Gegevens laden voor verkenning
Het laden en verkennen van gegevens zijn de eerste stappen in een data science-project. Ze hebben betrekking op het begrijpen van de structuur, inhoud en bron van de gegevens, die cruciaal zijn voor latere analyse.
Nadat u verbinding hebt gemaakt met een gegevensbron, kunt u de gegevens opslaan in een Microsoft Fabric Lakehouse. U kunt lakehouse als centrale locatie gebruiken om gestructureerde, semi-gestructureerde en ongestructureerde bestanden op te slaan. U kunt vervolgens eenvoudig verbinding maken met het lakehouse wanneer u toegang wilt tot uw gegevens voor verkenning of transformatie.
Gegevens laden met behulp van notebooks
Notebooks in Microsoft Fabric maken het verwerken van uw gegevensassets eenvoudiger. Zodra uw gegevensassets zich in lakehouse bevinden, kunt u eenvoudig code genereren in het notebook om deze assets op te nemen.
Overweeg een scenario waarin een data engineer al klantgegevens heeft getransformeerd en opgeslagen in lakehouse. Een data scientist kan de gegevens eenvoudig laden met behulp van notebooks voor verdere verkenning om een machine learning-model te bouwen. Dit maakt het mogelijk om onmiddellijk te beginnen, ongeacht of dit aanvullende gegevensmanipulaties, experimentele gegevensanalyse of modelontwikkeling omvat.
Laten we een voorbeeld van een Parquet-bestand maken om de laadbewerking te illustreren. De volgende PySpark-code maakt een dataframe van klantgegevens en schrijft deze naar een Parquet-bestand in lakehouse.
Apache Parquet is een opensource-indeling voor kolomgeoriënteerde gegevensopslag. Het is ontworpen voor efficiënte gegevensopslag en het ophalen, en staat bekend om de hoge prestaties en compatibiliteit met veel frameworks voor gegevensverwerking.
from pyspark.sql import Row
Customer = Row("firstName", "lastName", "email", "loyaltyPoints")
customer_1 = Customer('John', 'Smith', 'john.smith@contoso.com', 15)
customer_2 = Customer('Anna', 'Miller', 'anna.miller@contoso.com', 65)
customer_3 = Customer('Sam', 'Walters', 'sam@contoso.com', 6)
customer_4 = Customer('Mark', 'Duffy', 'mark@contoso.com', 78)
customers = [customer_1, customer_2, customer_3, customer_4]
df = spark.createDataFrame(customers)
df.write.parquet("<path>/customers")
Als u het pad voor uw Parquet-bestand wilt genereren, selecteert u het beletselteken in de Lakehouse-verkenner en kiest u vervolgens ABFS-pad kopiëren of relatief pad kopiëren voor Spark. Als u Python-code schrijft, kunt u de optie File API kopiëren of ABFS-pad kopiëren gebruiken.
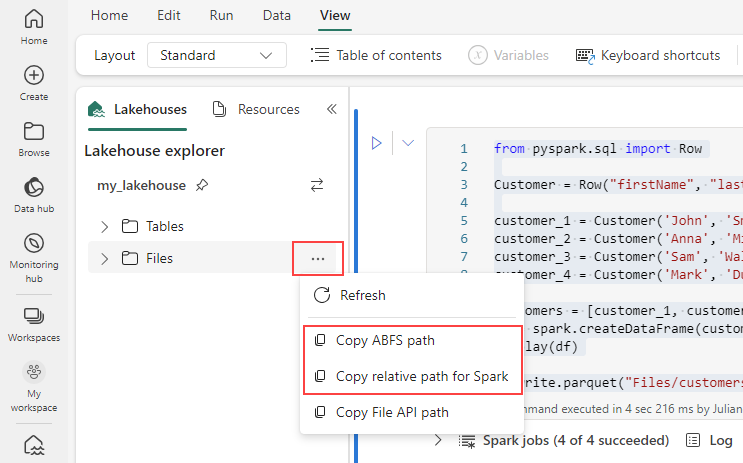
Met de volgende code wordt het Parquet-bestand in een DataFrame geladen.
df = spark.read.parquet("<path>/customers")
display(df)
U kunt ook de code genereren om de gegevens automatisch in het notebook te laden. Kies het gegevensbestand en selecteer Vervolgens Gegevens laden. Daarna moet u de API kiezen die u wilt gebruiken.
Hoewel het parquet-bestand in het vorige voorbeeld is opgeslagen in lakehouse, is het ook mogelijk om gegevens uit externe bronnen, zoals Azure Blob Storage, te laden.
account_name = "<account_name>"
container_name = "<container_name>"
relative_path = "<relative_path>"
sas_token = "<sas_token>"
wasbs = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}?{blob_sas_token}'
df = spark.read.parquet(wasbs)
df.show()
U kunt vergelijkbare stappen volgen om andere bestandstypen, zoals .csv, .jsonen .txt bestanden te laden. Vervang de .parquet methode door de juiste methode voor uw bestandstype, bijvoorbeeld:
# For CSV files
df_csv = spark.read.csv('<path>')
# For JSON files
df_json = spark.read.json('<path>')
# For text files
df_text = spark.read.text('<path>')
Tip
Meer informatie over het opnemen en organiseren van gegevens uit verschillende bronnen met Microsoft Fabric.