Uw gegevens classificeren
Een online-retailer heeft te maken met verschillende soorten gegevens. Elk type gegevens kan profiteren van een andere opslagoplossing.
Toepassingsgegevens kunnen op drie manieren worden geclassificeerd: gestructureerd, semi-gestructureerd en ongestructureerd. Hier leert u hoe u uw gegevens classificeert, zodat u de juiste opslagoplossing voor het type gegevens kunt kiezen.
Methoden voor het opslaan van gegevens in de cloud
In de volgende video worden uw opties voor het opslaan van gegevens in de cloud geïntroduceerd:
Gestructureerde gegevens
In gestructureerde gegevens, ook wel relationele gegevens genoemd, hebben alle gegevens dezelfde velden of eigenschappen. Alle gegevens hebben dezelfde organisatie en vorm of hetzelfde schema. Met het gedeelde schema kan dit type gegevens eenvoudig worden doorzocht met behulp van querytalen zoals Structured Query Language (SQL). Deze mogelijkheid maakt deze gegevensstijl perfect voor toepassingen zoals CRM-systemen, reserveringen en voorraadbeheer.
Gestructureerde gegevens worden vaak opgeslagen in databasetabellen met rijen en kolommen. In de tabel geeft een sleutelkolom aan hoe één rij in een tabel zich verhoudt tot gegevens in een andere rij van een andere tabel. In de volgende afbeelding haalt een tabel met gegevens over cijfers gegevens op uit een tabel met namen van leerlingen/studenten en een tabel met klassegegevens met behulp van sleutelkolommen.
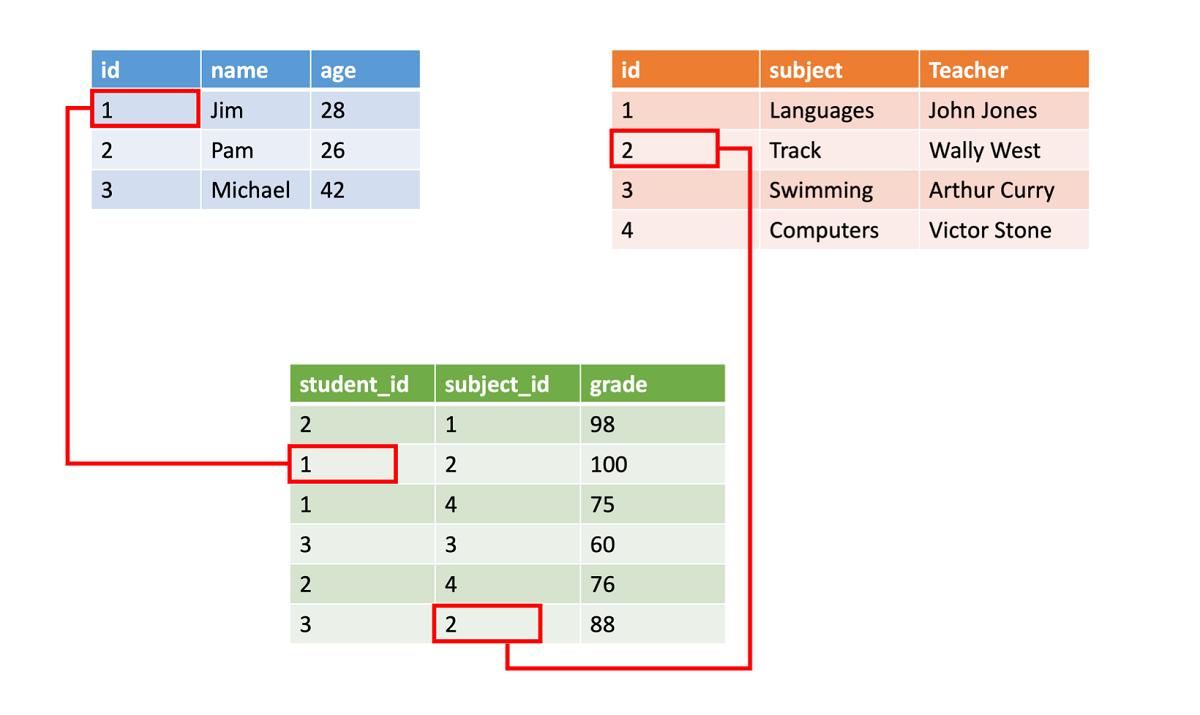
Gestructureerde gegevens zijn eenvoudig in die zin dat ze gemakkelijk zijn in te voeren, op te vragen en te analyseren. Alle gegevens hebben dezelfde indeling. Het afdwingen van een consistente structuur betekent echter ook dat de ontwikkeling van de gegevens moeilijker is. Als u gegevensvelden toevoegt of verwijdert, moet u elke record bijwerken om te voldoen aan de nieuwe structuur.
Semi-gestructureerde gegevens
Semi-gestructureerde gegevens zijn minder georganiseerd dan gestructureerde gegevens. Semi-gestructureerde gegevens worden niet opgeslagen in een relationele indeling omdat de velden niet netjes in tabellen, rijen en kolommen passen. Semi-gestructureerde gegevens bevatten labels die de organisatie en de hiërarchie van de gegevens zichtbaar maken. Een voorbeeld hiervan zijn sleutel-waardeparen. Semi-gestructureerde gegevens worden ook wel niet-relationele of niet alleen SQL-gegevens (NoSQL) genoemd.
Een taal voor gegevensserialisatie definieert semi-gestructureerde gegevens. In gegevensclassificatie is serialisatie het proces van het converteren van gegevens naar een indeling die kan worden verzonden of opgeslagen.
Softwareontwikkelaars gebruiken talen voor gegevensserialisatie om gegevens te schrijven die zijn opgeslagen in het geheugen naar een bestand, dat vervolgens naar een ander systeem kan worden verzonden, geparseerd en gelezen. De afzender en ontvanger hoeven geen details over het andere systeem te weten. Beide systemen kunnen de gegevens begrijpen als ze dezelfde serialisatietaal gebruiken.
Algemene serialisatietalen
Drie veelgebruikte serialisatietalen zijn XML, JSON en YAML.
XML
Extensible Markup Language (XML) was een van de eerste gegevenstalen die veel moeten worden gebruikt. XML is gebaseerd op tekst, waardoor het gemakkelijk leesbaar en machineleesbaar is. XML-parsers zijn beschikbaar voor bijna alle populaire ontwikkelplatforms.
U kunt XML gebruiken om relaties uit te drukken. XML heeft standaarden voor schema, transformatie en zelfs weergave op internet.
Hier volgt een voorbeeld van de naam, leeftijd en hobby's van een persoon, uitgedrukt in XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML geeft de vorm van de gegevens weer met behulp van tags die zijn gedefinieerd in puntaccolades. De tags zijn in twee vormen beschikbaar: elementen zoals <FirstName> en kenmerken die kunnen worden uitgedrukt in tekst zoals Age="23". Elementen kunnen onderliggende elementen hebben om relaties uit te drukken. De tag geeft bijvoorbeeld <Hobbies> een verzameling Hobby elementen weer.
XML is flexibel en kan complexe gegevens eenvoudig uitdrukken. Het is echter meestal uitgebreider, waardoor het groter wordt om een netwerk op te slaan, te verwerken en door te geven. Hierdoor zijn andere indelingen populairder geworden.
JSON
JavaScript Object Notation (JSON) heeft een lichtgewicht specificatie en maakt gebruik van accolades om de gegevensstructuur aan te geven. Vergeleken met XML is JSON minder uitgebreid en is het gemakkelijker voor mensen om te lezen. JSON wordt vaak gebruikt door webservices om gegevens te retourneren.
Hier ziet u de naam, leeftijd en hobby's van dezelfde persoon, uitgedrukt in JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
De JSON-indeling is niet zo formeel als XML. Het is dichter bij een sleutel-waardepaarmodel dan bij een formele gegevensexpressie. Zoals u misschien uit de naam kunt raden, heeft de JavaScript-programmeertaal ingebouwde ondersteuning voor deze indeling, dus het is populair voor webontwikkeling. Net als voor XML zijn er voor andere talen ook parsers beschikbaar die u kunt gebruiken om met deze gegevensindeling te werken. Het nadeel van JSON is dat het meestal meer programmeurgericht is, dus het is moeilijker voor niet-technische mensen om te lezen en te wijzigen.
YAML
YAML Ain't Markup Language (YAML) is een meer recent ontwikkelde taal voor gegevensserialisatie. Een van de voordelen van het gebruik van YAML is dat mensen gemakkelijker kunnen lezen dan sommige andere talen. Scheiding van lijnen en inspringing definiëren de gegevensstructuur. De YAML-indeling vermindert de afhankelijkheid van structurele tekens, zoals haakjes, komma's en vierkante haken.
Hier volgen dezelfde gegevens die worden uitgedrukt in YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Deze indeling is beter leesbaar dan JSON. Configuratiebestanden die mensen schrijven, maar programma's parseren, zijn een veelvoorkomend gebruik. YAML is de nieuwste van deze gegevensindelingen.
Het wordt vaak gebruikt voor configuratiebestanden die zijn geschreven door personen, maar worden geparseerd door programma's.
Wat zijn semi-gestructureerde of NoSQL-gegevens?
In de volgende video worden semi-gestructureerde gegevens en NoSQL-gegevensopslagopties beschreven:
Niet-gestructureerd gegevens
De organisatie van ongestructureerde gegevens is niet gedefinieerd. Ongestructureerde gegevens worden vaak geleverd in bestandsindeling, zoals in foto- of videobestanden. Het videobestand zelf heeft mogelijk een algemene structuur en wordt geleverd met semi-gestructureerde metagegevens, maar de gegevens die de video zelf vormen, zijn ongestructureerd. Daarom worden foto's en video's en andere soortgelijke bestanden geclassificeerd als niet-gestructureerde gegevens.
Voorbeelden van niet-gestructureerde gegevens zijn:
- Mediabestanden, zoals foto's, video's en audiobestanden.
- Microsoft 365-bestanden, zoals Word-documenten.
- Tekstbestanden.
- Logboekbestanden.
Gegevensclassificatie: Uw gegevenstypen evalueren
U kunt gegevens op drie manieren classificeren: gestructureerd, semi-gestructureerd en ongestructureerd. Als u de verschillen begrijpt zodat u uw gegevens kunt classificeren, kunt u de juiste opslagoplossing kiezen.
Gestructureerde gegevens zijn geordend gegevens die netjes in tabellen of kolommen met gegevens passen. Semi-gestructureerde gegevens zijn ook geordend en hebben duidelijke eigenschappen en waarden, maar de gegevens zijn gevarieerd. Ongestructureerde gegevens passen niet netjes in tabellen of kolommen en hebben geen uniform schema.
Laten we eens kijken naar de gegevenssets die worden gebruikt in een onlinehandelsbedrijf en deze classificeren.
Gegevens voor productcatalogus
Productcatalogusgegevens voor een online detailhandel zijn semi-gestructureerd van aard. Elk product heeft een product-SKU, een beschrijving, een hoeveelheid, een prijs, grootteopties, kleuropties, een foto en mogelijk een video. Deze gegevens lijken relationeel te beginnen, omdat deze allemaal dezelfde structuur hebben. Als u echter nieuwe producten of verschillende soorten producten introduceert, kunt u gegevensvelden toevoegen. Nieuwe tennisschoenen die u draagt, zijn bijvoorbeeld Bluetooth-ingeschakeld om sensorgegevens van de schoen door te sturen naar een fitness-app op de telefoon van de gebruiker. Deze functie lijkt een groeiende trend te zijn en u wilt klanten de optie geven om te filteren op 'Bluetooth-ingeschakelde' schoenen. U wilt niet al uw bestaande schoengegevens bijwerken met een bluetooth-eigenschap. U wilt deze nieuwe eigenschap alleen toevoegen aan nieuwe schoenen.
Door de toevoeging van de eigenschap Bluetooth zijn uw schoengegevens niet langer homogeen. U hebt verschillen in het schema geïntroduceerd. Als deze wijziging de enige uitzondering is die u verwacht te tegenkomen, kunt u de bestaande gegevens normaliseren zodat alle producten een veld Met Bluetooth bevatten om een gestructureerde, relationele organisatie te onderhouden. Als het echter slechts een van de vele speciale velden is die u in de toekomst wilt ondersteunen, is de classificatie van de gegevens semi-gestructureerd. Tags organiseren de gegevens, maar elk product in de catalogus kan unieke velden bevatten.
De classificatie voor productcatalogusgegevens is semi-gestructureerd.
Foto's en video's
De foto's en video's die worden weergegeven op de productpagina's zijn niet-gestructureerde gegevens. Hoewel het mediabestand metagegevens kan bevatten, is de hoofdtekst van het mediabestand ongestructureerd.
De gegevensclassificatie voor foto's en video's is ongestructureerd.
Bedrijfsgegevens
Bedrijfsanalisten willen business intelligence implementeren om inventarispijplijnevaluaties uit te voeren en verkoopgegevens te beoordelen. Om deze bewerkingen uit te voeren, moeten gegevens van meerdere maanden worden geaggregeerd en vervolgens worden opgevraagd. Vanwege de noodzaak om vergelijkbare gegevens te aggregeren, moeten deze gegevens gestructureerd zijn, zodat één maand kan worden vergeleken met de volgende.
De classificatie voor zakelijke gegevens is gestructureerd.