Wat zijn taalmodellen?
Generatieve AI-toepassingen worden mogelijk gemaakt door taalmodellen. Dit is een speciaal type machine learning-model dat u kunt gebruiken om NLP-taken (Natural Language Processing) uit te voeren, waaronder:
- Het bepalen van gevoel of het op een andere manier classificeren van tekst in natuurlijke taal.
- Tekst samenvatten.
- Meerdere tekstbronnen vergelijken voor semantische gelijkenis.
- Nieuwe natuurlijke taal genereren.
Hoewel de wiskundige principes achter deze taalmodellen complex kunnen zijn, kan een basiskennis van de architectuur die wordt gebruikt om ze te implementeren, u helpen een conceptueel inzicht te krijgen in hoe ze werken.
Transformatormodellen
Machine learning-modellen voor verwerking van natuurlijke taal zijn in de loop der jaren ontwikkeld. De geavanceerde grote taalmodellen van vandaag zijn gebaseerd op de transformatorarchitectuur , die voortbouwt op en uitbreidt enkele technieken die succesvol zijn gebleken in het modelleren van vocabulaires ter ondersteuning van NLP-taken , en met name in het genereren van taal. Transformatormodellen worden getraind met grote hoeveelheden tekst, zodat ze de semantische relaties tussen woorden kunnen vertegenwoordigen en deze relaties kunnen gebruiken om mogelijke reeksen tekst te bepalen die zinvol zijn. Transformatormodellen met een groot genoeg vocabulaire kunnen taalreacties genereren die moeilijk te onderscheiden zijn van menselijke reacties.
De modelarchitectuur van het transformatieprogramma bestaat uit twee onderdelen of blokken:
- Een encoderblok dat semantische representaties van de trainingswoordenlijst maakt.
- Een decoderblok waarmee nieuwe taalreeksen worden gegenereerd.
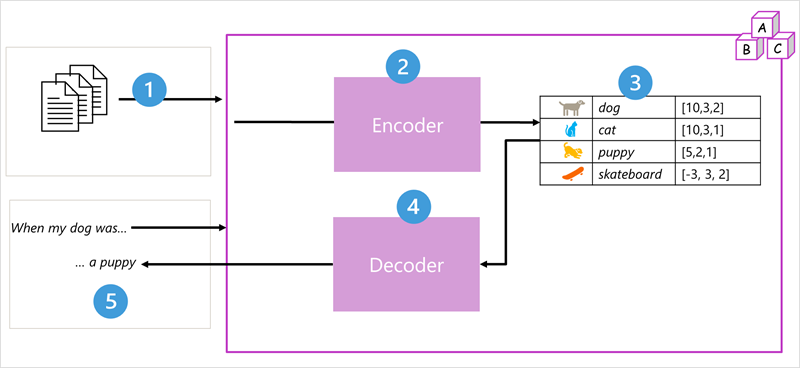
- Het model wordt getraind met een grote hoeveelheid tekst in natuurlijke taal, vaak afkomstig van internet of andere openbare tekstbronnen.
- De reeksen tekst worden onderverdeeld in tokens (bijvoorbeeld afzonderlijke woorden) en het encoderblok verwerkt deze tokenreeksen met behulp van een techniek die aandacht riep om relaties tussen tokens te bepalen (bijvoorbeeld welke tokens invloed hebben op de aanwezigheid van andere tokens in een reeks, verschillende tokens die vaak in dezelfde context worden gebruikt, enzovoort.)
- De uitvoer van de encoder is een verzameling vectoren (numerieke matrices met meerdere waarden) waarin elk element van de vector een semantisch kenmerk van de tokens vertegenwoordigt. Deze vectoren worden insluitingen genoemd.
- Het decoderblok werkt op een nieuwe reeks teksttokens en gebruikt de insluitingen die door de encoder worden gegenereerd om een geschikte uitvoer van natuurlijke taal te genereren.
- Als u bijvoorbeeld een invoerreeks zoals 'Wanneer mijn hond was', kan het model de aandachtstechniek gebruiken om de invoertokens en de semantische kenmerken te analyseren die zijn gecodeerd in de insluitingen om een geschikte voltooiing van de zin te voorspellen, zoals 'een puppy'.
In de praktijk variëren de specifieke implementaties van de architectuur, bijvoorbeeld het Bidirectional Encoder Representations from Transformers (BERT)-model dat door Google is ontwikkeld om hun zoekmachine te ondersteunen, alleen het encoderblok gebruikt, terwijl het GPT-model (Pretrained Transformer) dat is ontwikkeld door OpenAI, alleen het decoderblok gebruikt.
Hoewel een volledige uitleg van elk aspect van transformatormodellen buiten het bereik van deze module valt, kan een uitleg van enkele van de belangrijkste elementen in een transformator u helpen een idee te krijgen van hoe ze generatieve AI ondersteunen.
Tokenisatie
De eerste stap bij het trainen van een transformatormodel is het opsmaken van de trainingstekst in tokens , met andere woorden, om elke unieke tekstwaarde te identificeren. Omwille van de eenvoud kunt u elk afzonderlijk woord in de trainingstekst beschouwen als een token (hoewel in werkelijkheid tokens kunnen worden gegenereerd voor gedeeltelijke woorden of combinaties van woorden en interpunctie).
Denk bijvoorbeeld aan de volgende zin:
I heard a dog bark loudly at a cat
Als u deze tekst wilt tokeniseren, kunt u elk afzonderlijk woord identificeren en token-id's eraan toewijzen. Voorbeeld:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
De zin kan nu worden weergegeven met de tokens: {1 2 3 4 5 6 7 3 8}. Op dezelfde manier kan de zin 'Ik hoorde een kat' worden weergegeven als {1 2 3 8}.
Terwijl u het model blijft trainen, wordt elk nieuw token in de trainingstekst toegevoegd aan de woordenlijst met de juiste token-id's:
- meow (9)
- skateboard (10)
- enzovoort...
Met een voldoende grote set trainingsteksten kan een woordenlijst van vele duizenden tokens worden gecompileerd.
Insluitingen
Hoewel het handig kan zijn om tokens als eenvoudige id's weer te geven- in wezen een index maken voor alle woorden in de woordenlijst, geven ze ons niets over de betekenis van de woorden of de relaties tussen deze woorden. Als u een woordenlijst wilt maken die semantische relaties tussen de tokens inkapselt, definiëren we contextuele vectoren, ook wel insluitingen genoemd. Vectoren zijn numerieke weergaven met meerdere waarden van gegevens, bijvoorbeeld [10, 3, 1] waarin elk numeriek element een bepaald kenmerk van de informatie vertegenwoordigt. Voor taaltokens vertegenwoordigt elk element van de vector van een token een semantisch kenmerk van het token. De specifieke categorieën voor de elementen van de vectoren in een taalmodel worden bepaald tijdens de training op basis van hoe vaak woorden samen of in vergelijkbare contexten worden gebruikt.
Vectoren vertegenwoordigen lijnen in multidimensionale ruimte, beschrijvende richting en afstand langs meerdere assen (u kunt indruk maken op uw wiskundige vrienden door deze amplitude en grootte aan te roepen). Het kan handig zijn om de elementen in een insluitvector voor een token te beschouwen als het weergeven van stappen langs een pad in multidimensionale ruimte. Een vector met drie elementen vertegenwoordigt bijvoorbeeld een pad in driedimensionale ruimte waarin de elementwaarden aangeven dat de eenheden vooruit/terug, links/rechts en omhoog/omlaag zijn verplaatst. Over het algemeen beschrijft de vector de richting en afstand van het pad van oorsprong tot eind.
De elementen van de tokens in de ruimte voor insluitingen vertegenwoordigen elk een semantisch kenmerk van het token, zodat semantisch vergelijkbare tokens moeten resulteren in vectoren met een vergelijkbare afdrukstand, met andere woorden, ze wijzen in dezelfde richting. Een techniek die cosinus-gelijkenis wordt genoemd, wordt gebruikt om te bepalen of twee vectoren vergelijkbare richtingen hebben (ongeacht de afstand) en daarom semantisch gekoppelde woorden vertegenwoordigen. Stel dat de insluitingen voor onze tokens bestaan uit vectoren met drie elementen, bijvoorbeeld:
- 4 ("hond"): [10,3,2]
- 8 ("kat"): [10,3,1]
- 9 ("puppy"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
We kunnen deze vectoren in driedimensionale ruimte tekenen, zoals:
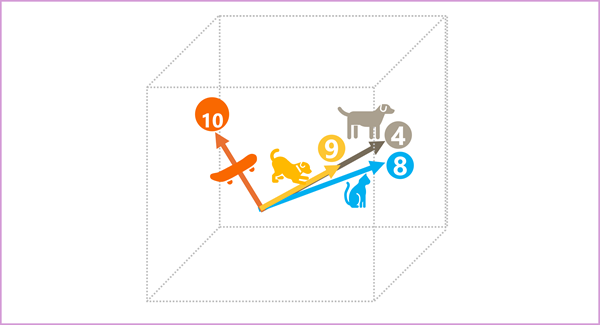
De insluitingsvectoren voor "hond" en "puppy" beschrijven een pad langs een bijna identieke richting, wat ook vrij vergelijkbaar is met de richting voor "kat". De insluitingsvector voor skateboard beschrijft de reis echter in een heel andere richting.
Notitie
In het vorige voorbeeld ziet u een eenvoudig voorbeeldmodel waarin elk insluiten slechts drie dimensies heeft. Echte taalmodellen hebben nog veel meer dimensies.
Er zijn meerdere manieren waarop u de juiste insluitingen kunt berekenen voor een bepaalde set tokens, waaronder taalmodelleringsalgoritmen zoals Word2Vec of het coderingsblok in een transformatormodel.
Opmerking
De encoder - en decoderblokken in een transformatormodel bevatten meerdere lagen die het neurale netwerk vormen voor het model. We hoeven niet in te gaan op de details van al deze lagen, maar het is handig om een van de typen lagen te overwegen die in beide blokken worden gebruikt: aandachtslagen . Aandacht is een techniek die wordt gebruikt om een reeks teksttokens te onderzoeken en de sterkte van de relaties tussen deze tokens te kwantificeren. In het bijzonder moet u zelf aandacht besteden aan de invloed van andere tokens rond een bepaald token op de betekenis van dat token.
In een encoderblok wordt elk token zorgvuldig onderzocht in de context en wordt een passende codering bepaald voor het insluiten van vectoren. De vectorwaarden zijn gebaseerd op de relatie tussen het token en andere tokens waarmee het vaak wordt weergegeven. Deze contextuele benadering betekent dat hetzelfde woord meerdere insluitingen kan hebben, afhankelijk van de context waarin het wordt gebruikt, bijvoorbeeld 'de schors van een boom' betekent iets anders dan 'Ik hoorde een hondenschors'.
In een decoderblok worden aandachtslagen gebruikt om het volgende token in een reeks te voorspellen. Voor elk gegenereerd token heeft het model een aandachtslaag die rekening houdt met de volgorde van tokens tot dat punt. Het model beschouwt welke van de tokens het meest invloedrijk is bij het overwegen van wat het volgende token moet zijn. Bijvoorbeeld, gezien de reeks 'Ik hoorde een hond', kan de aandachtslaag meer gewicht toewijzen aan de tokens 'gehoord' en 'hond' bij het overwegen van het volgende woord in de reeks:
Ik hoorde een hond [schors]
Houd er rekening mee dat de aandachtslaag werkt met numerieke vectorweergaven van de tokens, niet de werkelijke tekst. In een decoder begint het proces met een reeks token-insluitingen die de tekst vertegenwoordigen die moeten worden voltooid. Het eerste wat gebeurt, is dat een andere positionele coderingslaag een waarde toevoegt aan elke insluiting om de positie in de volgorde aan te geven:
- [1,5,6,2] (I)
- [2,9,3,1] (gehoord)
- [3,1,1,2] (a)
- [4,10,3,2] (hond)
Tijdens de training is het doel om de vector voor het laatste token in de reeks te voorspellen op basis van de voorgaande tokens. De aandachtslaag wijst een numeriek gewicht toe aan elk token in de reeks tot nu toe. Deze waarde wordt gebruikt om een berekening uit te voeren op de gewogen vectoren die een aandachtsscore produceren die kan worden gebruikt om een mogelijke vector voor het volgende token te berekenen. In de praktijk gebruikt een techniek met de naam multi-head aandacht verschillende elementen van de insluitingen om meerdere aandachtsscores te berekenen. Vervolgens wordt een neuraal netwerk gebruikt om alle mogelijke tokens te evalueren om het meest waarschijnlijke token te bepalen waarmee de reeks kan worden voortgezet. Het proces wordt iteratief voortgezet voor elk token in de reeks, waarbij de uitvoervolgorde tot nu toe regressief wordt gebruikt als de invoer voor de volgende iteratie, in wezen het bouwen van het uitvoertoken per keer.
In de volgende animatie ziet u een vereenvoudigde weergave van hoe dit werkt: in werkelijkheid zijn de berekeningen die door de aandachtslaag worden uitgevoerd complexer; maar de principes kunnen worden vereenvoudigd zoals weergegeven:

- Een reeks token-insluitingen wordt ingevoerd in de aandachtslaag. Elk token wordt weergegeven als een vector van numerieke waarden.
- Het doel van een decoder is om het volgende token in de reeks te voorspellen. Dit is ook een vector die overeenkomt met een insluiting in de woordenlijst van het model.
- De aandachtslaag evalueert de reeks tot nu toe en wijst gewichten toe aan elk token om hun relatieve invloed op het volgende token aan te geven.
- De gewichten kunnen worden gebruikt om een nieuwe vector te berekenen voor het volgende token met een aandachtsscore. Aandacht voor meerdere hoofden gebruikt verschillende elementen in de insluitingen om meerdere alternatieve tokens te berekenen.
- Een volledig verbonden neuraal netwerk maakt gebruik van de scores in de berekende vectoren om het meest waarschijnlijke token te voorspellen uit het hele vocabulaire.
- De voorspelde uitvoer wordt tot nu toe toegevoegd aan de reeks, die wordt gebruikt als invoer voor de volgende iteratie.
Tijdens de training is de werkelijke reeks tokens bekend. We maskeren alleen de tokens die later in de volgorde komen dan de tokenpositie die momenteel wordt overwogen. Net als in elk neuraal netwerk wordt de voorspelde waarde voor de tokenvector vergeleken met de werkelijke waarde van de volgende vector in de reeks en wordt het verlies berekend. De gewichten worden vervolgens incrementeel aangepast om het verlies te verminderen en het model te verbeteren. Wanneer deze wordt gebruikt voor deductie (het voorspellen van een nieuwe reeks tokens), past de getrainde aandachtslaag gewichten toe die het meest waarschijnlijke token voorspellen in het vocabulaire van het model dat semantisch is uitgelijnd op de reeks tot nu toe.
Wat dit allemaal betekent, is dat een transformatormodel zoals GPT-4 (het model achter ChatGPT en Bing) is ontworpen om een tekstinvoer (een prompt genoemd) in te nemen en een syntactisch juiste uitvoer te genereren (een voltooiing genoemd). In feite is de 'magie' van het model dat het de mogelijkheid heeft om een coherente zin samen te stellen. Deze mogelijkheid impliceert geen 'kennis' of 'intelligentie' aan het deel van het model; alleen een grote woordenlijst en de mogelijkheid om zinvolle reeksen woorden te genereren. Wat een groot taalmodel zoals GPT-4 zo krachtig maakt, is het enorme aantal gegevens waarmee het is getraind (openbare en gelicentieerde gegevens van internet) en de complexiteit van het netwerk. Hierdoor kan het model voltooiingen genereren die zijn gebaseerd op de relaties tussen woorden in het vocabulaire waarop het model is getraind; genereert vaak uitvoer die niet kan worden onderscheiden van een menselijke reactie op dezelfde prompt.