Een MLOps-architectuur verkennen
Als data scientist wilt u het beste machine learning-model trainen. Als u het model wilt implementeren, wilt u het implementeren op een eindpunt en integreren met een toepassing.
Na verloop van tijd wilt u het model mogelijk opnieuw trainen. U kunt het model bijvoorbeeld opnieuw trainen wanneer u meer trainingsgegevens hebt.
Over het algemeen wilt u, nadat u een machine learning-model hebt getraind, het model voorbereiden op ondernemingsniveau. Als u het model wilt voorbereiden en operationeel wilt maken, wilt u het volgende doen:
- Converteer de modeltraining naar een robuuste en reproduceerbare pijplijn.
- Test de code en het model in een ontwikkelomgeving .
- Implementeer het model in een productieomgeving .
- Automatiseer het end-to-end-proces.
Omgevingen instellen voor ontwikkeling en productie
In MLOps, vergelijkbaar met DevOps, verwijst een omgeving naar een verzameling resources. Deze resources worden gebruikt om een toepassing of met machine learning-projecten te implementeren om een model te implementeren.
Notitie
In deze module verwijzen we naar de DevOps-interpretatie van omgevingen. Azure Machine Learning maakt ook gebruik van de termenomgevingen om een verzameling Python-pakketten te beschrijven die nodig zijn om een script uit te voeren. Deze twee concepten van omgevingen zijn onafhankelijk van elkaar.
Hoeveel omgevingen u gebruikt, is afhankelijk van uw organisatie. Meestal zijn er ten minste twee omgevingen: ontwikkeling of ontwikkeling en productie of prod. Bovendien kunt u omgevingen toevoegen tussen een faserings- of preproductieomgeving (pre-prod).
Een typische benadering is het volgende:
- Experimenteer met modeltraining in de ontwikkelomgeving .
- Verplaats het beste model naar de faserings - of pre-prod-omgeving om het model te implementeren en te testen.
- Laat ten slotte het model los in de productieomgeving om het model te implementeren, zodat eindgebruikers het kunnen gebruiken.
Azure Machine Learning-omgevingen organiseren
Wanneer u MLOps implementeert en op grote schaal met machine learning-modellen werkt, is het een best practice om te werken met afzonderlijke omgevingen voor verschillende fasen.
Stel dat uw team gebruikmaakt van een ontwikkel-, pre-prod- en prod-omgeving. Niet iedereen in uw team moet toegang krijgen tot alle omgevingen. Gegevenswetenschappers werken mogelijk alleen in de ontwikkelomgeving met niet-productiegegevens, terwijl machine learning-technici werken aan het implementeren van het model in de pre-prod- en prod-omgeving met productiegegevens.
Door afzonderlijke omgevingen te hebben, is het eenvoudiger om de toegang tot resources te beheren. Elke omgeving kan vervolgens worden gekoppeld aan een afzonderlijke Azure Machine Learning-werkruimte.
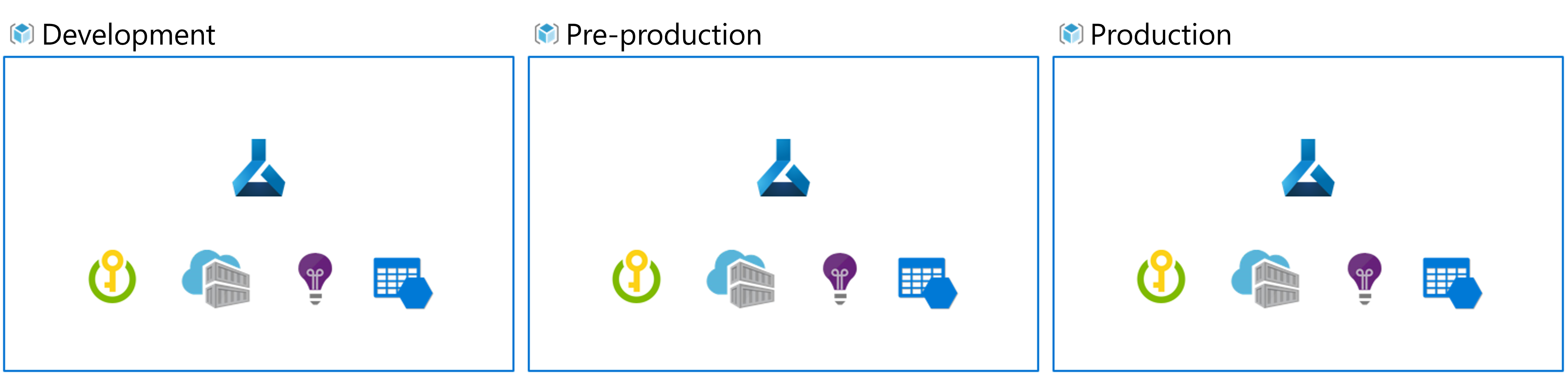
In Azure gebruikt u op rollen gebaseerd toegangsbeheer (RBAC) om collega's het juiste toegangsniveau te geven tot de subset van resources waarmee ze moeten werken.
U kunt ook slechts één Azure Machine Learning-werkruimte gebruiken. Wanneer u één werkruimte gebruikt voor ontwikkeling en productie, hebt u een kleinere Azure-footprint en minder beheeroverhead. RBAC is echter van toepassing op zowel ontwikkel- als prod-omgevingen, wat kan betekenen dat u mensen te weinig of te veel toegang geeft tot resources.
Tip
Meer informatie over aanbevolen procedures voor het organiseren van Azure Machine Learning-resources.
Een MLOps-architectuur ontwerpen
Door een model in productie te brengen, moet u uw oplossing schalen en samenwerken met andere teams. Samen met andere gegevenswetenschappers, data engineers en een infrastructuurteam kunt u besluiten om de volgende aanpak te gebruiken:
- Sla alle gegevens op in een Azure Blob-opslag die wordt beheerd door de data engineer.
- Het infrastructuurteam maakt alle benodigde Azure-resources, zoals de Azure Machine Learning-werkruimte.
- Gegevenswetenschappers richten zich op wat ze het beste doen: het model ontwikkelen en trainen (interne lus).
- Machine learning-technici implementeren de getrainde modellen (outer loop).
Als gevolg hiervan bevat uw MLOps-architectuur de volgende onderdelen:
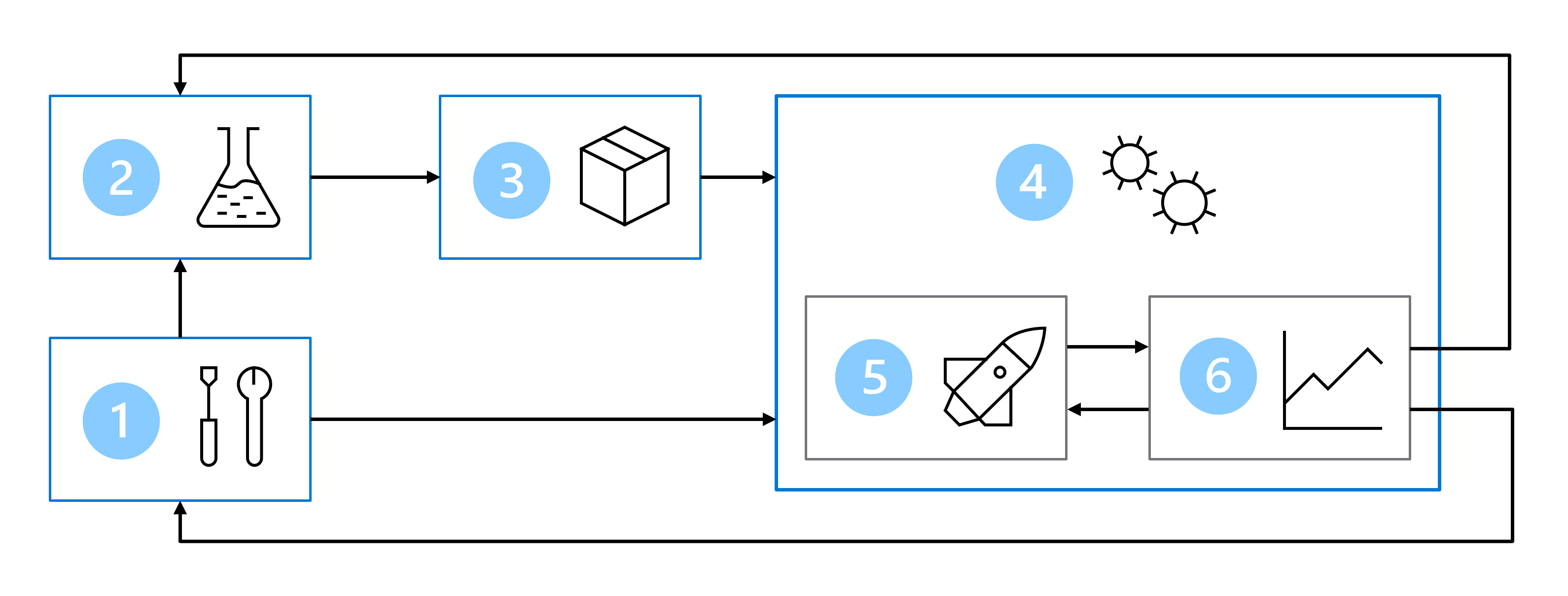
- Installatie: Maak alle benodigde Azure-resources voor de oplossing.
- Modelontwikkeling (interne lus): de gegevens verkennen en verwerken om het model te trainen en te evalueren.
- Continue integratie: het model verpakken en registreren.
- Modelimplementatie (outer loop): implementeer het model.
- Continue implementatie: test het model en promoot het naar de productieomgeving.
- Bewaking: model- en eindpuntprestaties bewaken.
Wanneer u met grotere teams werkt, bent u waarschijnlijk niet verantwoordelijk voor alle onderdelen van de MLOps-architectuur als data scientist. Als u uw model echter wilt voorbereiden voor MLOps, moet u nadenken over het ontwerpen voor bewaking en opnieuw trainen.