in een code-opslagplaats, mogelijk door middel van een pull-aanvraag.
Vervolgens worden eenheidstests uitgevoerd( mogelijk integratie of end-to-end tests) en worden deze testresultaten idealiter teruggestuurd naar de aanvragende partij.
Misschien wordt de code in de opslagplaats gescand op geheimen, beveiligingsproblemen en aspecten van de configuratie.
Wanneer alles in orde is, wordt de code gebouwd en voorbereid voor implementatie.
Vervolgens wordt de code geïmplementeerd in een testomgeving. Een persoon kan op de hoogte worden gesteld van de nieuwe implementatie en worden verzocht om de pre-productieoplossing te bekijken. Deze persoon kan vervolgens de implementatie voor productie goedkeuren of afwijzen, waardoor het laatste deel van het implementatieproces wordt gestart waarbij de code wordt vrijgegeven voor productie.
In deze pijplijn kunt u de afbakening tussen integratie en implementatie noteren. De rode markeringen geven een aantal logische posities aan waar u de pijplijn kunt stoppen via opgenomen logica en automatisering of mogelijk zelfs door tussenkomst van een persoon.
Hulpprogramma's voor continue integratie en levering: Azure Pipelines
Als u continue integratie en continue levering wilt gebruiken, hebt u de juiste hulpprogramma’s nodig. Azure Pipelines maakt deel uit van Azure DevOps-services die u kunt gebruiken om uw code automatisch te bouwen en consistent te testen. U kunt ook Azure Pipelines gebruiken om de code in Azure-services, virtuele machines en andere doelen in zowel de cloud als on-premises te implementeren.
De invoer voor een pijplijn (onze code of configuraties) bevindt zich in een versiebeheersysteem, zoals GitHub of een andere Git-provider.
Azure Pipelines wordt uitgevoerd in een deel van het rekenproces, zoals een virtuele machine of een container, en biedt build-agents die waarop Windows, Linux en macOS worden uitgevoerd. Het biedt ook integratie met invoegtoepassingen voor testen, beveiliging en codekwaliteit. Ten slotte is het eenvoudig uit te breidbaar, zodat u uw eigen automatisering kunt overbrengen naar Azure Pipelines.
Pijplijnen worden gedefinieerd met behulp van de YAML-syntaxis of via de klassieke gebruikersinterface in Azure Portal. Wanneer u een YAML-bestand gebruikt, kunt u dat bestand naast uw code opslaan. Pijplijnen bieden ook sjablonen die u kunt gebruiken om eenvoudig pijplijnen te maken; Bijvoorbeeld een pijplijn waarmee een Docker-installatiekopieën of een Node.js project wordt gebouwd. U kunt ook een bestaand YAML-bestand opnieuw gebruiken.
Dit zijn de basisstappen, ongeacht of u een YAML-bestand of de klassieke interface gebruikt:
- Configureer Azure Pipelines voor het gebruik van uw Git-opslagplaats.
- Definieer uw build door het azure-pipelines.yml bestand te bewerken of door de klassieke editor te gebruiken.
- Push uw code naar uw opslagplaats voor versiebeheer. Met deze actie wordt de pijplijn geactiveerd om uw code te bouwen en te testen.
Zodra de code is bijgewerkt, gebouwd en getest, kunt u deze implementeren op elk gewenst doel.
Er zijn enkele functies (zoals het uitvoeren van containertaken) die alleen beschikbaar zijn bij het gebruik van YAML en andere (zoals taakgroepen) die alleen beschikbaar zijn via de klassieke interface.
Constructie van Azure Pipeline
Pijplijnen worden onderverdeeld in:
Taken: Een taak is een groepering van taken of stappen die worden uitgevoerd op één buildagent. Een taak is het kleinste onderdeel van het werk dat u kunt plannen om uit te voeren. Alle stappen in een taak worden opeenvolgend uitgevoerd. Deze stappen kunnen elke gewenste actie zijn, waaronder het bouwen/compileren van software, het voorbereiden van voorbeeldgegevens voor testen, het uitvoeren van specifieke tests, enzovoort.
Fasen: Een fase is een logische groepering van gerelateerde taken.
Elke pijplijn heeft ten minste één fase. Gebruik meerdere fasen om de pijplijn in te delen in grote afdelingen en markeer de punten in uw pijplijn waar u kunt onderbreken en controles kunt uitvoeren.
Pijplijnen kunnen zo eenvoudig of complex zijn als gewenst. Er zijn uitstekende zelfstudies over het bouwen van pijplijnen en het gebruik in de build-toepassingen met azure DevOps-leertraject .
Traceerbaarheid van de omgeving
Er is nog een ander aspect van pijplijnen met betrekking tot betrouwbaarheid die het vermelden waard zijn. U kunt uw pijplijnen zo samenstellen dat het mogelijk is om te correleren wat in productie wordt uitgevoerd met een specifiek build-exemplaar. In het ideale geval moeten we een build kunnen traceren naar een specifieke pull-aanvraag of codewijziging. Dit kan enorm nuttig zijn, tijdens een incident of later tijdens de incidentbeoordeling wanneer u probeert te identificeren welke wijziging heeft bijgedragen aan een probleem. Met sommige CI/CD-systemen (zoals Azure Pipelines) kunt u dit eenvoudig doen, terwijl voor andere systemen handmatig een pijplijn moet worden gemaakt die een soort 'build-id' doorgeeft in alle fasen.