Soorten machine learning
Er zijn meerdere typen machine learning en u moet het juiste type toepassen, afhankelijk van wat u probeert te voorspellen. In het volgende diagram ziet u een uitsplitsing van veelvoorkomende typen machine learning.
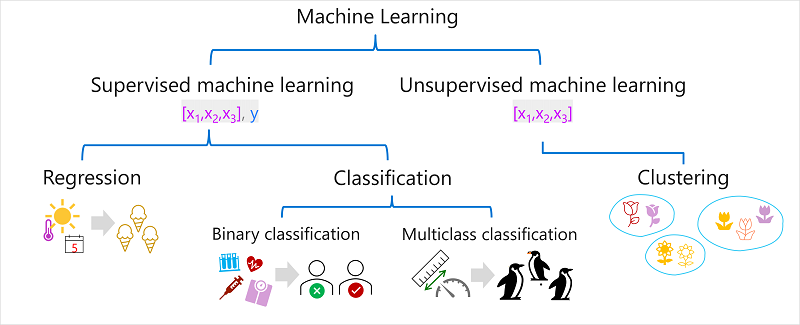
Machine learning onder supervisie
Machine learning onder supervisie is een algemene term voor machine learning-algoritmen waarin de trainingsgegevens zowel functiewaarden als bekende labelwaarden bevatten. Machine learning onder supervisie wordt gebruikt om modellen te trainen door een relatie tussen de functies en labels in eerdere waarnemingen te bepalen, zodat onbekende labels in toekomstige gevallen kunnen worden voorspeld voor functies.
Regressie
Regressie is een vorm van machine learning onder supervisie waarin het label dat door het model wordt voorspeld, een numerieke waarde is. Voorbeeld:
- Het aantal ijsjes dat op een bepaalde dag wordt verkocht, op basis van de temperatuur, neerslag en windsnelheid.
- De verkoopprijs van een woning op basis van de grootte op vierkante voet, het aantal slaapkamers dat het bevat en sociaal-economische metrische gegevens voor de locatie.
- De brandstofefficiëntie (in mijlen per liter) van een auto op basis van de motorgrootte, het gewicht, de breedte, de hoogte en de lengte.
Classificatie
Classificatie is een vorm van machine learning onder supervisie waarin het label een categorisatie of klasse vertegenwoordigt. Er zijn twee algemene classificatiescenario's.
Binaire classificatie
In binaire classificatie bepaalt het label of het waargenomen item een exemplaar van een specifieke klasse is (of niet). Of zet een andere manier op, binaire classificatiemodellen voorspellen een van twee wederzijds exclusieve resultaten. Voorbeeld:
- Of een patiënt risico loopt op diabetes op basis van klinische metrische gegevens zoals gewicht, leeftijd, bloedglucosegehalte, enzovoort.
- Of een bankklant standaard een lening zal betalen op basis van inkomsten, kredietgeschiedenis, leeftijd en andere factoren.
- Of een klant in een adressenlijst positief reageert op een marketingaanbieding op basis van demografische kenmerken en eerdere aankopen.
In al deze voorbeelden voorspelt het model een binaire onwaar/- of positieve/negatieve voorspelling voor één mogelijke klasse.
Classificatie met meerdere klassen
Classificatie met meerdere klassen breidt binaire classificatie uit om een label te voorspellen dat een van meerdere mogelijke klassen vertegenwoordigt. Bijvoorbeeld:
- De soort van een pinguïn (Adelie, Gentoo of Chinstrap) op basis van zijn fysieke metingen.
- Het genre van een film (komedie, horror, romantiek, avontuur of sciencefiction) op basis van zijn cast, regisseur en budget.
In de meeste scenario's waarbij een bekende set van meerdere klassen is betrokken, wordt classificatie met meerdere klassen gebruikt om wederzijds exclusieve labels te voorspellen. Een pinguïn kan bijvoorbeeld niet zowel een Gentoo als een Adelie zijn. Er zijn echter ook enkele algoritmen die u kunt gebruiken om classificatiemodellen met meerdere labels te trainen, waarbij er mogelijk meer dan één geldig label is voor één observatie. Een film kan bijvoorbeeld worden gecategoriseerd als zowel sciencefiction als komedie.
Machine Learning zonder supervisie
Machine learning zonder supervisie omvat trainingsmodellen met behulp van gegevens die alleen bestaan uit functiewaarden zonder bekende labels. Machine Learning-algoritmen zonder supervisie bepalen relaties tussen de functies van de waarnemingen in de trainingsgegevens.
Clustering
De meest voorkomende vorm van machine learning zonder supervisie is clustering. Een clustering-algoritme identificeert overeenkomsten tussen waarnemingen op basis van hun functies en groepeert deze in discrete clusters. Voorbeeld:
- Groepeer vergelijkbare bloemen op basis van hun grootte, aantal bladeren en het aantal bloemblaadjes.
- Identificeer groepen van vergelijkbare klanten op basis van demografische kenmerken en aankoopgedrag.
Op sommige manieren is clustering vergelijkbaar met classificatie met meerdere klassen; in dat het waarnemingen categoriseert in discrete groepen. Het verschil is dat u bij het gebruik van classificatie al de klassen kent waartoe de waarnemingen in de trainingsgegevens behoren; Het algoritme werkt dus door de relatie tussen de functies en het bekende classificatielabel te bepalen. Bij clustering is er geen eerder bekend clusterlabel en het algoritme groepeert de gegevensobservaties op basis van gelijkenis van functies.
In sommige gevallen wordt clustering gebruikt om de set klassen te bepalen die bestaan voordat een classificatiemodel wordt getraind. U kunt bijvoorbeeld clustering gebruiken om uw klanten in groepen te segmenteren en deze groepen vervolgens te analyseren om verschillende klassen van klanten te identificeren en te categoriseren (hoge waarde - laag volume, frequente kleine koper, enzovoort). Vervolgens kunt u uw categorisaties gebruiken om de waarnemingen in de clusterresultaten te labelen en de gelabelde gegevens te gebruiken om een classificatiemodel te trainen dat voorspelt welke klantcategorie een nieuwe klant kan horen.