Gegevensindelingen identificeren
Gegevens zijn een verzameling feiten, zoals getallen, beschrijvingen en waarnemingen die worden gebruikt om informatie vast te leggen. Gegevensstructuren waarin deze gegevens zijn ingedeeld, vertegenwoordigen vaak entiteiten die belangrijk zijn voor een organisatie (zoals klanten, producten, verkooporders, enzovoort). Elke entiteit heeft doorgaans een of meer kenmerken of kenmerken (een klant kan bijvoorbeeld een naam, een adres, een telefoonnummer enzovoort hebben).
U kunt gegevens classificeren als gestructureerd, semi-gestructureerd of ongestructureerd.
Gestructureerde gegevens
Gestructureerde gegevens zijn gegevens die voldoen aan een vast schema, zodat alle gegevens dezelfde velden of eigenschappen hebben. Meestal is het schema voor gestructureerde gegevensentiteiten tabellair , met andere woorden, de gegevens worden weergegeven in een of meer tabellen die bestaan uit rijen die elk exemplaar van een gegevensentiteit vertegenwoordigen en kolommen die kenmerken van de entiteit vertegenwoordigen. In de volgende afbeelding ziet u bijvoorbeeld tabelgegevensweergaven voor klant- en productentiteiten.
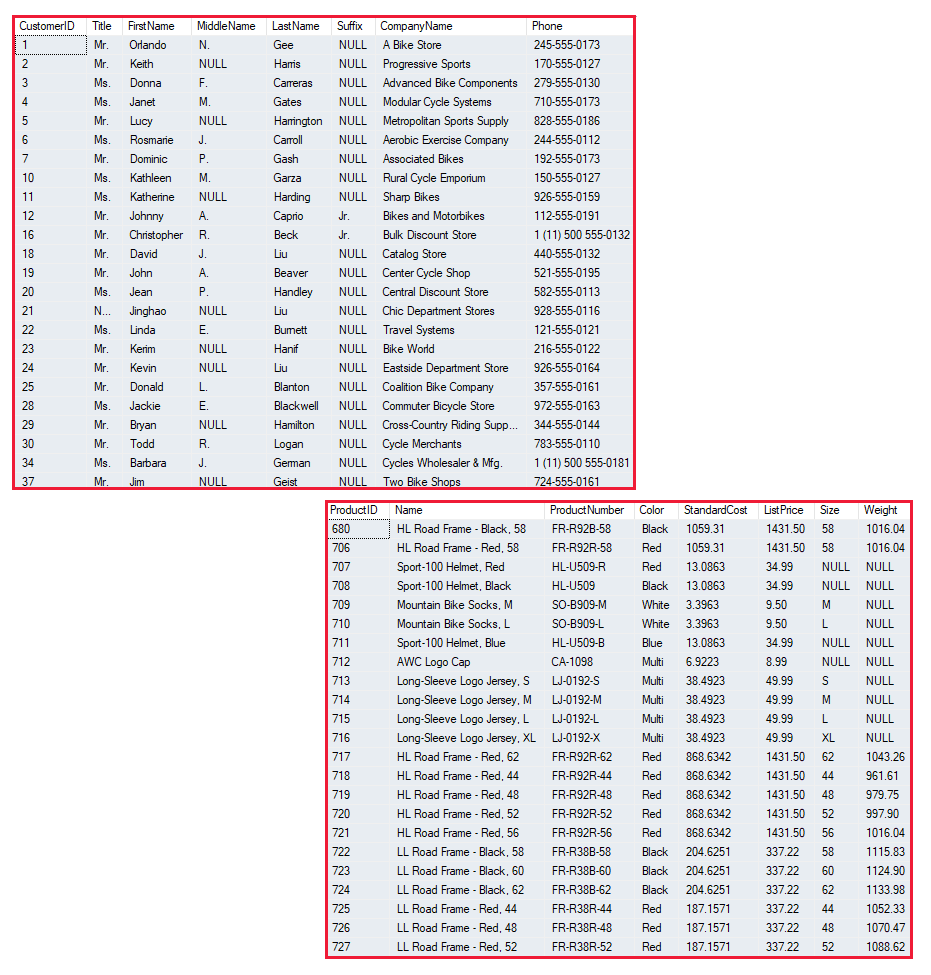
Gestructureerde gegevens worden vaak opgeslagen in een database waarin meerdere tabellen naar elkaar kunnen verwijzen met behulp van sleutelwaarden in een relationeel model. Deze worden later uitgebreider besproken.
Semi-gestructureerde gegevens
Semi-gestructureerde gegevens zijn informatie die een bepaalde structuur heeft, maar die enige variatie tussen entiteitsexemplaren mogelijk maakt. Hoewel de meeste klanten bijvoorbeeld een e-mailadres hebben, kunnen sommige meerdere e-mailadressen hebben en sommige hebben helemaal geen e-mailadressen.
Een algemene indeling voor semi-gestructureerde gegevens is JavaScript Object Notation (JSON). In het onderstaande voorbeeld ziet u een paar JSON-documenten die klantgegevens vertegenwoordigen. Elk klantdocument bevat adres- en contactgegevens, maar de specifieke velden verschillen per klant.
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
// Customer 2
{
"firstName": "Samir",
"lastName": "Nadoy",
"address":
{
"streetAddress": "123 Elm Pl.",
"unit": "500",
"city": "Seattle",
"state": "WA",
"postalCode": "98999"
},
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
Notitie
JSON is slechts een van de vele manieren waarop semi-gestructureerde gegevens kunnen worden weergegeven. Het punt hier is niet om een gedetailleerd onderzoek van de JSON-syntaxis te geven, maar om de flexibele aard van semi-gestructureerde gegevensweergaven te illustreren.
Niet-gestructureerd gegevens
Niet alle gegevens zijn gestructureerd of zelfs semi-gestructureerd. Documenten, afbeeldingen, audio- en videogegevens en binaire bestanden hebben bijvoorbeeld mogelijk geen specifieke structuur. Dit soort gegevens wordt ongestructureerde gegevens genoemd.

Gegevensopslag
Organisaties slaan doorgaans gegevens op in gestructureerde, semi-gestructureerde of ongestructureerde indeling om details van entiteiten (bijvoorbeeld klanten en producten), specifieke gebeurtenissen (zoals verkooptransacties) of andere informatie in documenten, afbeeldingen en andere indelingen vast te leggen. De opgeslagen gegevens kunnen vervolgens later worden opgehaald voor analyse en rapportage.
Er zijn twee algemene categorieën gegevensarchieven die algemeen worden gebruikt:
- Bestandsarchieven
- Databases
In volgende onderwerpen gaan we beide typen gegevensarchieven verkennen.