Wat is machine learning?
Machine learning heeft de oorsprong van statistieken en wiskundige modellering van gegevens. Het fundamentele idee van machine learning is het gebruik van gegevens uit eerdere waarnemingen om onbekende resultaten of waarden te voorspellen. Voorbeeld:
- De eigenaar van een ijswinkel kan een app gebruiken die historische verkoop- en weerrecords combineert om te voorspellen hoeveel ijsjes ze waarschijnlijk op een bepaalde dag verkopen, op basis van de weersvoorspelling.
- Een arts kan klinische gegevens van eerdere patiënten gebruiken om geautomatiseerde tests uit te voeren die voorspellen of een nieuwe patiënt risico loopt op basis van factoren zoals gewicht, bloedglucosegehalte en andere metingen.
- Een onderzoeker in het Antarctisch kan eerdere waarnemingen gebruiken om de identificatie van verschillende pinguïnsoorten (zoals Adelie, Gentoo of Chinstrap) te automatiseren op basis van metingen van de flippers, bill en andere fysieke kenmerken van een vogel.
Machine learning als functie
Omdat machine learning is gebaseerd op wiskunde en statistieken, is het gebruikelijk om te denken over machine learning-modellen in wiskundige termen. Een machine learning-model is een softwaretoepassing die een functie inkapselt om een uitvoerwaarde te berekenen op basis van een of meer invoerwaarden. Het proces van het definiëren van die functie wordt training genoemd. Nadat de functie is gedefinieerd, kunt u deze gebruiken om nieuwe waarden te voorspellen in een proces dat deductie wordt genoemd.
Laten we de stappen voor het trainen en deductie bekijken.
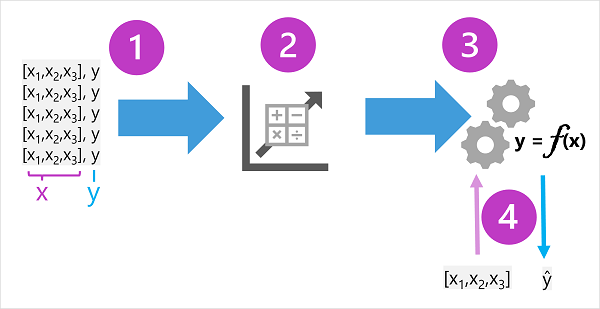
De trainingsgegevens bestaan uit eerdere waarnemingen. In de meeste gevallen bevatten de waarnemingen de waargenomen kenmerken of kenmerken van het waargenomen ding en de bekende waarde van het ding dat u wilt trainen om een model te voorspellen (ook wel het label genoemd).
In wiskundige termen ziet u vaak de functies waarnaar wordt verwezen met behulp van de verkorte variabelenaam x en het label waarnaar wordt verwezen als y. Meestal bestaat een observatie uit meerdere functiewaarden, dus x is eigenlijk een vector (een matrix met meerdere waarden), zoals: [x1,x 2,x 3,...].
Laten we dit duidelijker maken door de eerder beschreven voorbeelden te bekijken:
- In het scenario voor de verkoop van ijs is het ons doel om een model te trainen dat het aantal ijsverkoop kan voorspellen op basis van het weer. De weermetingen voor de dag (temperatuur, neerslag, windsnelheid, enzovoort) zijn de kenmerken (x) en het aantal verkochte ijsjes op elke dag is het label (y).
- In het medische scenario is het doel om te voorspellen of een patiënt risico loopt op diabetes op basis van hun klinische metingen. De metingen van de patiënt (gewicht, bloedglucosegehalte, enzovoort) zijn de kenmerken (x) en de kans op diabetes (bijvoorbeeld 1 voor risico, 0 voor niet-risico) is het label (y).
- In het Antarctische onderzoeksscenario willen we de soort pinguïn voorspellen op basis van de fysieke kenmerken ervan. De belangrijkste metingen van de pinguïn (lengte van de flippers, breedte van de bill, enzovoort) zijn de kenmerken (x) en de soorten (bijvoorbeeld 0 voor Adelie, 1 voor Gentoo of 2 voor Chinstrap) is het label (y).
Er wordt een algoritme toegepast op de gegevens om een relatie tussen de functies en het label te bepalen en deze relatie te generaliseren als een berekening die op x kan worden uitgevoerd om y te berekenen. Het specifieke algoritme dat wordt gebruikt, is afhankelijk van het soort voorspellend probleem dat u probeert op te lossen (meer hierover later), maar het basisprincipe is om een functie aan de gegevens te passen , waarin de waarden van de functies kunnen worden gebruikt om het label te berekenen.
Het resultaat van het algoritme is een model dat de berekening die door het algoritme als een functie is afgeleid, inkapselt. We noemen het eens f. In wiskundige notatie:
y = f(x)
Nu de trainingsfase is voltooid, kan het getrainde model worden gebruikt voor deductie. Het model is in wezen een softwareprogramma dat de functie inkapselt die wordt geproduceerd door het trainingsproces. U kunt een set functiewaarden invoeren en ontvangen als uitvoer een voorspelling van het bijbehorende label. Omdat de uitvoer van het model een voorspelling is die door de functie is berekend en niet een waargenomen waarde, ziet u vaak de uitvoer van de functie die wordt weergegeven als ŷ (wat nogal heerlijk wordt verbaald als 'y-hat').