Opslagruimten Direct beheren in VMM
Dit artikel bevat een overzicht van Opslagruimten Direct (S2D) en hoe deze wordt geïmplementeerd in de System Center Virtual Machine Manager-infrastructuur (VMM).
Opslagruimten Direct (S2D) werd geïntroduceerd in Windows Server 2016. Fysieke opslagstations worden gegroepeerd in virtuele opslaggroepen om gevirtualiseerde opslag te bieden. Met gevirtualiseerde opslag kunt u het volgende doen:
- Meerdere fysieke opslagbronnen beheren als één virtuele entiteit.
- Krijg goedkope opslag, met en zonder externe opslagapparaten.
- Verzamel verschillende typen opslag in één virtuele opslaggroep.
- Eenvoudig opslag inrichten en gevirtualiseerde opslag op aanvraag uitbreiden door nieuwe schijven toe te voegen.
Notitie
VMM 2019 UR3 en hoger ondersteunt Azure Stack Hyper Converged Infrastructure (HCI, versie 20H2).
Notitie
VMM 2025 ondersteunt Azure Local (versie 23H2 en 22H2).
Hoe werkt het?
S2D maakt pools van opslag op basis van opslag die is gekoppeld aan specifieke knooppunten in een Windows Server-cluster. De opslag kan intern zijn op het knooppunt of schijfapparaten die rechtstreeks aan één knooppunt zijn gekoppeld. Ondersteunde opslagstations zijn NVMe, SSD verbonden via SATA of SAS en HDD. Meer informatie.
- Wanneer u S2D inschakelt op een Windows Server-cluster, detecteert S2D automatisch in aanmerking komende opslag en voegt deze toe aan een opslaggroep voor het cluster.
- S2D maakt ook een ingebouwde opslagcache aan de serverzijde om de prestaties te maximaliseren. De snelste schijven worden gebruikt voor caching en de resterende schijven voor capaciteit. Meer informatie over de cache.
- U maakt volumes van een opslagpool. Als u een volume maakt, maakt u de virtuele schijf (opslagruimte), partitioneert en formatteert u het volume, voegt u het toe aan het cluster en converteert u het naar een gedeeld clustervolume (CSV).
- U configureert verschillende fouttolerantieniveaus voor een volume om op te geven hoe virtuele schijven worden verdeeld over fysieke schijven in de groep, met behulp van SMB 3.0. U kunt een volume zonder tolerantie of met tolerantie voor spiegeling of pariteit configureren. Meer informatie.
Geconvergeerde en niet-geconvergeerde implementatie
Een cluster met S2D kan op een aantal manieren worden geïmplementeerd:
- hypergeconvergeerde implementatie: Hyper-V compute- en S2D-opslag worden uitgevoerd binnen hetzelfde cluster, zonder scheiding tussen deze clusters. Dit biedt het gelijktijdig schalen van reken- en opslagmiddelen.
- niet-geaggregeerde implementatie: Rekenresources worden uitgevoerd op één Hyper-V cluster. S2D-opslag wordt uitgevoerd op een ander cluster. U kunt de clusters afzonderlijk schalen voor nauwkeurig afgestemd beheer.
Hypergeconvergeerde implementatie
Hier volgt een afbeelding voor hypergeconvergeerde implementatie
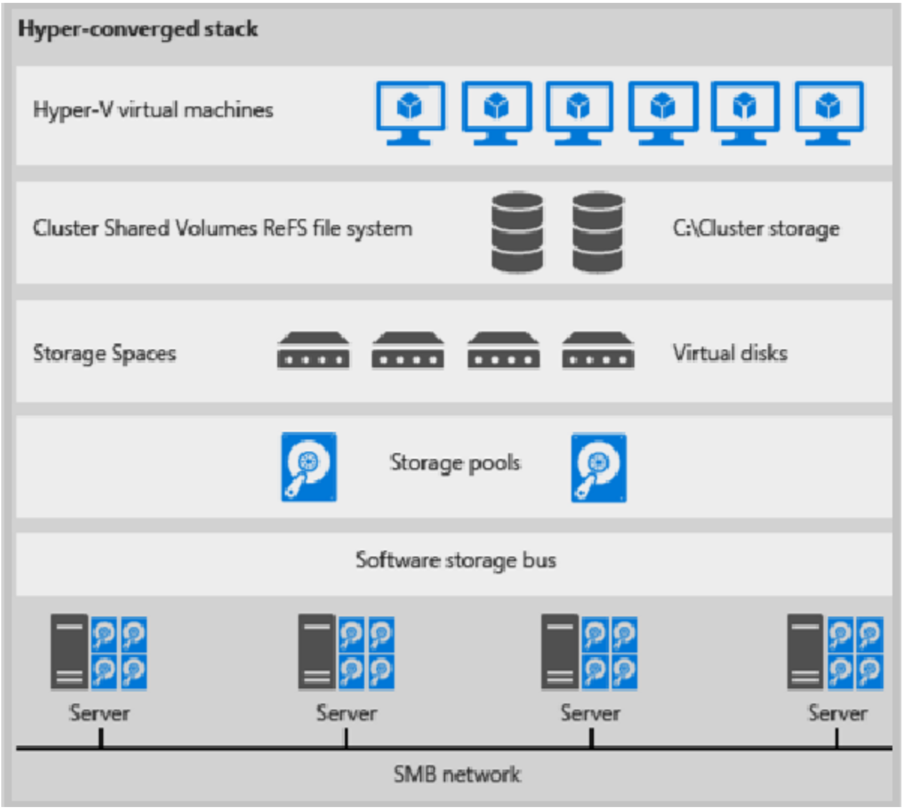
afbeelding 1: Hypergeconvergeerde implementatie
- VM-bestanden worden opgeslagen op lokale CSV's.
- Bestandsshares en SMB worden niet gebruikt.
- Nadat S2D CSV-volumes beschikbaar zijn, richt u ze in zoals bij elke andere Hyper-V implementatie.
- U schaalt het Hyper-V rekencluster samen met de S2D-opslag.
Niet-geaggregeerde implementatie
Hier volgt een afbeelding van een niet-geaggregeerde implementatie
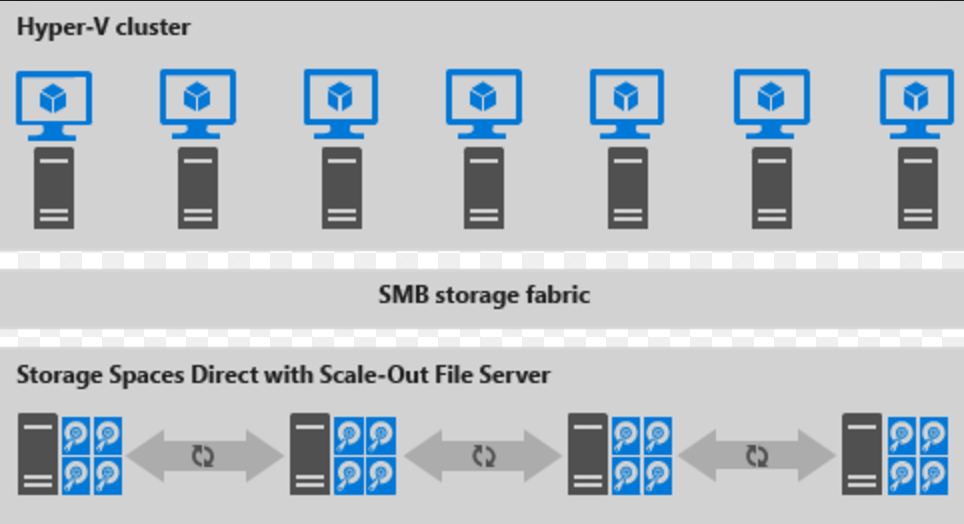
afbeelding 2: gedistribueerde uitrol
- Bestandsdeling wordt gemaakt op de S2D-CSV's.
- Hyper-V VM's zijn geconfigureerd voor het opslaan van hun bestanden op de scaled-out bestandsserver (SOFS) en worden geopend met SMB 3.0.
- U kunt de Hyper-V- en SOFS-clusters afzonderlijk schalen voor nauwkeurig afgestemd beheer. Rekenknooppunten kunnen bijvoorbeeld bijna volledige capaciteit hebben voor veel VM's, maar opslagknooppunten hebben mogelijk overtollige schijf- en IOPS-capaciteit; dus u voegt alleen extra rekenknooppunten toe.