Analytische gegevensverwerking verkennen
Analytische gegevensverwerking maakt doorgaans gebruik van systemen met het kenmerk Alleen-lezen (of voornamelijk lezen) waarin grote hoeveelheden historische gegevens of metrische gegevens van het bedrijf worden opgeslagen. Analyses kunnen worden gebaseerd op een momentopname van de gegevens op een bepaald moment, of een reeks momentopnamen.
De specifieke details voor een analyseverwerkingssysteem kunnen variëren tussen oplossingen, maar een algemene architectuur voor analyse op ondernemingsniveau ziet er als volgt uit:
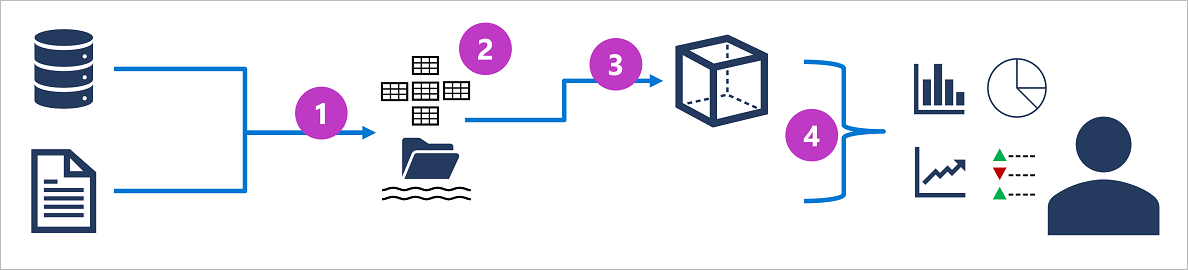
- Operationele gegevens worden geëxtraheerd, getransformeerd en geladen (ETL) in een data lake voor analyse.
- Gegevens worden geladen in een schema van tabellen, meestal in een Data Lakehouse op basis van Spark met tabellaire abstracties over bestanden in de data lake of een datawarehouse met een volledig relationele SQL-engine.
- Gegevens in het datawarehouse kunnen worden samengevoegd en geladen in een OLAP-model (Online Analytical Processing) of kubus. Geaggregeerde numerieke waarden (metingen) uit feitentabellen worden berekend voor snijpunten van dimensietabellen uit dimensietabellen. De omzet kan bijvoorbeeld worden opgeteld op datum, klant en product.
- De gegevens in het data lake- en datawarehouse- en analytische model kunnen worden opgevraagd om rapporten, visualisaties en dashboards te produceren.
Data Lakes zijn gebruikelijk in grootschalige scenario's voor gegevensverwerking, waarbij een groot aantal op bestanden gebaseerde gegevens moet worden verzameld en geanalyseerd.
Datawarehouses zijn een tot stand gebrachte manier om gegevens op te slaan in een relationeel schema dat is geoptimaliseerd voor leesbewerkingen, voornamelijk query's ter ondersteuning van rapportage en gegevensvisualisatie. Data Lakehouses zijn een recentere innovatie die de flexibele en schaalbare opslag van een data lake combineert met de relationele query's op semantiek van een datawarehouse. Het tabelschema vereist mogelijk enige denormalisatie van gegevens in een OLTP-gegevensbron (waarbij een aantal duplicaties worden ingevoerd om query's sneller uit te voeren).
Een OLAP-model is een geaggregeerd type gegevensopslag dat is geoptimaliseerd voor analytische workloads. Gegevensaggregaties bevinden zich in verschillende dimensies op verschillende niveaus, zodat u kunt in- en uitzoomen om aggregaties op meerdere hiërarchische niveaus weer te geven, bijvoorbeeld om de totale verkoop per regio, per plaats of voor een afzonderlijk adres te vinden. Omdat OLAP-gegevens vooraf zijn geaggregeerd, kunnen query's die de samenvattingen retourneren die deze bevat, snel worden uitgevoerd.
Verschillende typen gebruikers kunnen gegevensanalysewerk uitvoeren in verschillende fasen van de algehele architectuur. Voorbeeld:
- Gegevenswetenschappers werken mogelijk rechtstreeks met gegevensbestanden in een data lake om gegevens te verkennen en te modelleren.
- Gegevensanalist s kunnen rechtstreeks in het datawarehouse query's uitvoeren op tabellen om complexe rapporten en visualisaties te produceren.
- Zakelijke gebruikers verbruiken mogelijk vooraf geaggregeerde gegevens in een analytisch model in de vorm van rapporten of dashboards.