Batch-eindpunten aanroepen en problemen oplossen
Wanneer u een batch-eindpunt aanroept, activeert u een Azure Machine Learning-pijplijntaak. Voor de taak wordt een invoerparameter verwacht die verwijst naar de gegevensset die u wilt scoren.
De batchscoretaak activeren
Als u gegevens wilt voorbereiden voor batchvoorspellingen, kunt u een map registreren als een gegevensasset in de Azure Machine Learning-werkruimte.
U kunt vervolgens de geregistreerde gegevensasset als invoer gebruiken bij het aanroepen van het batch-eindpunt met de Python SDK:
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes
input = Input(type=AssetTypes.URI_FOLDER, path="azureml:new-data:1")
job = ml_client.batch_endpoints.invoke(
endpoint_name=endpoint.name,
input=input)
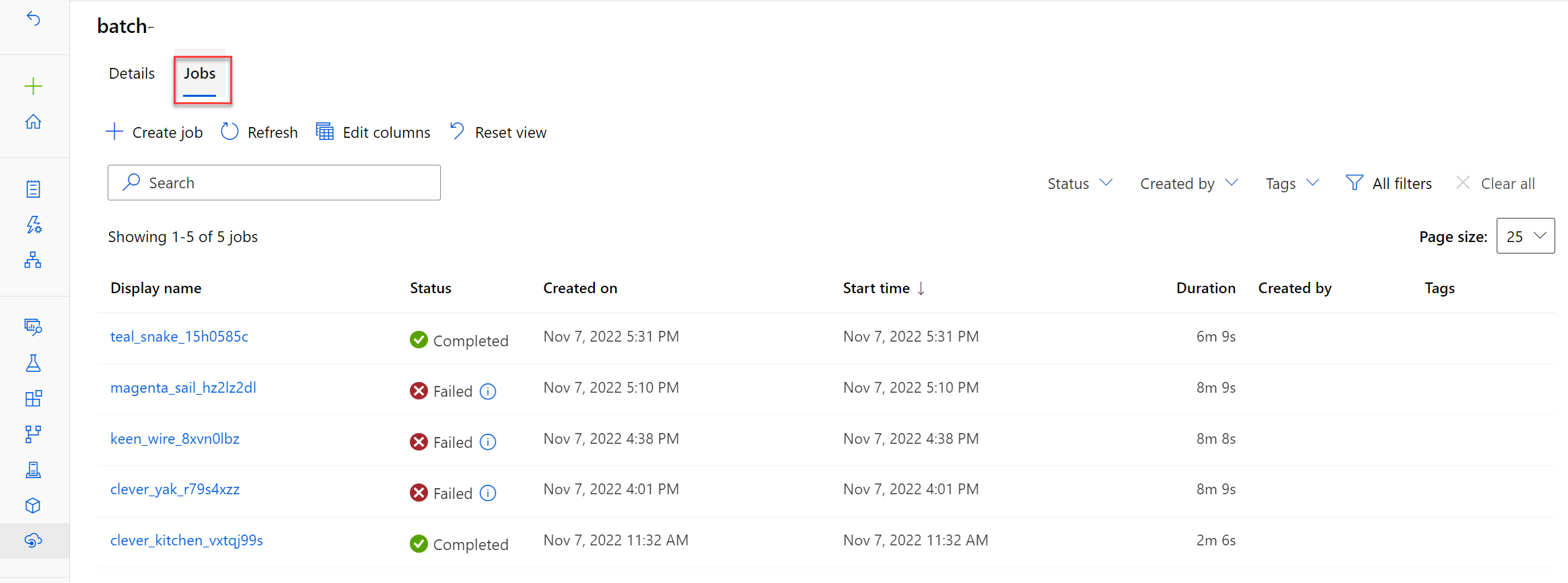
U kunt de uitvoering van de pijplijntaak in de Azure Machine Learning-studio controleren. Alle taken die worden geactiveerd door het batch-eindpunt aan te roepen, worden weergegeven op het tabblad Taken van het batch-eindpunt.
De voorspellingen worden opgeslagen in het standaardgegevensarchief.
Problemen met een batchscoretaak oplossen
De batchscoretaak wordt uitgevoerd als een pijplijntaak. Als u problemen met de pijplijntaak wilt oplossen, kunt u de details en de uitvoer en logboeken van de pijplijntaak zelf bekijken.
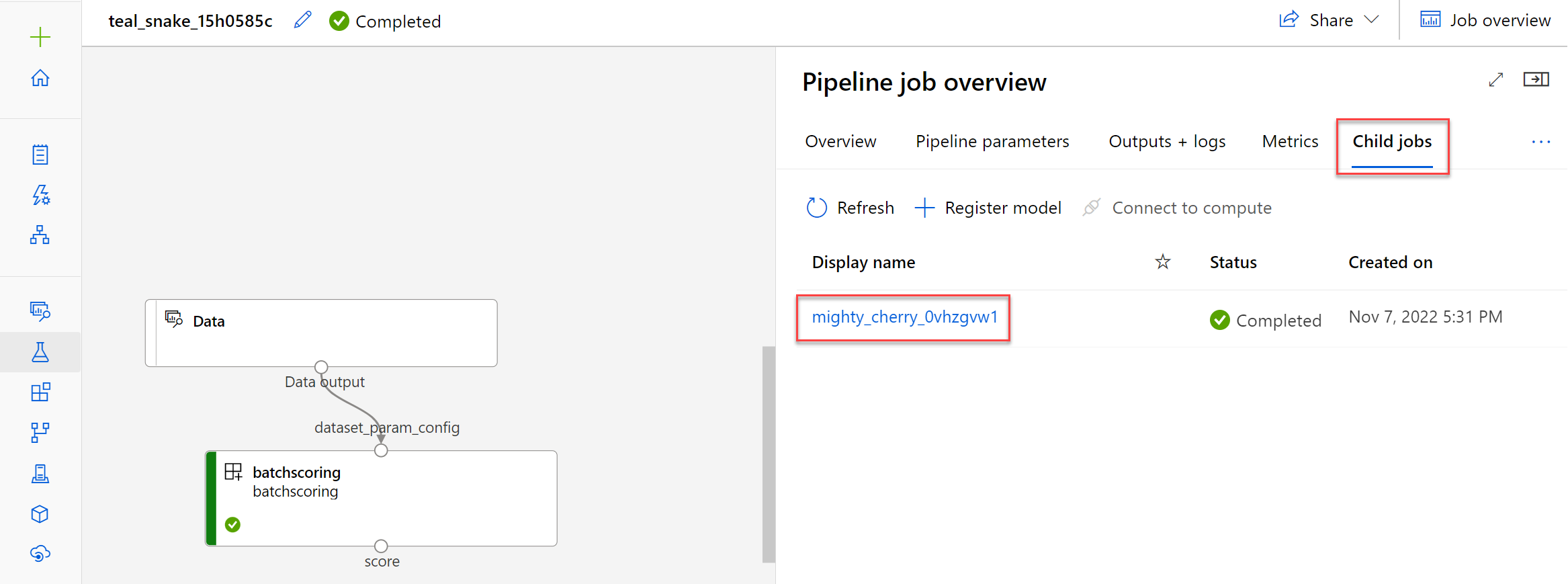
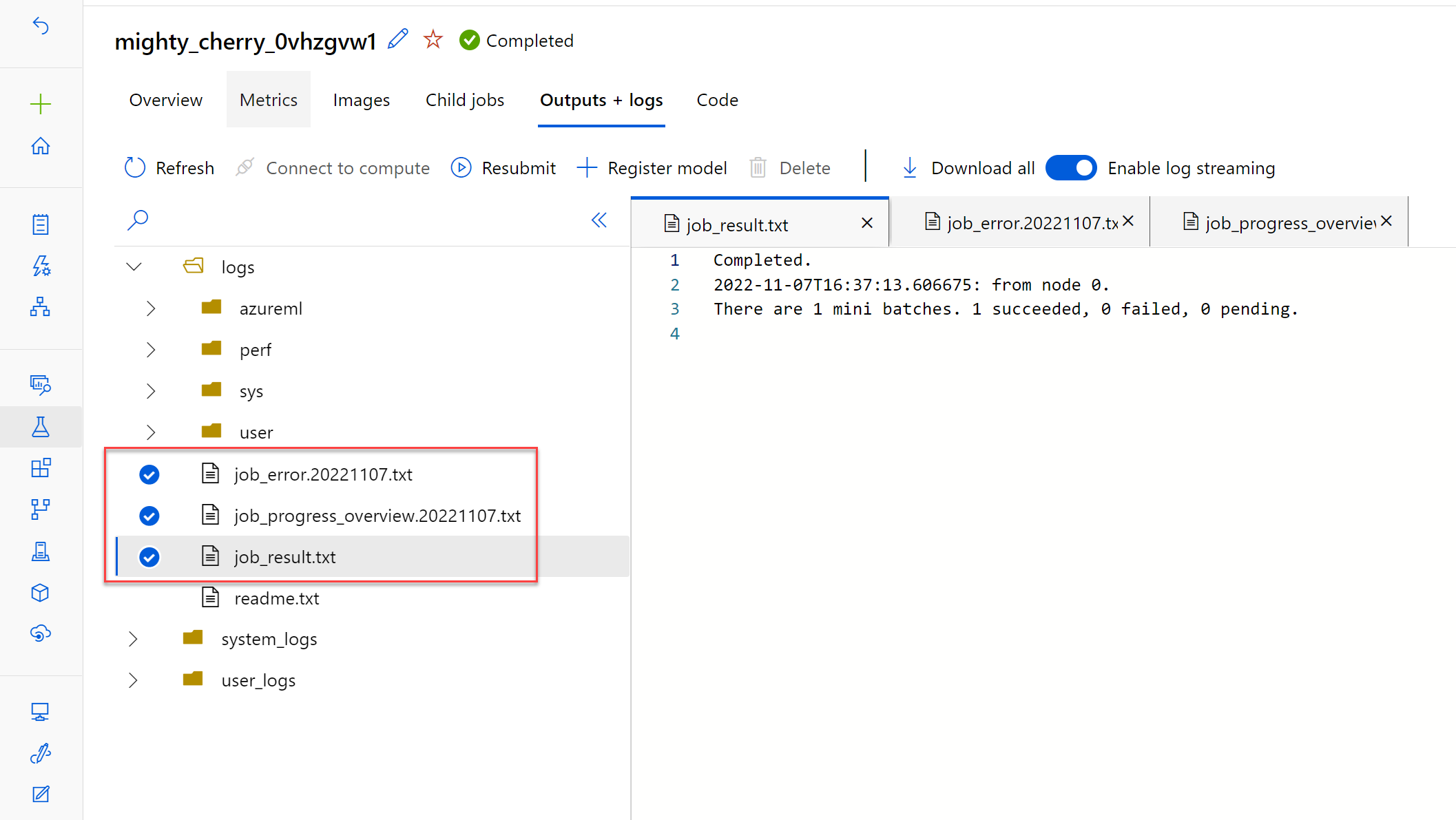
Als u problemen met het scorescript wilt oplossen, kunt u de onderliggende taak selecteren en de uitvoer en logboeken ervan bekijken.
Navigeer naar het tabblad Uitvoer en logboeken . De logboeken/gebruiker/ map bevat drie bestanden waarmee u problemen kunt oplossen:
job_error.txt: De fouten in uw script samenvatten.job_progress_overview.txt: biedt informatie op hoog niveau over het aantal minibatches dat tot nu toe is verwerkt.job_result.txt: Toont fouten bij het aanroepen van deinit()enrun()functie in het scorescript.