Een Azure Machine Learning-gegevenslabelproject maken
Een veelvoorkomende taak bij het ontwikkelen van een aangepast objectdetectiemodel is de noodzaak om niet-gelabelde afbeeldingsgegevens te verwerken, zodat deze kunnen worden geconverteerd naar een gelabelde gegevensset voor modeltraining en validatiedoeleinden. Niet-gelabelde gegevens bevatten vaak verschillende voorbeelden die het type gegevens weerspiegelen dat zou worden vastgelegd op de site waar het objectdetectiemodel moet worden gebruikt. Deze gegevens kunnen subtiele transformaties bevatten, bijvoorbeeld de introductie van 'ruis' in de afbeeldingsgegevens om een robuustere trainingsset te produceren. Met Azure Machine Learning Data Tools in Azure Machine Learning-studio kunnen teams hun verzamelingen niet-gelabelde gegevens beheren in gelabelde gegevenssets die geschikt zijn voor de klassen die worden gedetecteerd door het getrainde objectdetectiemodel.
Een Azure Machine Learning-gegevenslabelproject maken
Als u de Azure Machine Learning-studio nog niet hebt gestart vanuit het Machine Learning-overzicht dat aan het einde van de vorige sectie is vermeld, meldt u zich nu aan bij Azure Machine Learning-studio en selecteert u uw werkruimte.
Zoek in het linkerdeelvenster de sectie Beheren en selecteer Gegevenslabeling.
Selecteer + Maken in het resulterende scherm.
Geef in de sectie Projectdetails een naam op die specifiek is voor de betreffende detectietaak en selecteer Objectidentificatie (Begrenzingsvak) in het menu en selecteer Vervolgens.

In het scherm Personeel toevoegen (optioneel) laten we de optie uitgeschakeld en selecteert u Volgende om door te gaan.
Wanneer u wordt gevraagd om een gegevensset te selecteren of te maken, kiest u +Gegevensset maken en selecteert u de optie Uit gegevensarchief.
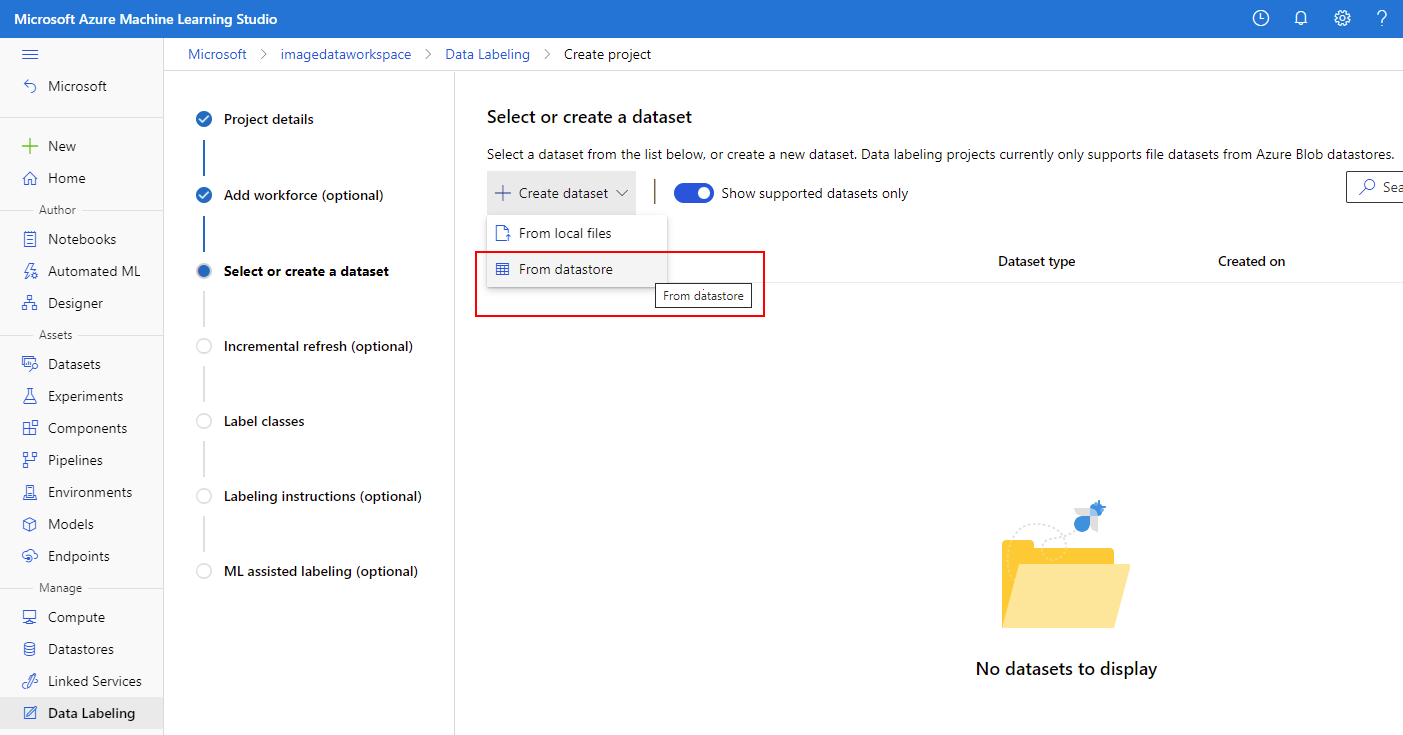
Geef uw nieuwe gegevensset de unieke naam, bijvoorbeeld sodaObjects die de afbeeldingen weerspiegelen die zijn vastgelegd ter ondersteuning van de detectietaak en selecteer Volgende.
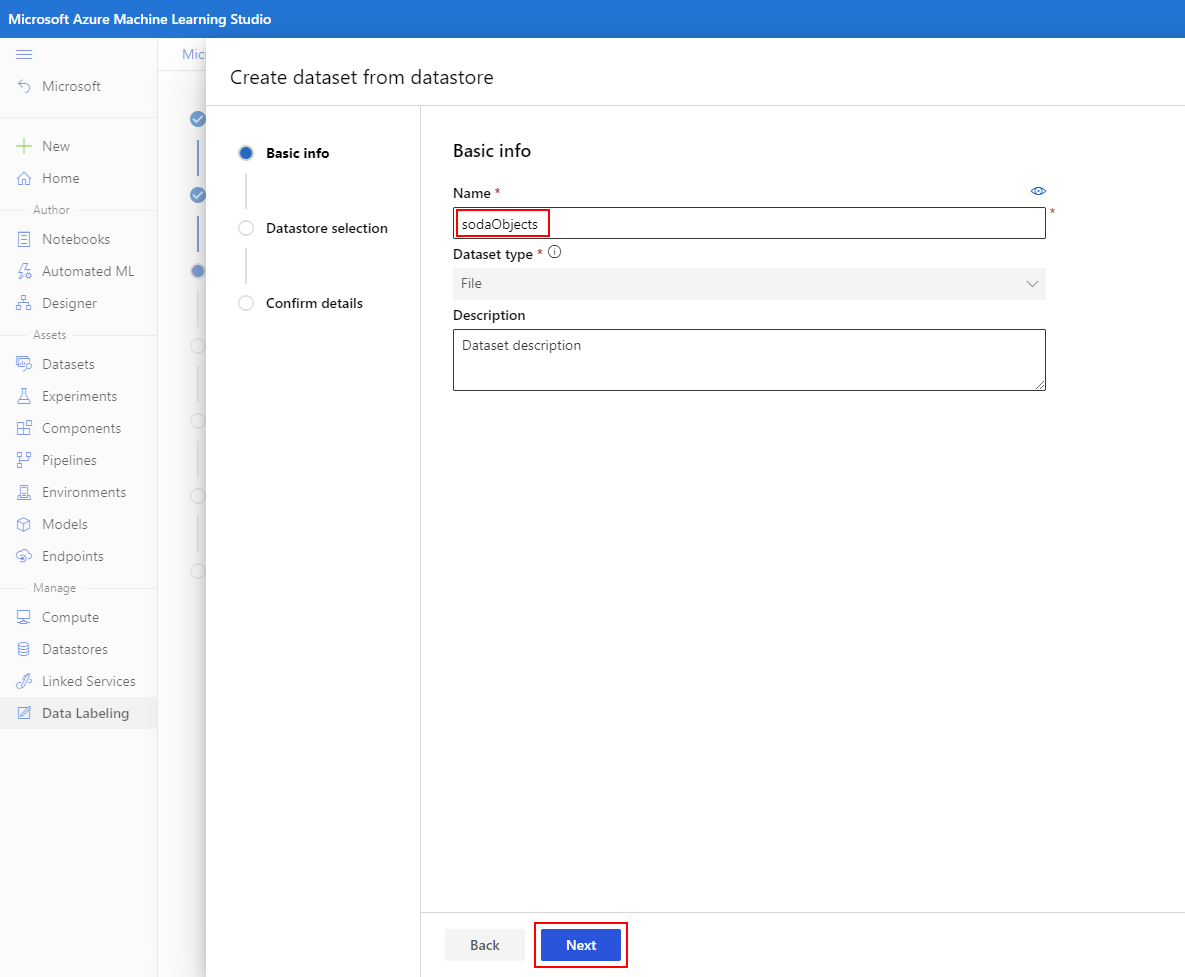
Kies onder Gegevensarchief de naam van het gegevensarchief die u eerder hebt toegevoegd, die de niet-gemarkeerde afbeeldingsgegevens bevat. Hier kunt u ook een jokertekenpad opgeven als u alleen installatiekopieën van opgegeven partities wilt ophalen. Als u alle installatiekopieën uit de container wilt ophalen, voert u /als pad in en selecteert u Volgende.
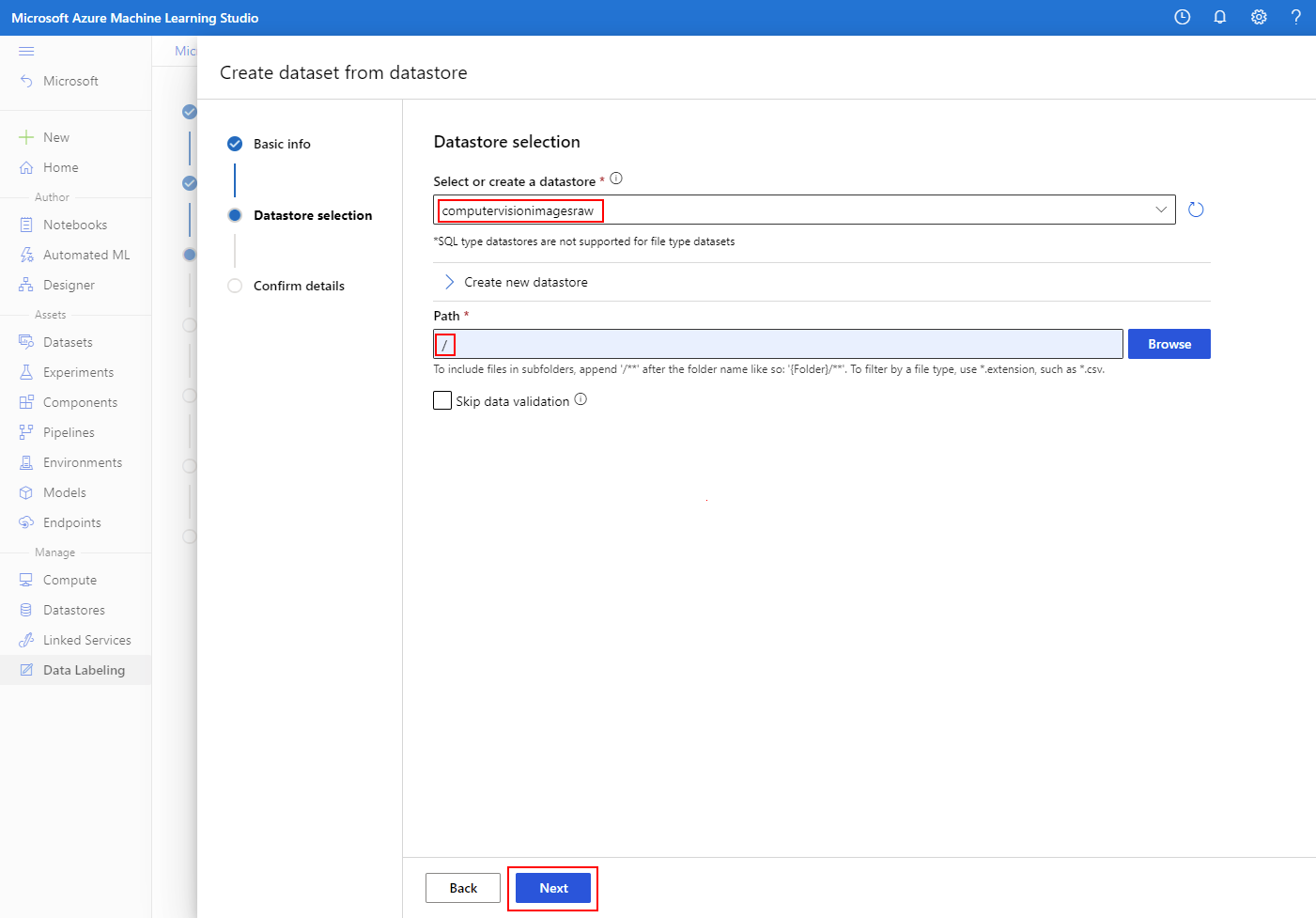
Bevestig details over uw nieuwe gegevensset en selecteer Maken.
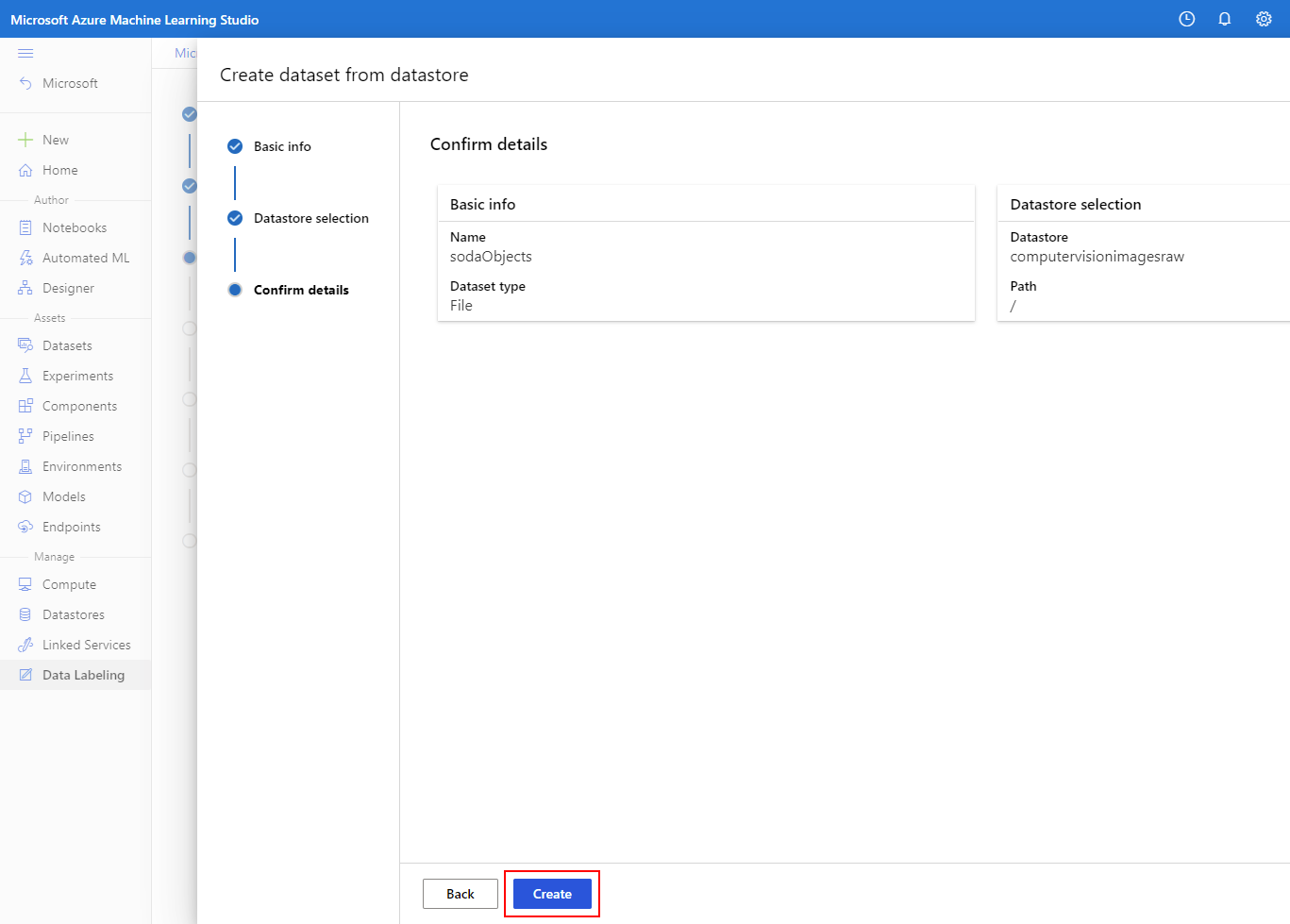
Kies de zojuist gemaakte gegevensset en selecteer vervolgens Volgende.
U wordt gevraagd om incrementeel vernieuwen met regelmatige tussenpozen in te schakelen. Met deze functie worden automatisch nieuw vastgelegde afbeeldingen toegevoegd aan uw gegevenslabelproject. Schakel deze optie in zoals wordt weergegeven en selecteer vervolgens Volgende.
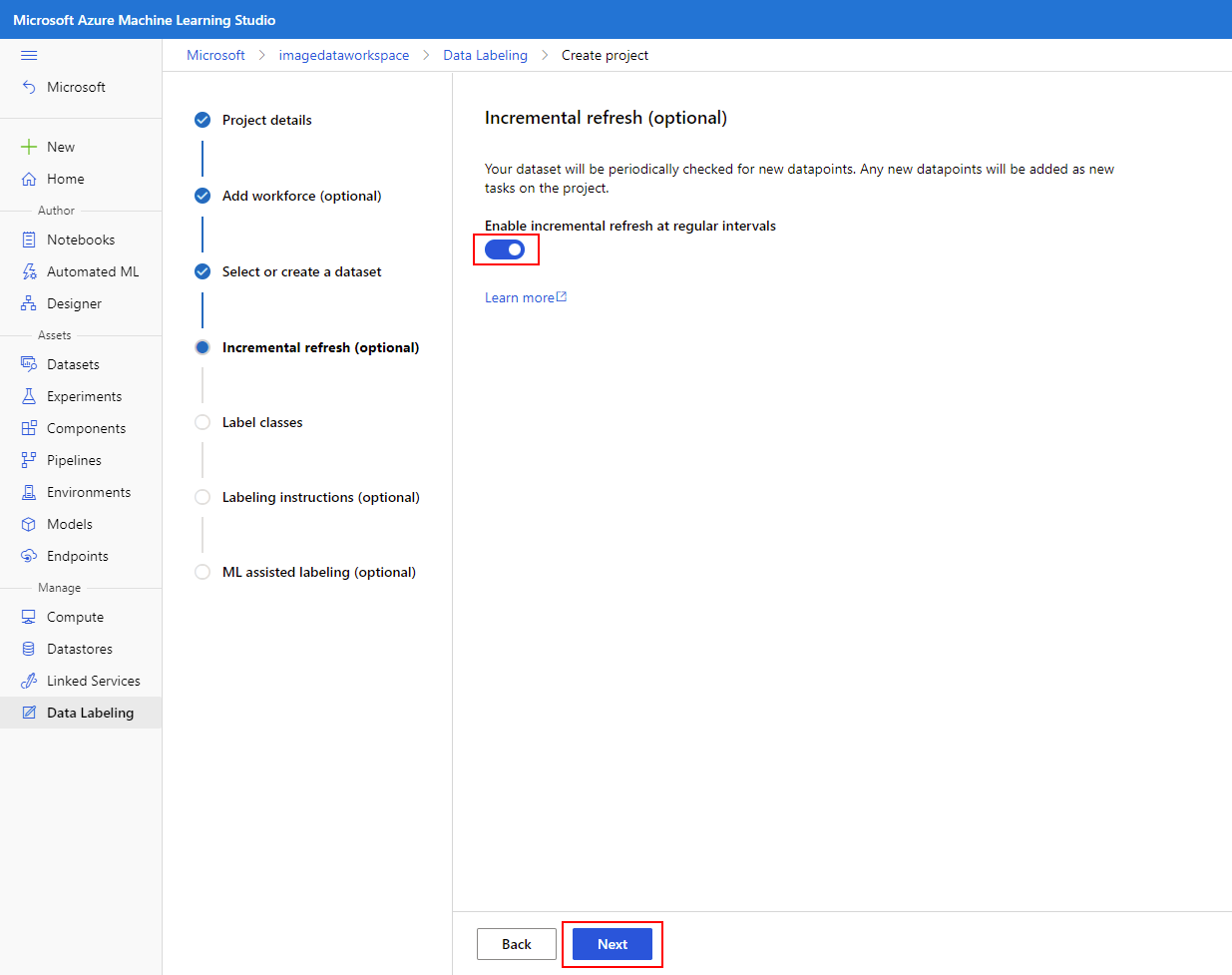
Voeg in het volgende deelvenster labelklassen toe voor alle objecten of defecten die u wilt detecteren. Neem hier positieve en negatieve klassen op.
U kunt desgewenst labelinstructies toevoegen in de volgende sectie. We laten deze sectie leeg en selecteren Volgende.
U kunt eventueel met ML ondersteunde labels gebruiken om het labelproces voor gegevens te versnellen, met name naarmate er meer gegevens worden vastgelegd. Voor deze leermodule gebruiken we deze optie niet. Schakel de optie uit zoals wordt weergegeven en selecteer vervolgens Project maken.