Kleine opzoekentiteiten modelleren
Ons gegevensmodel bevat twee kleine referentiegegevensentiteiten en ProductCategory ProductTag. Deze entiteiten worden gebruikt voor referentiewaarden en zijn gerelateerd aan andere entiteiten, hoewel een 1:Many relationship.
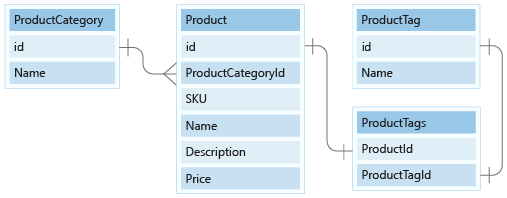
In deze les modelleren we de ProductCategory en ProductTag entiteiten in ons documentmodel.
Productcategorieën modelleren
Ten eerste voor categorieën modelleren we de gegevens met de bijbehorende id - en naamkolommen als de enige eigenschappen en plaatsen we deze in een nieuwe container met de naam ProductCategory.
Vervolgens moeten we een partitiesleutel kiezen. Laten we de bewerkingen verkennen die we op deze gegevens moeten uitvoeren.
We maken een nieuwe productcategorie, bewerken een productcategorie en vermelden vervolgens alle productcategorieën. Het maken en bewerken van productcategorieën zijn niet vaak uitgevoerde bewerkingen. Onze e-commercetoepassing vermeldt vaak alle productcategorieën wanneer klanten de website bezoeken. De laatste bewerking is dus degene die we het meest uitvoeren.
De query voor deze laatste bewerking ziet er als volgt uit: SELECT * FROM c.
Met id als de geselecteerde partitiesleutel wordt deze query nu kruislings gepartitioneert, zelfs als we willen proberen deze leesintensieve bewerkingen te optimaliseren, gebruiken we slechts één partitie, indien mogelijk. We weten ook dat de gegevens voor productcategorie nooit groter worden dan 20 GB, dus hoe zou deze informatie ons helpen bij het modelleren van de gegevens op een manier die tot één partitiequery leidt wanneer we alle productcategorieën vermelden.
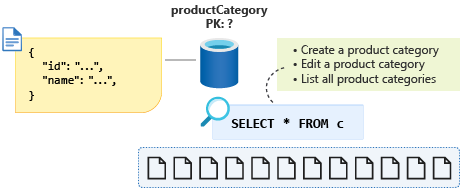
Om deze kleine hoeveelheid gegevens terug te dwingen in één partitie, kunnen we een entiteitsdiscriminerende eigenschap toevoegen aan ons schema en deze gebruiken als partitiesleutel voor deze container. Door deze eigenschap een constante waarde toe te wijzen voor alle documenten van dit type in de container, zorgen we ervoor dat we nu één partitiequery hebben. In dit geval roepen we de eigenschap type aan en geven we een constante waarde van category. Onze query ziet er nu als volgt uit: SELECT * FROM c WHERE c.type = ”category”.

Producttags modelleren
De volgende stap is de ProductTag entiteit. Deze entiteit is bijna identiek aan ProductCategory de entiteit die we in de vorige sectie hebben besproken. Laten we hier dezelfde benadering nemen en het document modelleren om id- en naameigenschappen te bevatten en een entiteitsdiscriminatoreigenschap te maken, typein dit geval met een constante waarde van tag. Laten we een nieuwe container maken die wordt aangeroepen ProductTag en de nieuwe partitiesleutel maken type .
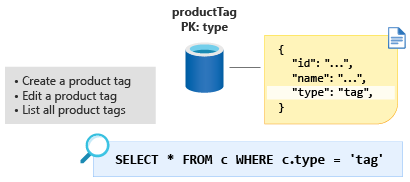
Sommige mensen vinden deze techniek voor het modelleren van kleine opzoektabellen vreemd. Het modelleren van onze gegevens op deze manier biedt ons echter de mogelijkheid om in de volgende module een verdere optimalisatie te maken.