Basismodellen in Azure Machine Learning verkennen
Als u een basismodel wilt verfijnen vanuit de modelcatalogus in Azure Machine Learning, kunt u de gebruikersinterface in de studio, de Python SDK of de Azure CLI gebruiken.
Uw gegevens en berekeningen voorbereiden
Voordat u een basismodel kunt verfijnen om de modelprestaties te verbeteren, moet u uw trainingsgegevens voorbereiden en een GPU-rekencluster maken.
Tip
Wanneer u een GPU-rekencluster maakt in Azure Machine Learning, wordt de voor GPU geoptimaliseerde virtuele machine voor u gemaakt. Meer informatie over de grootten van de virtuele GPU-machines die beschikbaar zijn in Azure.
De trainingsgegevens kunnen de indeling JSON Lines (JSONL), CSV of TSV hebben. De vereisten van uw gegevens variëren op basis van de specifieke taak waarvoor u uw model wilt aanpassen.
| Opdracht | Vereisten voor gegevenssets |
|---|---|
| Tekstclassificatie | Twee kolommen: Sentence (tekenreeks) en Label (geheel getal/tekenreeks) |
| Tokenclassificatie | Twee kolommen: Token (tekenreeks) en Tag (tekenreeks) |
| Vragen beantwoorden | Vijf kolommen: Question (tekenreeks), (tekenreeks), Context Answers (tekenreeks), Answers_start (int) en Answers_text (tekenreeks) |
| Samenvatting | Twee kolommen: Document (tekenreeks) en Summary (tekenreeks) |
| Vertaling | Twee kolommen: Source_language (tekenreeks) en Target_language (tekenreeks) |
Notitie
Uw gegevensset moet over de benodigde vereisten beschikken. U kunt echter verschillende kolomnamen gebruiken en de kolom toewijzen aan de juiste vereiste.
Wanneer u uw gegevensset en rekencluster gereed hebt, kunt u een taak voor het afstemmen configureren in Azure Machine Learning.
Een basismodel kiezen
Wanneer u in de Azure Machine Learning-studio naar de modelcatalogus navigeert, kunt u alle basismodellen verkennen.
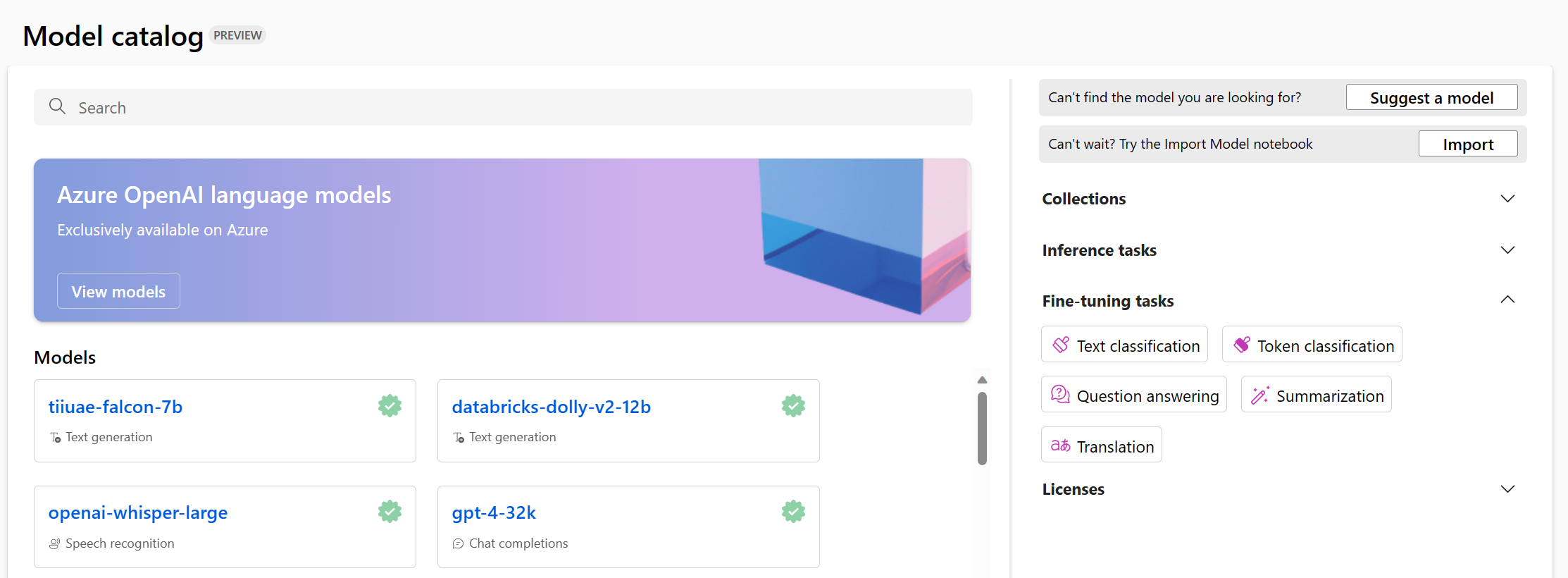
U kunt de beschikbare modellen filteren op basis van de taak waarvoor u een model wilt afstemmen. Per taak hebt u verschillende opties voor basismodellen waaruit u kunt kiezen. Wanneer u besluit tussen basismodellen voor een taak, kunt u de beschrijving van het model en de modelkaart waarnaar wordt verwezen, bekijken.
Enkele overwegingen waarmee u rekening kunt houden bij het bepalen van een basismodel voordat u het verfijnen gaat, zijn:
- Modelmogelijkheden: evalueer de mogelijkheden van het basismodel en hoe goed deze overeenkomen met uw taak. Een model zoals BERT is bijvoorbeeld beter in het begrijpen van korte teksten.
- Vooraftrainingsgegevens: Overweeg de gegevensset die wordt gebruikt voor het vooraf trainen van het basismodel. GPT-2 wordt bijvoorbeeld getraind op niet-gefilterde inhoud van internet die kan leiden tot vooroordelen.
- Beperkingen en vooroordelen: houd rekening met eventuele beperkingen of vooroordelen die mogelijk aanwezig zijn in het basismodel.
- Taalondersteuning: Ontdek welke modellen de specifieke taalondersteuning of meertalige mogelijkheden bieden die u nodig hebt voor uw use-case.
Tip
Hoewel de Azure Machine Learning-studio u beschrijvingen biedt voor elk basismodel in de modelcatalogus, kunt u ook meer informatie over elk model vinden via de desbetreffende modelkaart. Naar de modelkaarten wordt verwezen in het overzicht van elk model en gehost op de website van Hugging Face
Een taak voor het afstemmen configureren
Als u een taak wilt configureren met behulp van de Azure Machine Learning-studio, moet u de volgende stappen uitvoeren:
- Kies een basismodel.
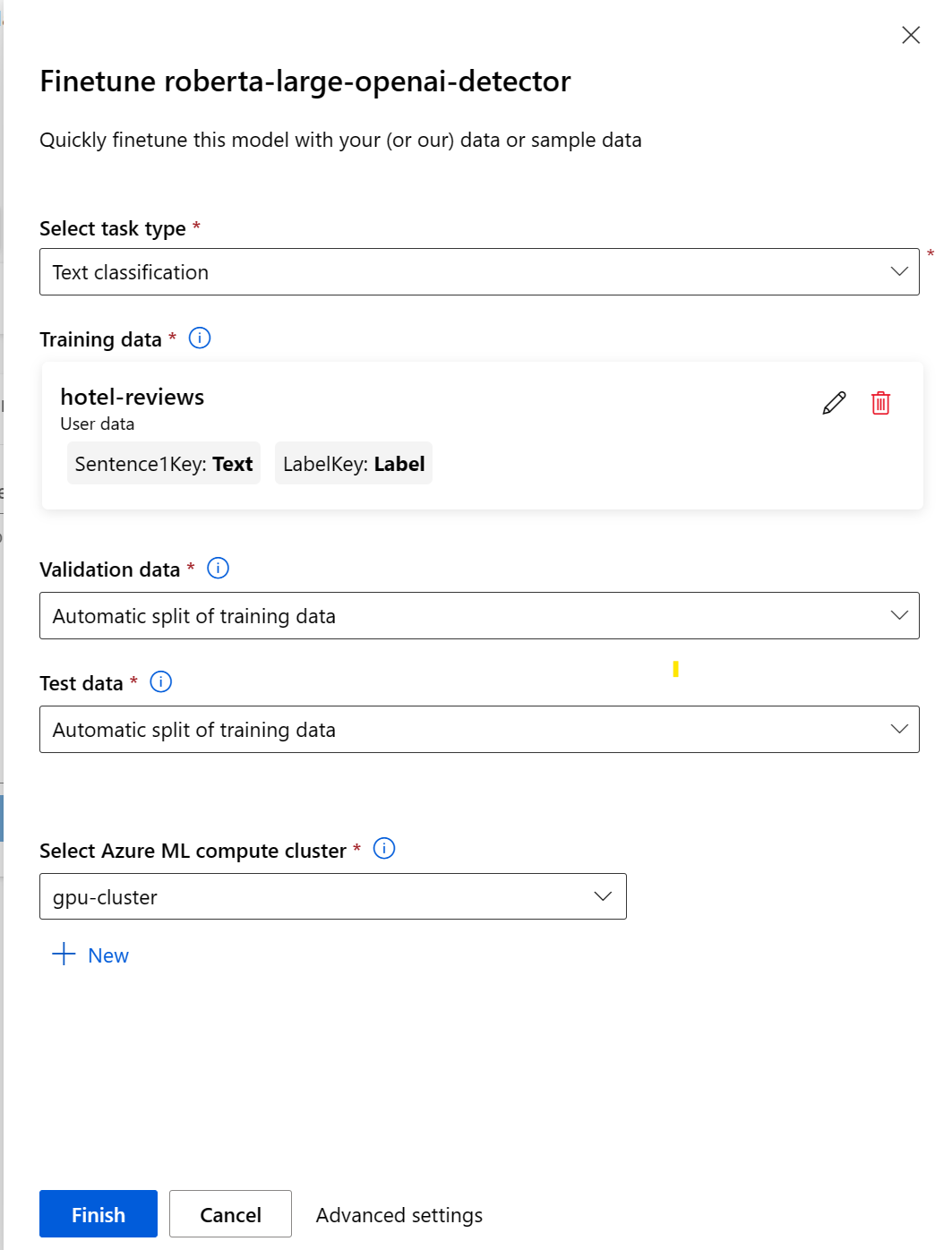
- Selecteer Finetune om een pop-upvenster te openen waarmee u de taak kunt configureren.
- Selecteer het taaktype.
- Selecteer de trainingsgegevens en wijs de kolommen in uw trainingsgegevens toe aan de vereisten voor de gegevensset.
- Laat Azure Machine Learning de trainingsgegevens automatisch splitsen om een validatie- en testgegevensset te maken, of geef uw eigen gegevensset op.
- Selecteer een GPU-rekencluster dat wordt beheerd door Azure Machine Learning.
- Selecteer Voltooien om de taak voor het afstemmen te verzenden.
Tip
U kunt desgewenst de geavanceerde instellingen verkennen om instellingen te wijzigen, zoals de naam van de taak en taakparameters (bijvoorbeeld het leerpercentage).
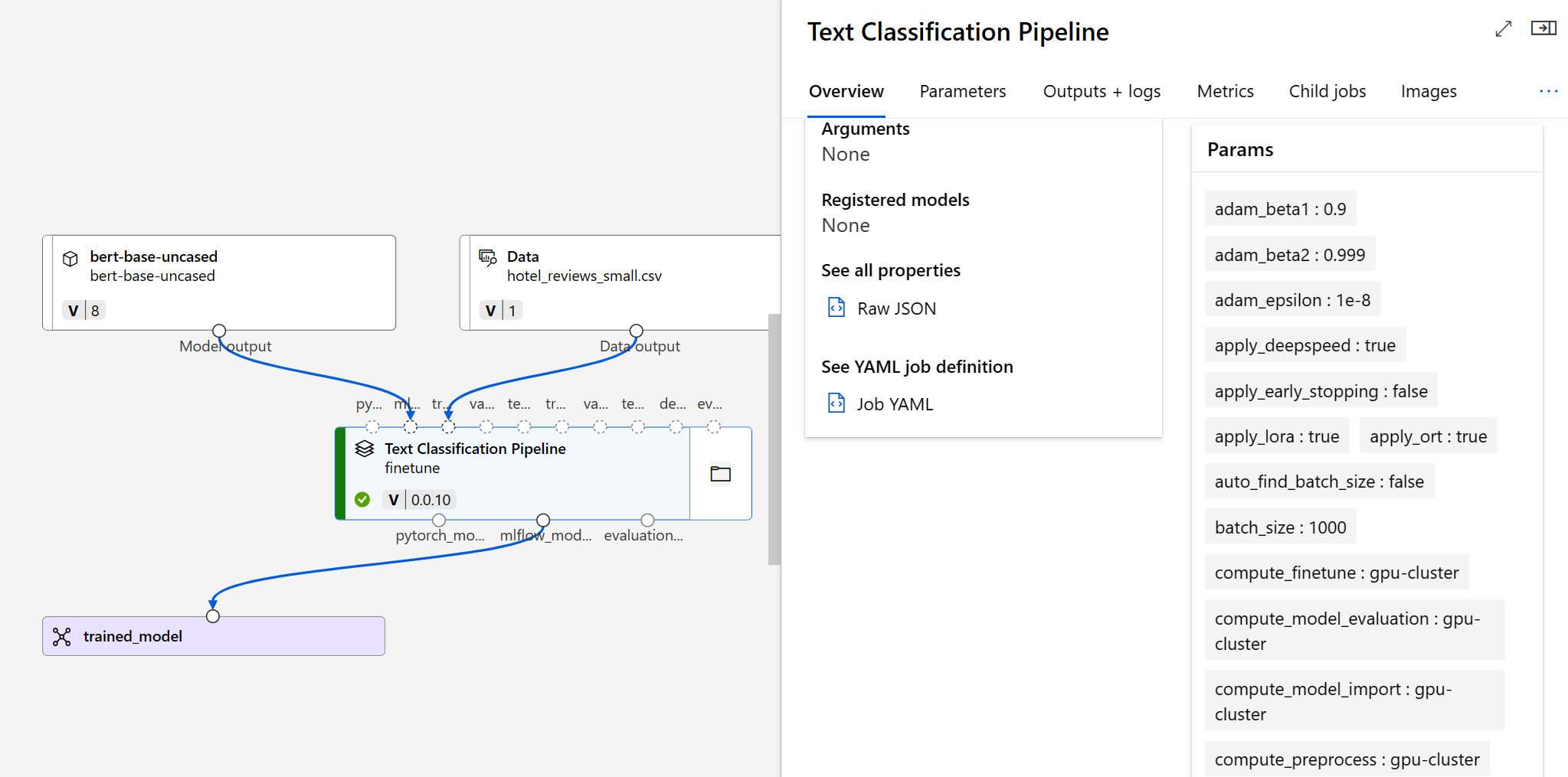
Nadat u de verfijningstaak hebt verzonden, wordt er een pijplijntaak gemaakt om uw model te trainen. U kunt alle invoer controleren en het model verzamelen uit de taakuitvoer.