Schalen met KEDA
Automatische schaalaanpassing op basis van Kubernetes
Kubernetes Event-driven Autoscaling (KEDA) is een enkel doeleinde en lichtgewicht onderdeel dat het automatisch schalen van toepassingen vereenvoudigt. U kunt KEDA toevoegen aan elk Kubernetes-cluster en dit naast standaard-Kubernetes-onderdelen gebruiken, zoals de Horizontale automatische schaalaanpassing van pods (HPA) of Cluster Autoscaler, om hun functionaliteit uit te breiden. Met KEDA kunt u zich richten op specifieke apps die u wilt gebruiken voor gebeurtenisgestuurd schalen en andere apps toestaan om verschillende schaalmethoden te gebruiken. KEDA is een flexibele en veilige optie om naast een willekeurig aantal Kubernetes-toepassingen of frameworks te worden uitgevoerd.
Belangrijkste mogelijkheden en functies
- Duurzame en kostenefficiënte toepassingen bouwen met scale-to-zero-mogelijkheden
- Toepassingsworkloads schalen om te voldoen aan de vraag met keda-schaalders
- Toepassingen automatisch schalen met
ScaledObjects - Taken automatisch schalen met
ScaledJobs - Beveiliging op productieniveau gebruiken door automatisch schalen en verificatie van workloads los te koppelen
- Bring-Your-Own External Scaler om op maat gemaakte configuraties voor automatisch schalen te gebruiken
Architectuur
KEDA biedt twee hoofdonderdelen:
-
KEDA-operator: hiermee kunnen eindgebruikers workloads in- of uitschalen van nul naar N-exemplaren met ondersteuning voor Kubernetes-implementaties, taken, StatefulSets of een klantresource die een
/scalesubresource definieert. - Server voor metrische gegevens: maakt externe metrische gegevens beschikbaar voor de HPA, zoals berichten in een Kafka-onderwerp of gebeurtenissen in Azure Event Hubs, om acties voor automatisch schalen te stimuleren. Vanwege upstream-beperkingen moet de KEDA Metrics-server de enige geïnstalleerde metrische adapter in het cluster zijn.
In het volgende diagram ziet u hoe KEDA kan worden geïntegreerd met de Kubernetes HPA, externe gebeurtenisbronnen en Kubernetes API Server om automatische schaalaanpassingsfunctionaliteit te bieden:
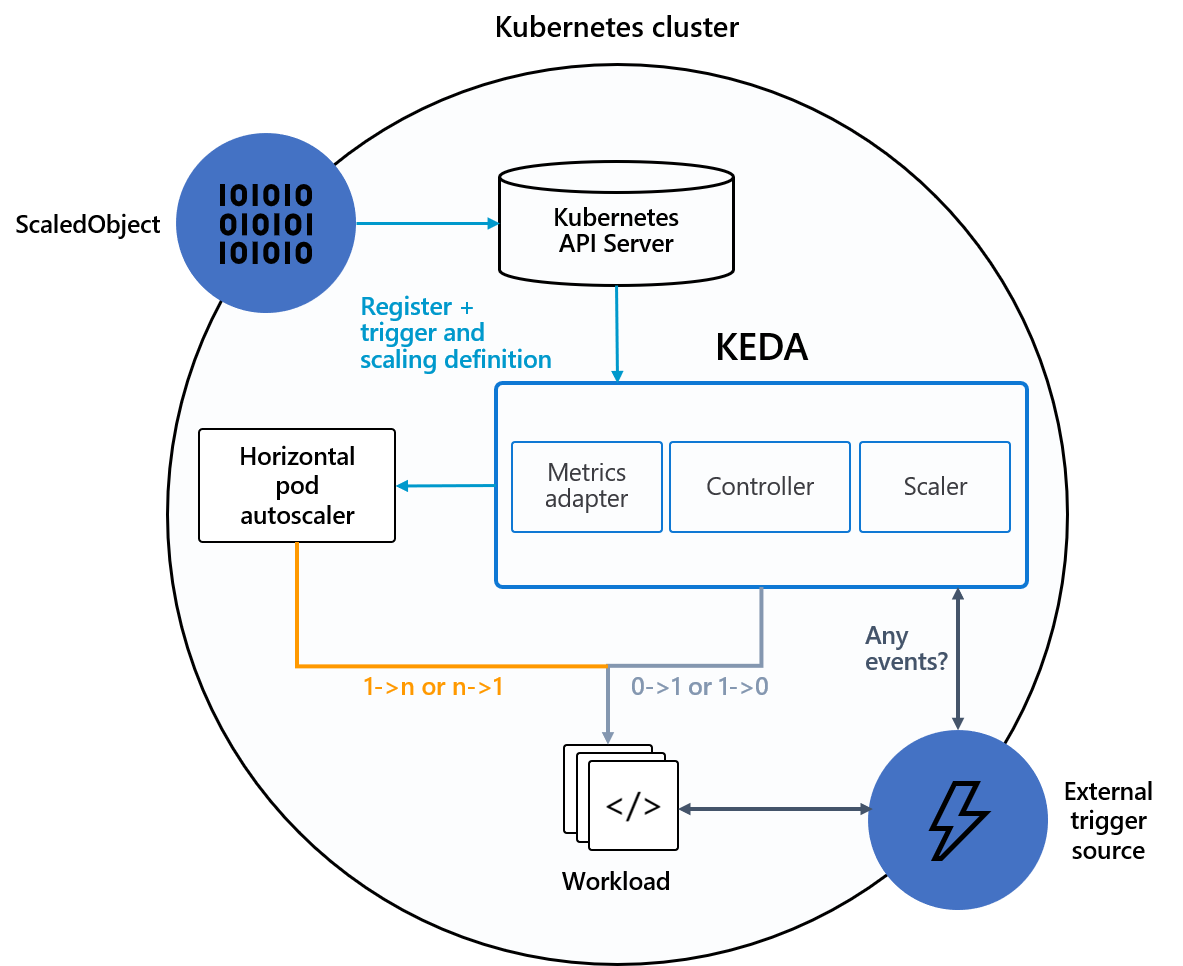
Tip
Zie de officiële KEDA-documentatie voor meer informatie.
Gebeurtenisbronnen en scalers
KEDA-schaalders kunnen detecteren of een implementatie moet worden geactiveerd of gedeactiveerd en aangepaste metrische gegevens voor een specifieke gebeurtenisbron moeten worden feed. Implementaties en StatefulSets zijn de meest voorkomende manier om workloads te schalen met KEDA. U kunt ook aangepaste resources schalen die de /scale subresource implementeren. U kunt de Kubernetes-implementatie of StatefulSet definiëren die u wilt schalen op basis van een schaaltrigger. KEDA bewaakt deze services en schaalt ze automatisch in of uit op basis van de gebeurtenissen die optreden.
Achter de schermen bewaakt KEDA de gebeurtenisbron en voert deze gegevens door naar Kubernetes en de HPA om snel schalen van resources te stimuleren. Elke replica van een resource haalt actief items op uit de gebeurtenisbron. Met KEDA en Deployments/StatefulSetskunt u schalen op basis van gebeurtenissen, terwijl u ook uitgebreide verbindings- en verwerkingssemantiek behoudt met de gebeurtenisbron (bijvoorbeeld in-orderverwerking, nieuwe pogingen, deadletter of controlepunten).
Objectspecificatie geschaald
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
Taakspecificatie geschaald
Als alternatief voor het schalen van gebeurtenisgestuurde code als implementaties, kunt u uw code ook uitvoeren en schalen als een Kubernetes-taak. De belangrijkste reden om deze optie te overwegen, is als u langlopende uitvoeringen moet verwerken. In plaats van meerdere gebeurtenissen binnen een implementatie te verwerken, plant elke gedetecteerde gebeurtenis een eigen Kubernetes-taak. Met deze benadering kunt u elke gebeurtenis afzonderlijk verwerken en het aantal gelijktijdige uitvoeringen schalen op basis van het aantal gebeurtenissen in de wachtrij.
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}