Algemene elementen van de stroomverwerkingsarchitectuur verkennen
Er zijn veel technologieën die u kunt gebruiken om een oplossing voor stroomverwerking te implementeren, maar hoewel specifieke implementatiedetails kunnen variëren, zijn er algemene elementen voor de meeste streamingarchitecturen.
Een algemene architectuur voor stroomverwerking
Op de eenvoudigste, een architectuur op hoog niveau voor stroomverwerking ziet er als volgt uit:
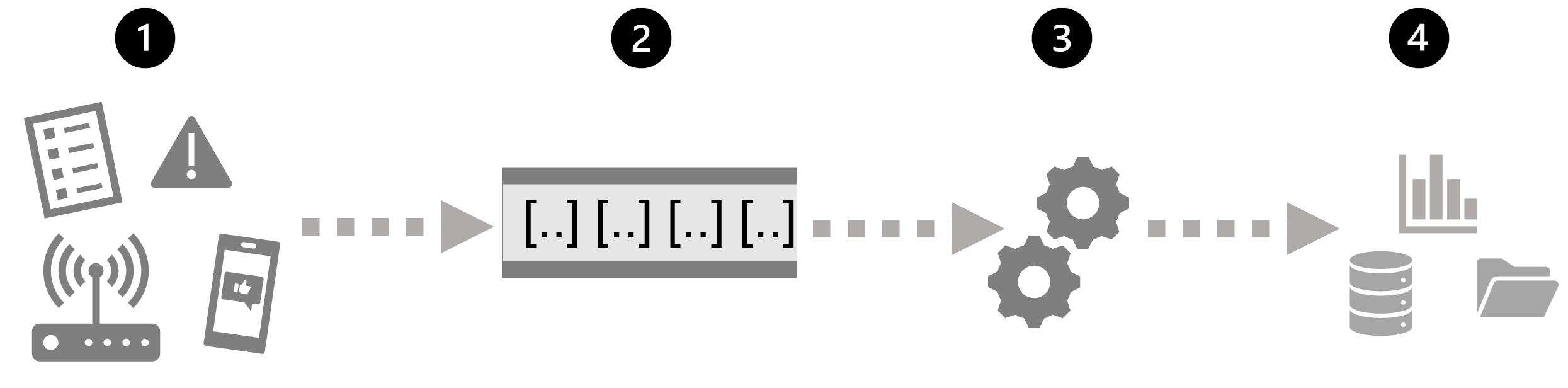
- Een gebeurtenis genereert enkele gegevens. Dit kan een signaal zijn dat wordt verzonden door een sensor, een bericht op sociale media dat wordt geplaatst, een logboekbestandsvermelding die wordt geschreven of een andere gebeurtenis die resulteert in bepaalde digitale gegevens.
- De gegenereerde gegevens worden vastgelegd in een streamingbron voor verwerking. In eenvoudige gevallen kan de bron een map in een gegevensarchief in de cloud of een tabel in een database zijn. In krachtigere streamingoplossingen kan de bron een 'wachtrij' zijn die logica inkapselt om ervoor te zorgen dat gebeurtenisgegevens op volgorde worden verwerkt en dat elke gebeurtenis slechts één keer wordt verwerkt.
- De gebeurtenisgegevens worden verwerkt, vaak door een permanente query die op de gebeurtenisgegevens werkt om gegevens te selecteren voor specifieke typen gebeurtenissen, projectgegevenswaarden of geaggregeerde gegevenswaarden gedurende tijdelijke (tijdgebonden) perioden (of vensters), bijvoorbeeld door het aantal sensoremissies per minuut te tellen.
- De resultaten van de stroomverwerkingsbewerking worden geschreven naar een uitvoer (of sink), wat een bestand, een databasetabel, een realtime visueel dashboard of een andere wachtrij kan zijn voor verdere verwerking door een volgende downstreamquery.
Realtime analyseservices
Microsoft ondersteunt meerdere technologieën die u kunt gebruiken om realtime analyses van streaminggegevens te implementeren, waaronder:
- Azure Stream Analytics: Een PaaS-oplossing (Platform-as-a-Service) die u kunt gebruiken om streamingtaken te definiëren die gegevens uit een streamingbron opnemen, een permanente query toepassen en de resultaten naar een uitvoer schrijven.
- Spark Structured Streaming: een opensource-bibliotheek waarmee u complexe streamingoplossingen kunt ontwikkelen op apache Spark-services, waaronder Microsoft Fabric en Azure Databricks.
- Microsoft Fabric: een krachtige database en analyseplatform met Data-engineer ing, Data Factory, Datawetenschap, realtime analyse, datawarehouse en databases.
Bronnen voor stroomverwerking
De volgende services worden vaak gebruikt voor het opnemen van gegevens voor stroomverwerking in Azure:
- Azure Event Hubs: een service voor gegevensopname die u kunt gebruiken om wachtrijen met gebeurtenisgegevens te beheren, om ervoor te zorgen dat elke gebeurtenis op volgorde wordt verwerkt, precies één keer.
- Azure IoT Hub: Een gegevensopnameservice die vergelijkbaar is met Azure Event Hubs, maar geoptimaliseerd voor het beheren van gebeurtenisgegevens van IoT-apparaten (Internet of Things ).
- Azure Data Lake Store Gen 2: Een zeer schaalbare opslagservice die vaak wordt gebruikt in batchverwerkingsscenario's , maar kan ook worden gebruikt als bron van streaminggegevens.
- Apache Kafka: een opensource-oplossing voor gegevensopname die vaak samen met Apache Spark wordt gebruikt.
Sinks voor stroomverwerking
De uitvoer van stroomverwerking wordt vaak verzonden naar de volgende services:
- Azure Event Hubs: wordt gebruikt om de verwerkte gegevens in de wachtrij te plaatsen voor verdere downstreamverwerking.
- Azure Data Lake Store Gen 2, Microsoft OneLake of Azure Blob Storage: wordt gebruikt om de verwerkte resultaten als een bestand te behouden.
- Azure SQL Database, Azure Databricks of Microsoft Fabric: wordt gebruikt om de verwerkte resultaten in een tabel te behouden voor het uitvoeren van query's en analyses.
- Microsoft Power BI: wordt gebruikt voor het genereren van realtime gegevensvisualisaties in rapporten en dashboards.