Deductieworkload uitvoeren op NVIDIA Triton Inference Server
Nu zijn we klaar om het Python-voorbeeldscript uit te voeren op de Triton-server. Als u in de demo map kijkt, ziet u een verzameling mappen en bestanden.
In de demo/app map bevinden zich twee Python-scripts. De eerste, frame_grabber.py maakt gebruik van de Triton Inference Server. De tweede, frame_grabber_onnxruntime.py kan op zelfstandige wijze worden gebruikt. De utils map in de app map bevat Python-scripts om de interpretatie van de uitvoertenor van het model mogelijk te maken.
Beide Python-scripts zijn ingesteld om de image_sink map te bekijken voor installatiekopieën die daar zijn geplaatst. In de images-sample, vindt u een verzameling afbeeldingen die we kopiëren via de opdrachtregel naar de image_sink voor verwerking. De Python-scripts verwijderen automatisch de bestanden uit de image_sink nadat de deductie is voltooid.
In de model-repo map vindt u een map voor de naam van het model (gtc_onnx), dat het modelconfiguratiebestand voor de Triton-deductieserver en het labelbestand bevat. Ook opgenomen is een map die de versie van het model aangeeft, die het ONNX-model (Open Neural Network Exchange) bevat dat door de server wordt gebruikt om deductie uit te voeren.
Als het model de objecten detecteert waarop het is getraind, maakt het Python-script een aantekening van die deductie met een begrenzingsvak, tagnaam en betrouwbaarheidsscore. Het script slaat de afbeelding op in de images-annotated map met een unieke naam met behulp van een tijdstempel, die we kunnen downloaden om lokaal weer te geven. Op die manier kunt u dezelfde afbeeldingen steeds opnieuw kopiëren naar de image_sink maar nieuwe geannoteerde afbeeldingen hebben gemaakt die elke uitvoering voor illustratiedoeleinden zijn gemaakt.
Een deductieworkload uitvoeren op NVIDIA Triton Inference Server
Om aan de slag te gaan met de deductie, willen we twee vensters openen in de Windows Terminal en
sshin de virtuele machine vanuit elk venster.Voer in het eerste venster de volgende opdracht uit, maar wijzig eerst de tijdelijke aanduiding voor uw <gebruikersnaam> met uw gebruikersnaam voor de virtuele machine:
sudo docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --rm -p8000:8000 -p8002:8002 -v/home/<your username>/demo/model-repo:/models nvcr.io/nvidia/tritonserver:20.11-py3 tritonserver --model-repository=/modelsKopieer in het tweede venster de volgende opdracht, wijzig uw gebruikersnaam> in uw waarde en stel de< waarschijnlijkheidsdrempel> in op het gewenste betrouwbaarheidsniveau tussen 0 en 1.< Deze waarde is standaard ingesteld op 0,6.
python3 demo/app/frame_grabber.py -u <your username> -p .07Kopieer en plak deze opdracht in het derde venster om de afbeeldingsbestanden van de
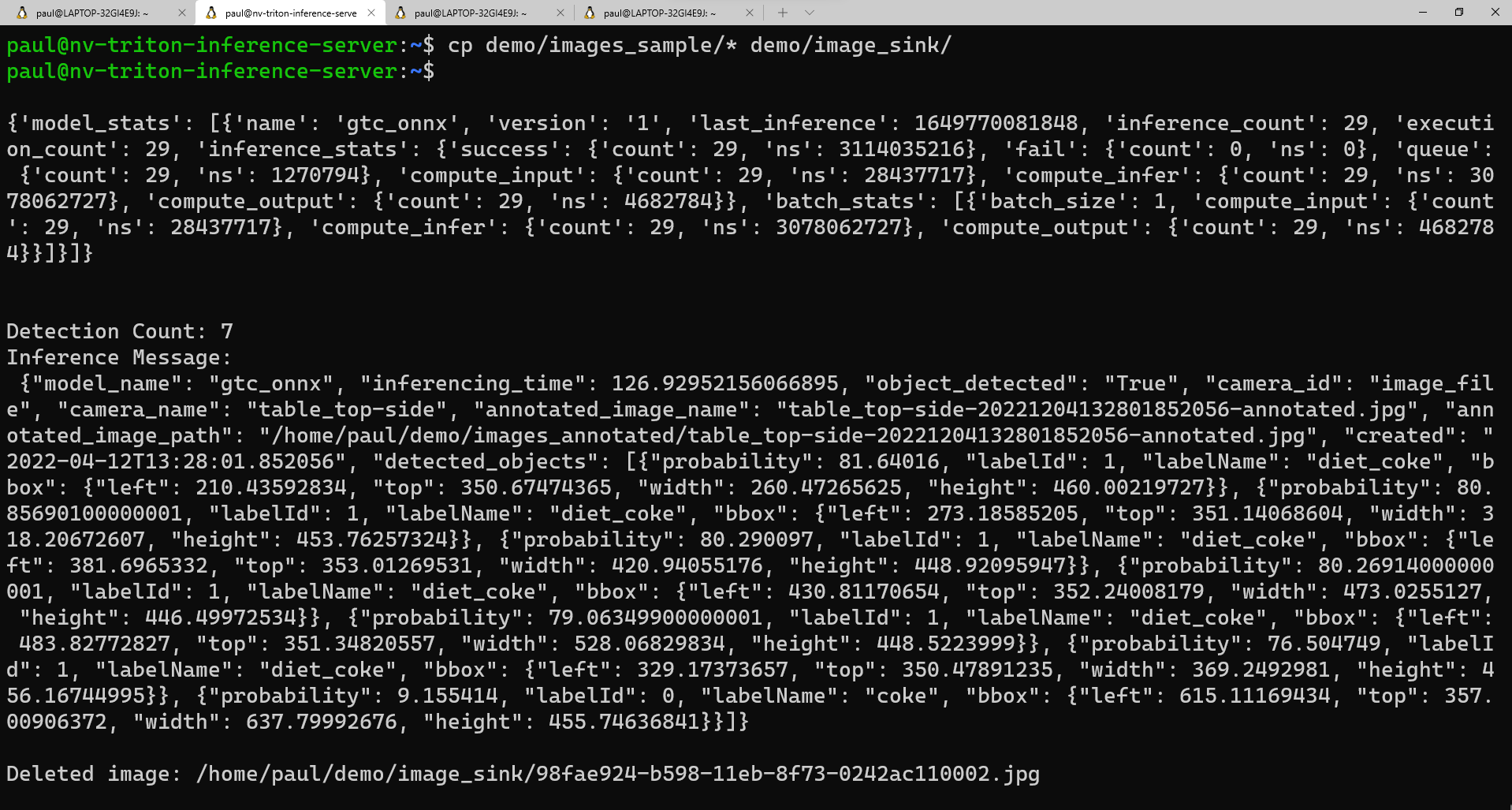
images_samplemap naar deimage_sinkmap te kopiëren:cp demo/images_sample/* demo/image_sink/Als u teruggaat naar het tweede venster, ziet u de uitvoering van het model, inclusief de modelstatistieken en de geretourneerde deductie in de vorm van een Python-woordenlijst.
Hier volgt een voorbeeldweergave van wat u in het tweede venster zou moeten zien terwijl het script wordt uitgevoerd:
Als u een lijst met uw geannoteerde afbeeldingen wilt zien, kunt u deze opdracht uitvoeren:
ls demo/annotated_imagesAls u de installatiekopieën naar uw lokale computer wilt downloaden, willen we eerst een map maken om de installatiekopieën te ontvangen. Ga in een opdrachtregelvenster
cdnaar de map waarin u de nieuwe map wilt plaatsen en voer het volgende uit:mkdir annotated_img_download scp <your usename>@x.x.x.x:/home/<your username>/demo/images_annotated/* annotated_img_download/Met deze opdracht worden alle bestanden van de virtuele Ubuntu-machine gekopieerd naar uw lokale apparaat voor weergave.
