Machine learning voor computerzicht
De mogelijkheid om filters te gebruiken om effecten op afbeeldingen toe te passen, is handig bij het verwerken van afbeeldingen, zoals u kunt uitvoeren met software voor het bewerken van afbeeldingen. Het doel van computer vision is echter vaak het extraheren van betekenis, of ten minste bruikbare inzichten, uit afbeeldingen; hiervoor moeten machine learning-modellen worden gemaakt die zijn getraind om kenmerken te herkennen op basis van grote hoeveelheden bestaande afbeeldingen.
Fooi
In deze les wordt ervan uitgegaan dat u bekend bent met de basisprincipes van machine learning en dat u conceptuele kennis hebt van deep learning met neurale netwerken. Als u geen kennis hebt met machine learning, kunt u overwegen de Basisprincipes van machine learning module op Microsoft Learn te voltooien.
Convolutionele neurale netwerken ("CNNs")
Een van de meest voorkomende machine learning-modelarchitecturen voor Computer Vision is een convolutionele neurale netwerk (CNN), een type deep learning-architectuur. CNN's gebruiken filters voor het extraheren van numerieke functietoewijzingen uit afbeeldingen en voeren vervolgens de functiewaarden in een Deep Learning-model in om een labelvoorspelling te genereren. In een afbeeldingsclassificatie scenario vertegenwoordigt het label bijvoorbeeld het hoofdonderwerp van de afbeelding (met andere woorden, waar is dit een afbeelding van?). U kunt een CNN-model trainen met afbeeldingen van verschillende soorten fruit (zoals appel, banaan en sinaasappel), zodat het label dat wordt voorspeld het type fruit in een bepaalde afbeelding is.
Tijdens het training proces voor een CNN worden filterkernels in eerste instantie gedefinieerd met behulp van willekeurig gegenereerde gewichtswaarden. Naarmate het trainingsproces vordert, worden de voorspellingen van modellen geëvalueerd op basis van bekende labelwaarden en worden de filtergewichten aangepast om de nauwkeurigheid te verbeteren. Uiteindelijk gebruikt het getrainde model voor afbeeldingsclassificatie van fruit de filtergewichten die de beste kenmerken extraheren die helpen verschillende soorten fruit te identificeren.
In het volgende diagram ziet u hoe een CNN voor een afbeeldingsclassificatiemodel werkt:
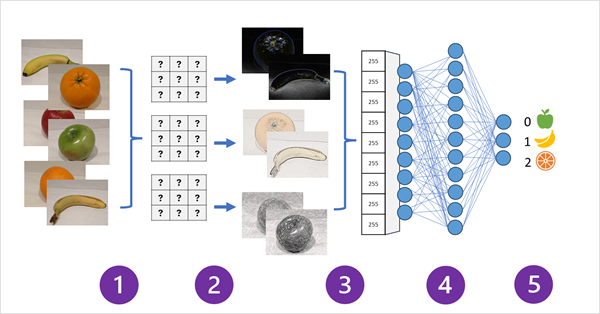
- Afbeeldingen met bekende labels (bijvoorbeeld 0: appel, 1: banaan of 2: oranje) worden ingevoerd in het netwerk om het model te trainen.
- Een of meer lagen filters worden gebruikt om functies uit elke afbeelding te extraheren terwijl deze via het netwerk worden ingevoerd. De filterkernels beginnen met willekeurig toegewezen gewichten en genereren matrices met numerieke waarden met de naam functietoewijzingen.
- De feature maps worden platgemaakt in een ééndimensionale array van kenmerkwaarden.
- De functiewaarden worden ingevoerd in een volledig verbonden neuraal netwerk.
- De uitvoerlaag van het neurale netwerk maakt gebruik van een softmax- of vergelijkbare functie om een resultaat te produceren dat een waarschijnlijkheidswaarde voor elke mogelijke klasse bevat, bijvoorbeeld [0,2, 0,5, 0,3].
Tijdens het trainen worden de uitvoerkansen vergeleken met het werkelijke klasselabel, bijvoorbeeld een afbeelding van een banaan (klasse 1) moet de waarde [0,0, 1.0, 0,0 hebben]. Het verschil tussen de voorspelde en werkelijke klassescores wordt gebruikt om de verlies in het model te berekenen, en de gewichten in het volledig verbonden neurale netwerk en de filterkernels in de functieextractielagen worden gewijzigd om het verlies te verminderen.
Het trainingsproces herhaalt zich over meerdere tijdperken totdat een optimale reeks gewichten is geleerd. Vervolgens worden de gewichten opgeslagen en kan het model worden gebruikt om labels te voorspellen voor nieuwe afbeeldingen waarvoor het label onbekend is.
Notitie
CNN-architecturen bevatten meestal meerdere convolutionele filterlagen en extra lagen om de grootte van functietoewijzingen te verminderen, de geëxtraheerde waarden te beperken en de functiewaarden anders te manipuleren. Deze lagen zijn weggelaten in dit vereenvoudigde voorbeeld om te focussen op het belangrijkste concept, dat wil zeggen dat filters worden gebruikt voor het extraheren van numerieke functies uit afbeeldingen, die vervolgens worden gebruikt in een neuraal netwerk om afbeeldingslabels te voorspellen.
Transformatoren en multimodale modellen
CNN's zijn al vele jaren de kern van computer vision-oplossingen. Hoewel ze vaak worden gebruikt om problemen met afbeeldingsclassificatie op te lossen zoals eerder beschreven, vormen ze ook de basis voor complexere Computer Vision-modellen. objectdetectie modellen bijvoorbeeld CNN-functieextractielagen combineren met de identificatie van interessegebieden in afbeeldingen om meerdere klassen object in dezelfde afbeelding te vinden.
Transformers
De meeste ontwikkelingen in computer vision in de loop van de decennia zijn gedreven door verbeteringen in CNN-modellen. In een andere AI-discipline: natuurlijke taalverwerking (NLP), een ander type neurale netwerkarchitectuur, een transformer genoemd heeft de ontwikkeling van geavanceerde modellen voor taal mogelijk gemaakt. Transformatoren werken door grote hoeveelheden gegevens te verwerken en de taal te coderen tokens (die afzonderlijke woorden of woordgroepen vertegenwoordigen) als vectorgebaseerde insluitingen (matrices met numerieke waarden). U kunt een insluiting beschouwen als een set dimensies die elk een semantisch kenmerk van het token vertegenwoordigen. De insluitingen worden zodanig gemaakt dat tokens die vaak in dezelfde context worden gebruikt, dimensies dichter bij elkaar staan dan niet-gerelateerde woorden.
Als eenvoudig voorbeeld toont het volgende diagram enkele woorden die zijn gecodeerd als driedimensionale vectoren en worden uitgezet in een 3D-ruimte:
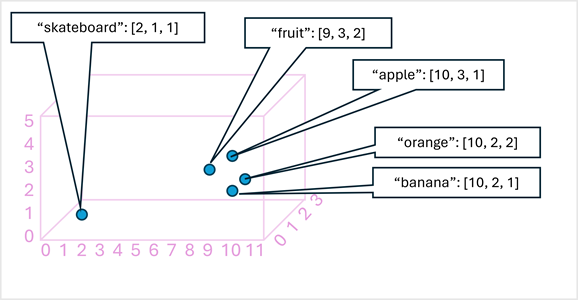
Tokens die semantisch vergelijkbaar zijn, worden gecodeerd in vergelijkbare posities, waardoor een semantisch taalmodel wordt gemaakt waarmee u geavanceerde NLP-oplossingen kunt bouwen voor tekstanalyse, vertaling, taalgeneratie en andere taken.
Notitie
We hebben slechts drie dimensies gebruikt, omdat dat eenvoudig te visualiseren is. In werkelijkheid maken encoders in transformatornetwerken vectoren met veel meer dimensies, waarbij complexe semantische relaties tussen tokens worden gedefinieerd op basis van lineaire algebraïsche berekeningen. De betrokken wiskunde is complex, net als de architectuur van een transformatormodel. Ons doel hier is om een conceptueel inzicht te geven in hoe codering een model maakt dat relaties tussen entiteiten inkapselt.
Multimodale modellen
Het succes van transformatoren als een manier om taalmodellen te bouwen, heeft AI-onderzoekers ertoe geleid om na te gaan of dezelfde benadering effectief is voor afbeeldingsgegevens. Het resultaat is de ontwikkeling van multimodale modellen, waarin het model wordt getraind met behulp van een groot aantal afbeeldingen met bijschriften, zonder vaste labels. Een afbeeldingscoderingsprogramma extraheert functies van afbeeldingen op basis van pixelwaarden en combineert deze met tekst insluitingen die zijn gemaakt door een taalcoderingsprogramma. Het algemene model bevat relaties tussen insluitingen van tokens in natuurlijke taal en afbeeldingsfuncties, zoals hier wordt weergegeven:
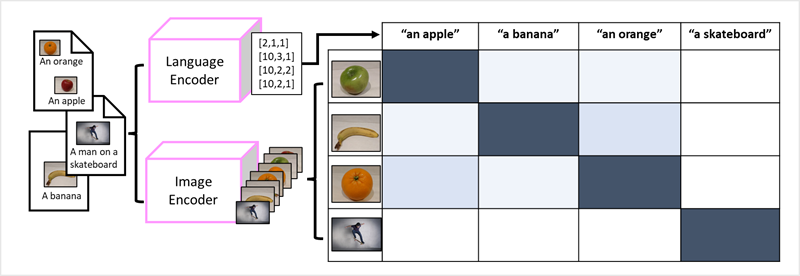
Het Microsoft Florence model is zo'n model. Getraind met enorme hoeveelheden afbeeldingen met bijschriften van internet, bevat het zowel een taalcoderingsprogramma als een afbeeldingscoderingsprogramma. Florence is een voorbeeld van een basis model. Met andere woorden, een vooraf getraind algemeen model waarop u meerdere adaptieve modellen voor gespecialiseerde taken kunt bouwen. U kunt Florence bijvoorbeeld gebruiken als basismodel voor adaptieve modellen die het volgende uitvoeren:
- afbeeldingsclassificatie: bepalen aan welke categorie een afbeelding hoort.
- objectdetectie: afzonderlijke objecten in een afbeelding zoeken.
- Ondertiteling: Het genereren van passende beschrijvingen van afbeeldingen.
- taggen: een lijst samenstellen met relevante teksttags voor een afbeelding.
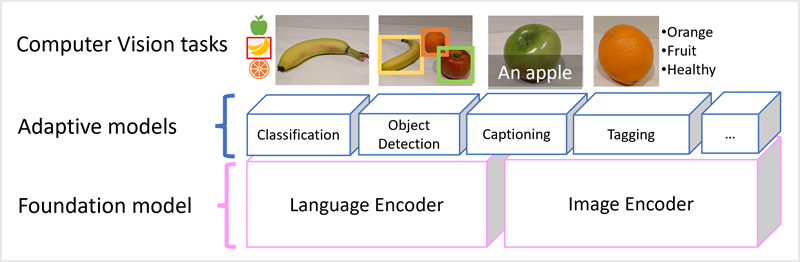
Multimodale modellen zoals Florence bevinden zich in het algemeen op het snijvlak van computer vision en AI en zullen naar verwachting vooruitgang boeken in de soorten oplossingen die AI mogelijk maakt.