Concept - Toepassing uitrollen
Voordat u uw toepassing in Kubernetes implementeert, gaan we Kubernetes-implementaties bekijken en hun beperkingen in ons scenario bespreken.
Wat zijn Kubernetes-implementaties?
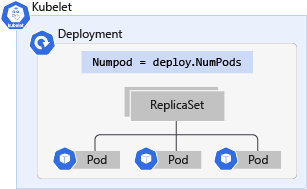
Een Kubernetes-implementatie is een evolutie van pods. Implementaties verpakken pods in een intelligent object waarmee ze kunnenuitschalen. U kunt uw toepassing eenvoudig dupliceren en schalen om meer belasting te ondersteunen zonder dat u complexe netwerkregels hoeft te configureren.
Met deployments kunt u uw toepassingen bijwerken zonder uitvaltijd door de imagetag te wijzigen. Als u een implementatie bijwerkt, worden de online-apps één voor één uitgeschakeld en vervangen door de nieuwste versie in plaats van alle apps te verwijderen en nieuwe apps te maken. Dit betekent dat de implementatie de pods erin kan bijwerken zonder zichtbaar effect op beschikbaarheid.
Hoewel er veel voordelen zijn bij het gebruik van implementaties via pods, kunnen ze ons scenario niet adequaat verwerken.
Dit scenario omvat een gebeurtenisgestuurde toepassing die een groot aantal gebeurtenissen op verschillende momenten ontvangt. Zonder een KEDA Scaler-object of HPA moet u het aantal replica's handmatig aanpassen om het aantal gebeurtenissen te verwerken en omlaag schalen de implementatie wanneer de belasting weer normaal wordt uitgevoerd.
Voorbeeldimplementatiemanifest
Hier volgt een voorbeeldfragment van ons implementatiemanifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: contoso-microservice
spec:
replicas: 10 # Tells K8S the number of pods needed to process the Redis list items
selector: # Define the wrapping strategy
matchLabels: # Match all pods with the defined labels
app: contoso-microservice # Labels follow the `name: value` template
template: # Template of the pod inside the deployment
metadata:
labels:
app: contoso-microservice
spec:
containers:
- image: mcr.microsoft.com/mslearn/samples/redis-client:latest
name: contoso-microservice
In het voorbeeldmanifest is replicas ingesteld op 10. Dit is het hoogste aantal dat we kunnen instellen voor de benodigde replica's die beschikbaar zijn voor het verwerken van het piekaantal gebeurtenissen. Dit zorgt er echter voor dat de toepassing te veel resources verbruikt tijdens niet-piektijden, waardoor andere Deployments binnen het cluster te weinig middelen kunnen krijgen.
Een oplossing is om een zelfstandige HPA te gebruiken om het CPU-gebruik van de pods te bewaken. Dit is een betere optie dan handmatig schalen in beide richtingen. De HPA richt zich echter niet op het aantal gebeurtenissen dat de Redis-lijst ontvangt.
De beste oplossing is om KEDA en een Redis-schaalset te te gebruiken om een query uit te voeren op de lijst en te bepalen of er meer of minder pods nodig zijn om de gebeurtenissen te verwerken.