Batch-eindpunten begrijpen en maken
Als u een model wilt ophalen voor het genereren van batchvoorspellingen, kunt u het model implementeren in een batch-eindpunt.
U leert hoe u batch-eindpunten gebruikt voor asynchrone batchgewijs scoren.
Batch-voorspellingen
Als u batchvoorspellingen wilt ophalen, kunt u een model implementeren op een eindpunt. Een eindpunt is een HTTPS-eindpunt dat u kunt aanroepen om een batchscoretaak te activeren. Het voordeel van een dergelijk eindpunt is dat u de batchscoretaak kunt activeren vanuit een andere service, zoals Azure Synapse Analytics of Azure Databricks. Met een batch-eindpunt kunt u de batchscore integreren met een bestaande pijplijn voor gegevensopname en transformatie.
Wanneer het eindpunt wordt aangeroepen, wordt een batchscoretaak verzonden naar de Azure Machine Learning-werkruimte. De taak maakt doorgaans gebruik van een rekencluster om meerdere invoerwaarden te scoren. De resultaten kunnen worden opgeslagen in een gegevensarchief dat is verbonden met de Azure Machine Learning-werkruimte.
Een batch-eindpunt maken
Als u een model wilt implementeren in een batch-eindpunt, moet u eerst het batch-eindpunt maken.
Als u een batch-eindpunt wilt maken, gebruikt u de BatchEndpoint klasse. Namen van Batch-eindpunten moeten uniek zijn binnen een Azure-regio.
Gebruik de volgende opdracht om een eindpunt te maken:
# create a batch endpoint
endpoint = BatchEndpoint(
name="endpoint-example",
description="A batch endpoint",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint)
Tip
Bekijk de referentiedocumentatie om een batch-eindpunt te maken met de Python SDK v2.
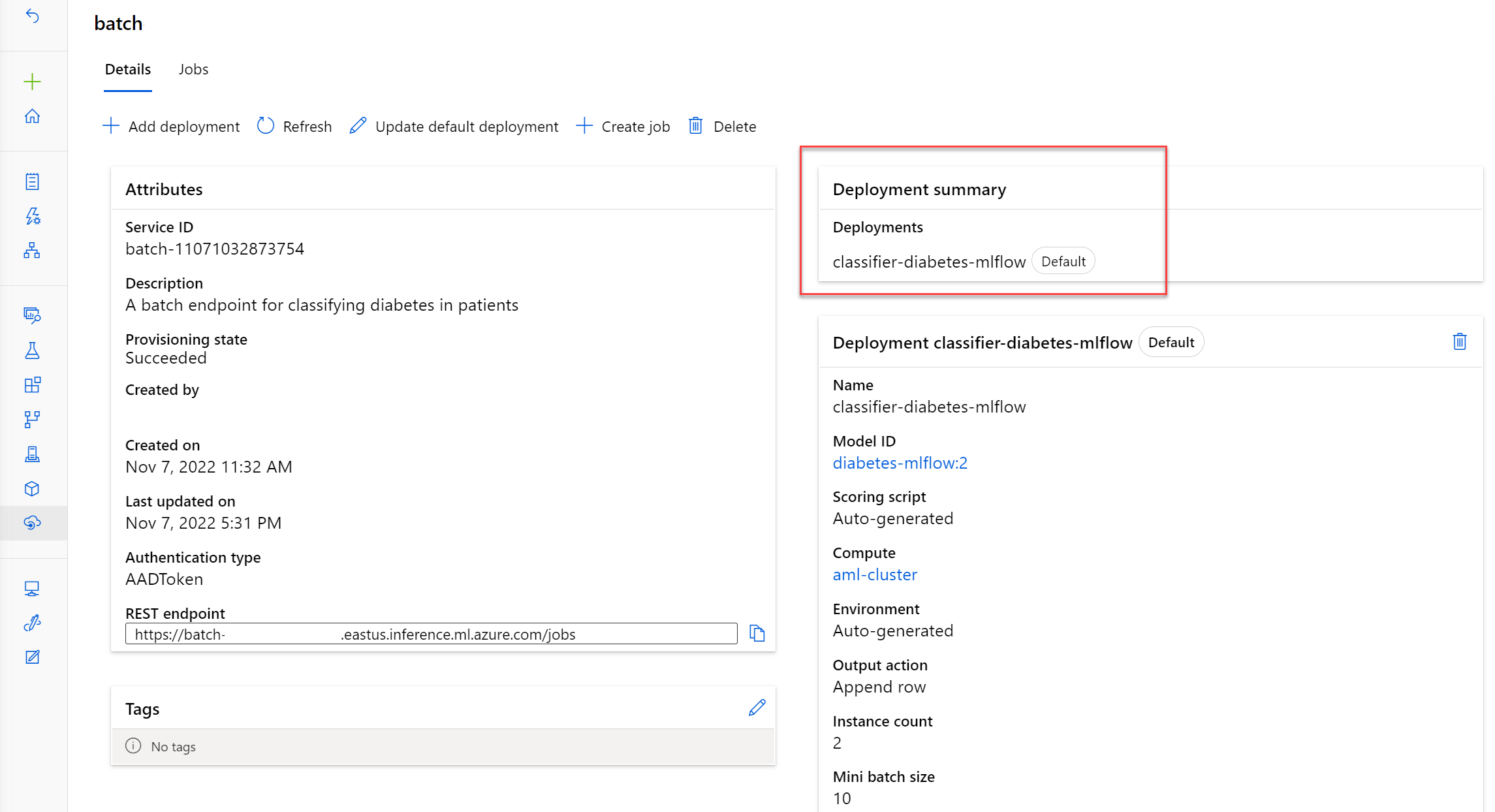
Een model implementeren in een batch-eindpunt
U kunt meerdere modellen implementeren in een batch-eindpunt. Wanneer u het batch-eindpunt aanroept, waardoor een batchscoretaak wordt geactiveerd, wordt de standaardimplementatie gebruikt, tenzij anders is opgegeven.
Rekenclusters gebruiken voor batchimplementaties
De ideale rekenkracht voor batchimplementaties is het Azure Machine Learning-rekencluster. Als u wilt dat de batchscoretaak de nieuwe gegevens in parallelle batches verwerkt, moet u een rekencluster inrichten met meer dan één maximumexemplaren.
Als u een rekencluster wilt maken, kunt u de AMLCompute klasse gebruiken.
from azure.ai.ml.entities import AmlCompute
cpu_cluster = AmlCompute(
name="aml-cluster",
type="amlcompute",
size="STANDARD_DS11_V2",
min_instances=0,
max_instances=4,
idle_time_before_scale_down=120,
tier="Dedicated",
)
cpu_cluster = ml_client.compute.begin_create_or_update(cpu_cluster)