Inzicht in deep learning-concepten
In je hersenen heb je zenuwcellen genaamd neuronen, die met elkaar verbonden zijn door zenuwextensies die elektrochemische signalen doorgeven via het netwerk.

Wanneer de eerste neuron in het netwerk wordt gestimuleerd, wordt het invoersignaal verwerkt en als het een bepaalde drempelwaarde overschrijdt, wordt de neuron geactiveerd en wordt het signaal doorgegeven aan de neuronen waarmee het is verbonden. Deze neuronen kunnen op hun beurt worden geactiveerd en het signaal doorgeven via de rest van het netwerk. Na verloop van tijd worden de verbindingen tussen de neuronen versterkt door frequent gebruik wanneer u leert hoe u effectief kunt reageren. Als u bijvoorbeeld een foto van een pinguïn ziet, kunt u met uw neuronverbindingen de informatie in de afbeelding en uw kennis van de kenmerken van een pinguïn verwerken om deze als zodanig te identificeren. Als u na verloop van tijd meerdere foto's van verschillende dieren ziet, wordt het netwerk van neuronen die betrokken zijn bij het identificeren van dieren op basis van hun kenmerk sterker worden. Met andere woorden, je kunt beter verschillende dieren nauwkeurig identificeren.
Deep Learning emuleert dit biologische proces met behulp van kunstmatige neurale netwerken die numerieke invoer verwerken in plaats van elektrochemische prikkels.
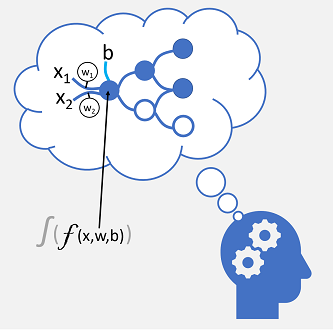
De binnenkomende zenuwverbindingen worden vervangen door numerieke invoer die doorgaans wordt aangeduid als x. Wanneer er meer dan één invoerwaarde is, wordt x beschouwd als een vector met elementen met de naam x1, x2 enzovoort.
Gekoppeld aan elke x-waarde is een gewicht (w), dat wordt gebruikt om het effect van de x-waarde te versterken of te verzwakken om leren te simuleren. Daarnaast wordt een bias-invoer (b) toegevoegd om nauwkeurige controle over het netwerk mogelijk te maken. Tijdens het trainingsproces worden de w - en b-waarden aangepast om het netwerk af te stemmen, zodat het 'leert' juiste uitvoer te produceren.
De neuron zelf bevat een functie die een gewogen som van x, w en b berekent. Deze functie bevindt zich op zijn beurt in een activeringsfunctie die het resultaat beperkt (vaak tot een waarde tussen 0 en 1) om te bepalen of de neuron een uitvoer doorgeeft aan de volgende laag neuronen in het netwerk.
Een Deep Learning-model trainen
Deep Learning-modellen zijn neurale netwerken die bestaan uit meerdere lagen kunstmatige neuronen. Elke laag vertegenwoordigt een set functies die worden uitgevoerd op de x-waarden met gekoppelde w-gewichten en bases , en de laatste laagresultaten op een uitvoer van het y-label dat het model voorspelt. In het geval van een classificatiemodel (dat de meest waarschijnlijke categorie of klasse voor de invoergegevens voorspelt), is de uitvoer een vector die de waarschijnlijkheid voor elke mogelijke klasse bevat.
Het volgende diagram vertegenwoordigt een Deep Learning-model dat de klasse van een gegevensentiteit voorspelt op basis van vier functies (de x-waarden). De uitvoer van het model (de y-waarden ) is de waarschijnlijkheid voor elk van de drie mogelijke klasselabels.
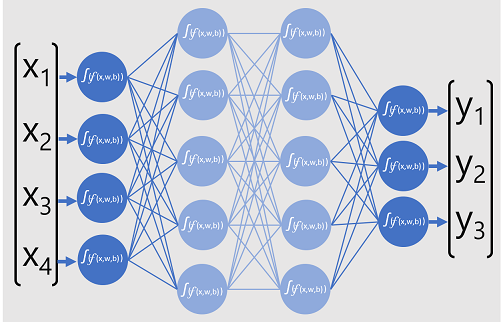
Als u het model wilt trainen, voert een Deep Learning-framework meerdere batches invoergegevens (waarvoor de werkelijke labelwaarden bekend zijn) toe, past u de functies in alle netwerklagen toe en meet u het verschil tussen de uitvoerkansen en de werkelijke bekende klassenlabels van de trainingsgegevens. Het geaggregeerde verschil tussen de voorspellingsuitvoer en de werkelijke labels wordt het verlies genoemd.
Nadat u het cumulatieve verlies voor alle batches met gegevens hebt berekend, gebruikt het Deep Learning-framework een optimizer om te bepalen hoe de gewichten en vooroordelen in het model moeten worden aangepast om het totale verlies te verminderen. Deze aanpassingen worden vervolgens teruggepropageerd aan de lagen in het neurale netwerkmodel, waarna de gegevens opnieuw via het netwerk worden doorgegeven en het verlies opnieuw wordt berekend. Dit proces herhaalt meerdere keren (elke iteratie wordt een epoch genoemd) totdat het verlies wordt geminimaliseerd en het model de juiste gewichten en vooroordelen heeft geleerd om nauwkeurig te kunnen voorspellen.
Tijdens elke periode worden de gewichten en vooroordelen aangepast om het verlies te minimaliseren. Het bedrag waarop ze worden aangepast, wordt bepaald door het leerpercentage dat u opgeeft voor de optimalisatie. Als de leersnelheid te laag is, kan het trainingsproces lang duren om optimale waarden te bepalen; maar als deze te hoog is, kan de optimalisatie nooit de optimale waarden vinden.