Oefening: gegevens visualiseren met de renderoperator
We hebben een meteorologische gegevensset gebruikt om het aantal stormgebeurtenissen in verschillende Amerikaanse staten voor het jaar 2007 samen te voegen en te vergelijken. Hier visualiseert u deze resultaten met behulp van tijdgebonden grafieken.
render De operator gebruiken
Zoals u weet, hebt u de summarize operator gebruikt om gebeurtenissen te groeperen op een gemeenschappelijk veld, zoals State. In de vorige les hebt u verschillende versies van de count operator gebruikt om het aantal en de typen gebeurtenissen per status te vergelijken. Het visualiseren van deze resultaten kan handig zijn bij het vergelijken van activiteiten in verschillende staten.
Als u resultaten wilt visualiseren, gebruikt u de render operator. Deze operator wordt aan het einde van een query geleverd. Binnen de render operator geeft u op welk type visualisatie u wilt gebruiken, zoals columnchart, barchart, piechart, scatterchart, en pivotchartandere. U kunt desgewenst ook verschillende eigenschappen van de visualisatie definiëren, zoals de x-as of y-as.
In dit voorbeeld visualiseert u de vorige query met behulp van een staafdiagram.
Voer de volgende query uit.
StormEvents | summarize count(), EventsWithDamageToCrops = countif(DamageCrops > 0), dcount(EventType) by State | sort by count_ | render barchartU krijgt resultaten die eruitzien als de volgende afbeelding:

Let op de legenda rechts van het staafdiagram. Elke waarde in de legenda vertegenwoordigt een andere kolom met gegevens die zijn samengevat met state in de query. Selecteer een van de waarden, zoals count_, om deze gegevens weer te geven in het staafdiagram. Door count_ uit te schakelen, verwijdert u het totale aantal en blijft u het aantal gebeurtenissen achter die schade hebben veroorzaakt en een uniek aantal gebeurtenissen. U krijgt een grafiek die eruitziet als de volgende afbeelding:

Bekijk het resulterende staafdiagram. Welke inzichten kunt u hieruit verkrijgen? U ziet bijvoorbeeld dat Texas de meest individuele stormgebeurtenissen had, maar Iowa had de hoogste incidentie van schadelijke stormgebeurtenissen.


Waarden groeperen met behulp van de bin() functie
Tot nu toe hebt u aggregatiefuncties gebruikt om gebeurtenissen op staat te groeperen. Laten we nu eens kijken naar de verdeling van stormen gedurende het hele jaar door gegevens te groeperen op tijd. De tijdwaarden die we in elke record hebben, zijn de begin- en eindtijd. Laten we de begintijden van de gebeurtenis per week groeperen, zodat we kunnen zien hoeveel stormen er elke week in het jaar 2007 zijn gebeurd.
U gebruikt de bin() functie, waarmee waarden worden gegroepeerd in ingestelde intervallen. U hebt bijvoorbeeld gegevens van elke dag van het jaar en u wilt deze datums per week groeperen. Of u wilt populatiegegevens groeperen op leeftijdsklassen. De syntaxis van deze operator is:
bin(value,roundTo)
De bin-waarde kan een getal, datum of tijdsperiode zijn. U voegt het aantal samen met behulp van de bin() functie om u een aantal gebeurtenissen per week te geven. De waarde die u wilt groeperen, is de StartTime van de stormgebeurtenis, met de grootte roundTo bin van 7 dagen of 7d kortom. Ten slotte worden de gegevens weergegeven als een kolomdiagram om een histogram te maken.
Voer de volgende query uit.
StormEvents | summarize count() by bin(StartTime, 7d) | render columnchartU krijgt resultaten die eruitzien als de volgende afbeelding:
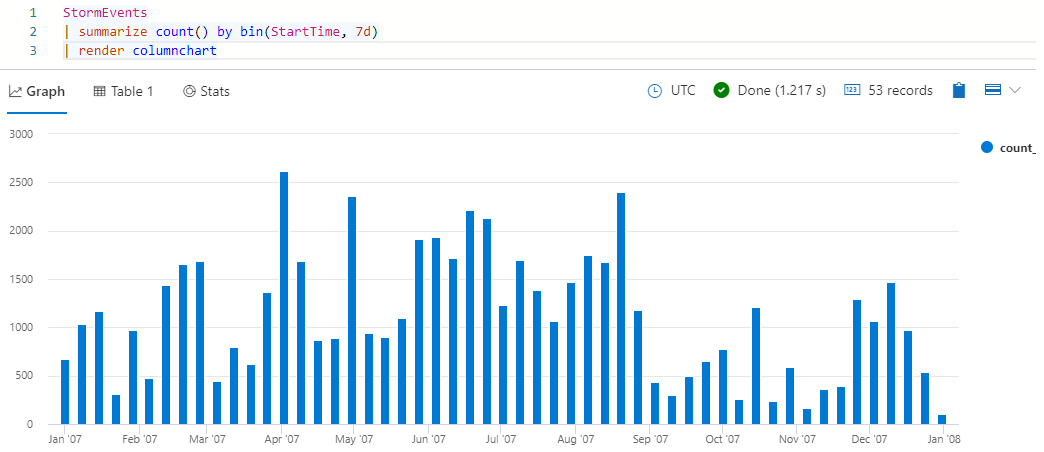
Bekijk het resulterende histogram. Beweeg de muisaanwijzer over een van de balken om de begintijd van de bin (x-waarde) en het aantal gebeurtenissen (y-waarde) weer te geven.
sum De operator gebruiken
In de vorige query hebt u gekeken naar het aantal stormgebeurtenissen in de loop van de tijd. Laten we eens kijken naar de schade die deze stormen hebben veroorzaakt. Hiervoor gebruikt u de sum aggregatiefunctie, omdat u de totale hoeveelheid schade wilt zien die in elk tijdsinterval wordt veroorzaakt. De gegevensset waarmee u werkt, heeft twee kolommen met betrekking tot schade: DamageProperty en DamageCrops.
In de volgende query maakt u eerst een berekende kolom waarmee deze twee schadebronnen aan elkaar worden toegevoegd. Vervolgens maakt u een aggregatie van de totale schade die per week is geplaatst. Ten slotte geeft u een kolomdiagram weer dat de wekelijkse schade aangeeft die wordt veroorzaakt door alle stormen.
Voer de volgende query uit.
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by bin(StartTime, 7d) | render columnchartU krijgt resultaten die eruitzien als de volgende afbeelding:
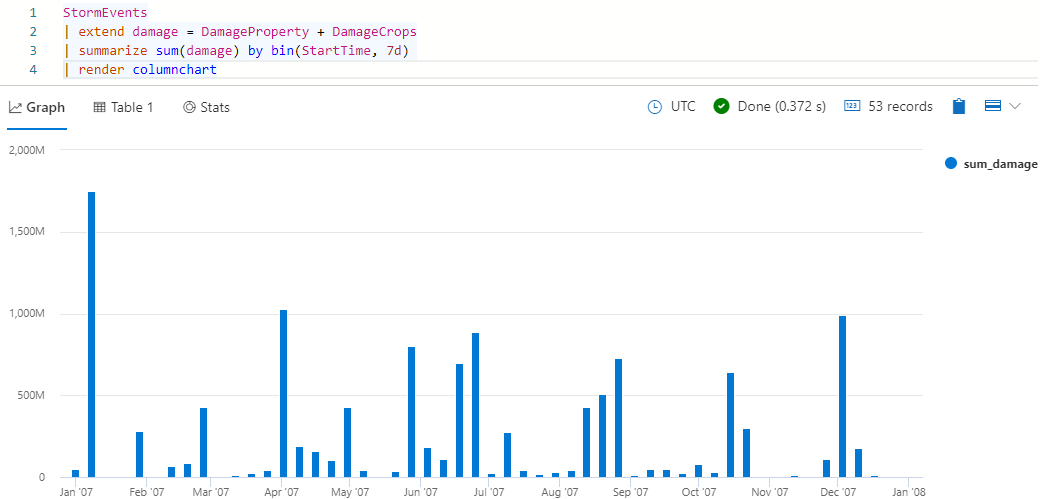
In de vorige query ziet u schade als een functie van tijd. Een andere manier om de schade te vergelijken is per gebeurtenistype. Voer de volgende query uit om een cirkeldiagram te gebruiken om de schade te vergelijken die wordt veroorzaakt door verschillende gebeurtenistypen.
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by EventType | render piechartU krijgt resultaten die eruitzien als de volgende afbeelding:
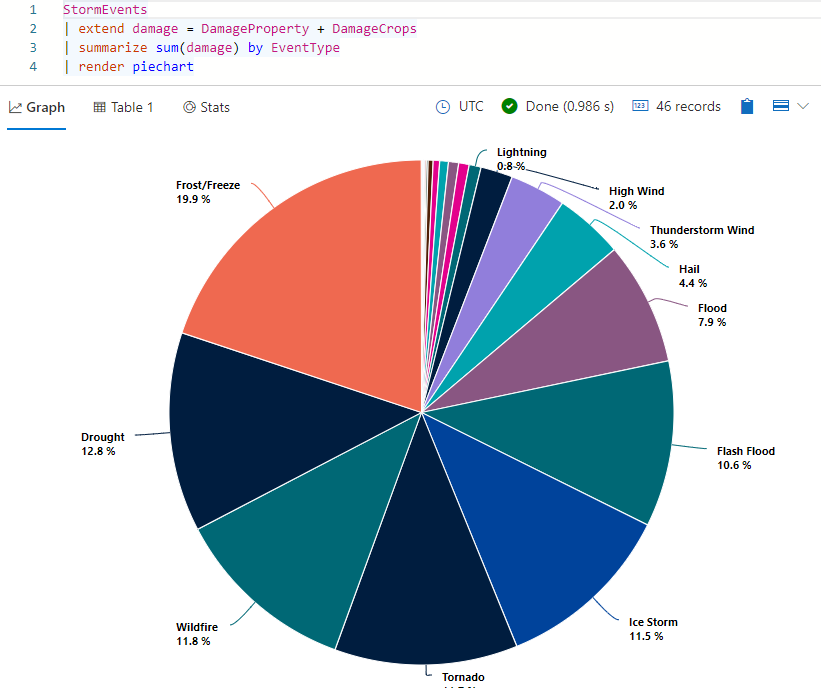
Beweeg de muisaanwijzer over een van de segmenten van het cirkeldiagram. U ziet de absolute waarde (totale schade veroorzaakt door dit gebeurtenistype) en het bijbehorende percentage van de totale schade.