Vaardigheid voor aangepaste tekstclassificatie
Met aangepaste tekstclassificatie kunt u een passage van tekst toewijzen aan verschillende door de gebruiker gedefinieerde klassen. U kunt bijvoorbeeld een model trainen op de synopsis op de achterkant van boeken om automatisch een boekengenre te identificeren. Vervolgens gebruikt u dat geïdentificeerde genre om uw online winkelzoekprogramma te verrijken met een genre facet.
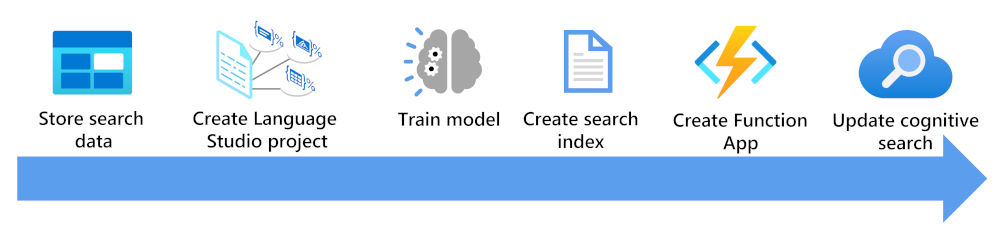
Hier ziet u wat u moet overwegen om een zoekindex te verrijken met behulp van een aangepast model voor tekstclassificatie:
- Sla uw documenten op zodat ze toegankelijk zijn voor Indexeerfuncties van Language Studio en Azure AI Search.
- Maak een aangepast tekstclassificatieproject.
- Train en test uw model.
- Maak een zoekindex op basis van uw opgeslagen documenten.
- Maak een functie-app die gebruikmaakt van uw geïmplementeerde getrainde model.
- Werk uw zoekoplossing, uw index, indexeerfunctie en aangepaste vaardighedenset bij.
Uw gegevens opslaan
Azure Blob Storage is toegankelijk vanuit Zowel Language Studio als Azure AI Services. De container moet toegankelijk zijn, dus de eenvoudigste optie is om Container te kiezen, maar het is ook mogelijk om privécontainers te gebruiken met een extra configuratie.
Naast uw gegevens hebt u ook een manier nodig om classificaties toe te wijzen voor elk document. Language Studio biedt een grafisch hulpprogramma dat u kunt gebruiken om elk document handmatig te classificeren.
U kunt kiezen tussen twee verschillende typen projecten. Als een document aan één klasse wordt toegewezen, gebruikt u één labelclassificatieproject. Als u een document aan meer dan één klasse wilt toewijzen, gebruikt u het project voor classificatie van meerdere labels.
Als u niet elk document handmatig wilt classificeren, kunt u al uw documenten labelen voordat u uw Azure AI Language-project maakt. Dit proces omvat het maken van een JSON-labeldocument in deze indeling:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
U voegt zoveel klassen toe als u aan de classes matrix hebt. U voegt een vermelding toe voor elk document in de documents matrix, inclusief welke klassen het document overeenkomt.
Uw Azure AI Language-project maken
Er zijn twee manieren om uw Azure AI Language-project te maken. Als u Language Studio gaat gebruiken zonder eerst een taalservice te maken in Azure Portal, biedt Language Studio u er een aan.
De meest flexibele manier om een Azure AI Language-project te maken, is door eerst uw taalservice te maken met behulp van Azure Portal. Als u deze optie kiest, krijgt u de optie om aangepaste functies toe te voegen.
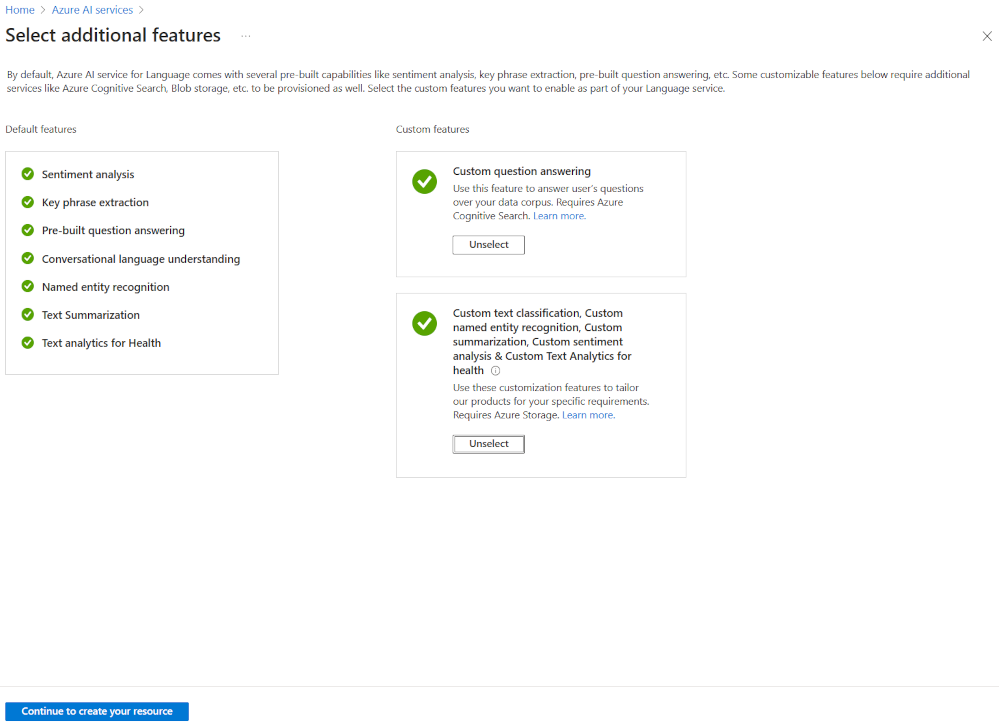
Wanneer u een aangepaste tekstclassificatie gaat maken, selecteert u die aangepaste functie bij het maken van uw taalservice. U koppelt de taalservice ook aan een opslagaccount met behulp van deze methode.
Zodra de resource is geïmplementeerd, kunt u rechtstreeks naar Language Studio navigeren vanuit het overzichtsvenster van de taalservice. Vervolgens kunt u een nieuw aangepast tekstclassificatieproject maken.
Notitie
Als u uw taalservice hebt gemaakt vanuit Language Studio, moet u mogelijk deze stappen uitvoeren. Stel rollen in voor uw Azure Language-resource en -opslagaccount om uw opslagcontainer te verbinden met uw aangepaste tekstclassificatieproject.
Uw classificatiemodel trainen
Net als bij alle AI-modellen moet u geïdentificeerde gegevens hebben die u kunt gebruiken om deze te trainen. Het model moet voorbeelden zien van het toewijzen van gegevens aan een klasse en enkele voorbeelden hebben die kunnen worden gebruikt om het model te testen. U kunt ervoor kiezen om het model automatisch te laten splitsen, standaard wordt 80% van de documenten gebruikt om het model te trainen en 20% om het te testen. Als u specifieke documenten hebt waarmee u uw model wilt testen, kunt u documenten labelen om te testen.

Selecteer in Language Studio, in uw project, gegevenslabeling. U ziet al uw documenten. Selecteer elk document dat u wilt toevoegen aan de testset en selecteer vervolgens De prestaties van het model testen. Sla de bijgewerkte labels op en maak vervolgens een nieuwe trainingstaak.
Zoekindex maken
U hoeft niets specifieks te doen om een zoekindex te maken die wordt verrijkt met een aangepast model voor tekstclassificatie. Volg de stappen in Een Azure AI Search-oplossing maken. U werkt de index, indexeerfunctie en aangepaste vaardigheid bij nadat u een functie-app hebt gemaakt.
Een Azure-functie-app maken
U kunt de gewenste taal en technologieën voor uw functie-app kiezen. De app moet JSON kunnen doorgeven aan het eindpunt voor aangepaste tekstclassificatie, bijvoorbeeld:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Vervolgens verwerkt u het JSON-antwoord van het model, bijvoorbeeld:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
De functie retourneert vervolgens een gestructureerd JSON-bericht terug naar een aangepaste vaardighedenset in AI Search, bijvoorbeeld:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Er zijn vijf dingen die de functie-app moet weten:
- De te classificeren tekst.
- Het eindpunt voor het getrainde model voor aangepaste tekstclassificatie.
- De primaire sleutel voor het aangepaste tekstclassificatieproject.
- De projectnaam.
- De implementatienaam.
De te classificeren tekst wordt doorgegeven vanuit uw aangepaste vaardighedenset in AI Search aan de functie als invoer. De overige vier items vindt u in Language Studio.

De naam van het eindpunt en de implementatie bevindt zich in het deelvenster Een model implementeren.

De projectnaam en primaire sleutel bevinden zich in het deelvenster projectinstellingen.
Uw Azure AI Search-oplossing bijwerken
Er zijn drie wijzigingen in Azure Portal die u moet aanbrengen om uw zoekindex te verrijken:
- U moet een veld toevoegen aan uw index om de verrijking van de aangepaste tekstclassificatie op te slaan.
- U moet een aangepaste vaardighedenset toevoegen om uw functie-app aan te roepen met de tekst die moet worden geclassificeerd.
- U moet het antwoord van de vaardighedenset toewijzen aan de index.
Een veld toevoegen aan een bestaande index
Ga in Azure Portal naar uw AI Search-resource, selecteer de index en u voegt JSON toe in deze indeling:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Deze JSON voegt een samengesteld veld toe aan de index om de klasse op te slaan in een category veld dat doorzoekbaar is. In het tweede confidenceScore veld wordt het betrouwbaarheidspercentage opgeslagen in een dubbel veld.
De aangepaste vaardighedenset bewerken
Selecteer in Azure Portal de vaardighedenset en voeg JSON toe in deze indeling:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Deze WebApiSill vaardigheidsdefinitie geeft aan dat de taal en de inhoud van een document worden doorgegeven als invoer voor de functie-app. De app retourneert JSON-tekst met de naam class.
De uitvoer van de functie-app toewijzen aan de index
De laatste wijziging is het toewijzen van de uitvoer aan de index. Selecteer in Azure Portal de indexeerfunctie en bewerk de JSON om een nieuwe uitvoertoewijzing te hebben:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
De indexeerfunctie weet nu dat de uitvoer van de functie-app document/class moet worden opgeslagen in het classifiedtext veld. Omdat dit is gedefinieerd als een samengesteld veld, moet de functie-app een JSON-matrix retourneren die een category en confidenceScore veld bevat.
U kunt nu zoeken in een verrijkte zoekindex voor uw aangepaste geclassificeerde tekst.