Tijdelijke scenario's voor tabelgebruik
Van toepassing op:![]() SQL Server 2016 (13.x) en latere versies
SQL Server 2016 (13.x) en latere versies ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-database in Microsoft Fabric
SQL-database in Microsoft Fabric
Tijdelijke tabellen met systeemversies zijn handig in scenario's waarvoor het bijhouden van gegevenswijzigingen is vereist. We raden u aan tijdelijke tabellen in de volgende gebruiksvoorbeelden te overwegen voor grote productiviteitsvoordelen.
Gegevenscontrole
U kunt tijdelijke systeemversiebeheer gebruiken voor tabellen die kritieke informatie opslaan, om bij te houden wat er is gewijzigd en wanneer, en om op elk moment forensische gegevens uit te voeren.
Met tijdelijke tabellen kunt u scenario's voor gegevenscontrole plannen in de vroege fasen van de ontwikkelingscyclus of gegevenscontrole toevoegen aan bestaande toepassingen of oplossingen wanneer u deze nodig hebt.
In het volgende diagram ziet u een Employee tabel met het gegevensvoorbeeld, inclusief huidige (gemarkeerd met een blauwe kleur) en historische rijversies (gemarkeerd met een grijze kleur).
Het rechtergedeelte van het diagram visualiseert rijversies op een tijdsas en de rijen die u selecteert met verschillende typen query's in een tijdelijke tabel, met of zonder de SYSTEM_TIME component.

Systeemversiebeheer inschakelen voor een nieuwe tabel voor gegevenscontrole
Als u informatie identificeert die gegevens moet controleren, maakt u databasetabellen als tijdelijke tabellen met systeemversies. In het volgende voorbeeld ziet u een scenario met een tabel met de naam Employee in een hypothetische HR-database:
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
Verschillende opties voor het maken van een tijdelijke tabel met systeemversies worden beschreven in Een systeemversie van een tijdelijke tabel maken.
Systeemversiebeheer inschakelen voor een bestaande tabel voor gegevenscontrole
Als u een data-audit in bestaande databases wilt uitvoeren, gebruikt u ALTER TABLE om niet-temporele tabellen uit te breiden tot systeemversie-tabellen. Als u wijzigingen die fouten veroorzaken in uw toepassing wilt voorkomen, voegt u puntkolommen toe als HIDDEN, zoals wordt uitgelegd in Een tijdelijke tabel met systeemversies maken.
Het volgende voorbeeld illustreert het inschakelen van systeemversiebeheer op een bestaande Employee tabel in een hypothetische HR-database. Het maakt systeemversiebeheer in de Employee tabel in twee stappen mogelijk. Eerst worden er nieuwe periodekolommen toegevoegd als HIDDEN. Vervolgens wordt de standaardgeschiedenistabel gemaakt.
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Belangrijk
De precisie van het datum/tijd2 gegevenstype moet hetzelfde zijn in de brontabel als in de systeemversie van de geschiedenistabel.
Nadat u het vorige script hebt uitgevoerd, worden alle gegevenswijzigingen transparant verzameld in de geschiedenistabel. In een typisch scenario voor gegevenscontrole zou u een query uitvoeren op alle gegevenswijzigingen die binnen een bepaalde periode van belang zijn toegepast op een afzonderlijke rij. De standaardgeschiedenistabel wordt gemaakt met een geclusterde B-boomstructuur voor rijopslag om deze use-case efficiënt te verhelpen.
Notitie
Documentatie maakt gebruik van de term B-tree in het algemeen in verwijzing naar indexen. In rijstore-indexen implementeert de database-engine een B+-boom. Dit geldt niet voor columnstore-indexen of indexen voor tabellen die zijn geoptimaliseerd voor geheugen. Zie de SQL Server- en Azure SQL-indexarchitectuur en ontwerphandleidingvoor meer informatie.
Gegevensanalyse uitvoeren
Nadat u systeemversiebeheer hebt ingeschakeld met een van de vorige benaderingen, is gegevensauditing met slechts één query mogelijk. Met de volgende query wordt gezocht naar rijversies voor records in de Employee tabel, met EmployeeID = 1000 die ten minste een deel van de periode tussen 1 januari 2021 en 1 januari 2022 actief waren (inclusief de bovengrens):
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Vervang FOR SYSTEM_TIME BETWEEN...AND door FOR SYSTEM_TIME ALL om de volledige geschiedenis van gegevenswijzigingen voor die specifieke werknemer te analyseren:
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Gebruik CONTAINED INom te zoeken naar rijversies die alleen binnen een bepaalde periode actief waren (en niet daarbuiten). Deze query is efficiënt omdat er alleen query's worden uitgevoerd op de geschiedenistabel:
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Ten slotte wilt u in sommige controlescenario's misschien zien hoe de hele tabel er op elk moment in het verleden uitzag:
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
In tijdelijke tabellen met systeemversies worden waarden opgeslagen voor periodekolommen in de UTC-tijdzone, maar het is misschien handiger om in uw lokale tijdzone te werken, zowel voor het filteren van gegevens als het weergeven van resultaten. In het volgende codevoorbeeld ziet u hoe u een filtervoorwaarde toepast, die is opgegeven in de lokale tijdzone en vervolgens wordt geconverteerd naar UTC met behulp van AT TIME ZONE, die is geïntroduceerd in SQL Server 2016 (13.x):
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
Het gebruik van AT TIME ZONE is handig in alle andere scenario's waarin tabellen met systeemversies worden gebruikt.
Filtervoorwaarden die zijn opgegeven in tijdelijke clausules met FOR SYSTEM_TIME zijn geschikt voor SARG-optimalisatie. SARG staat voor zoekargumenten SARG-functionaliteit betekent dat SQL Server de onderliggende geclusterde index kan gebruiken om een zoekopdracht uit te voeren in plaats van een scanbewerking. Zie SQL Server-indexarchitectuur en ontwerphandleidingvoor meer informatie.
Als u rechtstreeks een query op de geschiedenistabel uitvoert, moet u ervoor zorgen dat uw filtervoorwaarde ook SARG-geschikt is door filters op te geven in de vorm van <period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC'.
Als u AT TIME ZONE toepast op puntkolommen, voert SQL Server een tabel- of indexscan uit, wat erg duur kan zijn. Vermijd dit type voorwaarde in uw query's:
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition.
Zie Querygegevens in een tijdelijke tabel met systeemversiesvoor meer informatie.
Analyse op een specifiek tijdstip (tijdgebonden analyse)
In plaats van te focussen op wijzigingen in afzonderlijke records, laten scenario's voor tijdreizen zien hoe hele gegevenssets in de loop van de tijd veranderen. Soms omvat tijdreizen verschillende gerelateerde tijdelijke tabellen, elk veranderend in onafhankelijk tempo, waarvoor u het volgende wilt analyseren:
- Trends voor de belangrijke indicatoren in de historische en huidige gegevens
- Exacte momentopname van de volledige gegevens 'vanaf' een bepaald tijdstip in het verleden (gisteren, een maand geleden, enzovoort)
- Verschillen tussen twee tijdstippen van belang (bijvoorbeeld een maand geleden versus drie maanden geleden)
Er zijn veel praktijkscenario's waarvoor tijdreisanalyse is vereist. Om dit gebruiksscenario te illustreren, kijken we naar OLTP met automatisch gegenereerde geschiedenis.
OLTP met automatisch gegenereerde gegevensgeschiedenis
In transactieverwerkingssystemen kunt u analyseren hoe belangrijke metrische gegevens in de loop van de tijd veranderen. In het ideale geval moet het analyseren van de geschiedenis geen inbreuk maken op de prestaties van de OLTP-toepassing waar toegang tot de meest recente status van gegevens moet plaatsvinden met minimale latentie en gegevensvergrendeling. U kunt tijdelijke tabellen met systeemversies gebruiken om transparant de volledige geschiedenis van wijzigingen te bewaren voor latere analyse, afzonderlijk van de huidige gegevens, met een minimale impact op de belangrijkste OLTP-workload.
Voor workloads met hoge transactionele verwerking in SQL Server en Azure SQL Managed Instance raden we u aan om systeem-versiebeheer tijdelijke tabellen met geheugen-geoptimaliseerde tabellente gebruiken, zodat u huidige gegevens in het geheugen kunt opslaan en de volledige wijzigingsgeschiedenis kostenefficiënt op schijf kunt bewaren.
Voor de geschiedenistabel raden we u aan om een geclusterde columnstore-index te gebruiken om de volgende redenen:
Typische trendanalyses hebben baat bij de queryprestaties die worden geleverd door een columnstore-clusterindex.
De taak voor het leegmaken van gegevens met tabellen die zijn geoptimaliseerd voor geheugen, presteert het beste onder zware OLTP-werkbelasting wanneer de geschiedenistabel een geclusterde columnstore-index heeft.
Een geclusterde columnstore-index biedt uitstekende compressie, met name in scenario's waarin niet alle kolommen tegelijkertijd worden gewijzigd.
Het gebruik van tijdelijke tabellen met OLTP in het geheugen vermindert de noodzaak om de volledige gegevensset in het geheugen te bewaren en stelt u in staat om eenvoudig onderscheid te maken tussen dynamische en koude gegevens.
Voorbeelden van de praktijkscenario's die goed in deze categorie passen, zijn onder andere voorraadbeheer of valutahandel.
In het volgende diagram ziet u een vereenvoudigd gegevensmodel dat wordt gebruikt voor voorraadbeheer:

In het volgende codevoorbeeld wordt ProductInventory gemaakt als een in-memory systeemversie tijdgebonden tabel, met een geclusterde columnstore-index op de geschiedenistabel (die de rijopslagindex vervangt die standaard is gemaakt):
Notitie
Zorg ervoor dat uw database het mogelijk maakt om tabellen te maken die zijn geoptimaliseerd voor geheugen. Zie Een Memory-Optimized-tabel en een systeemeigen opgeslagen procedure maken.
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
Voor het vorige model ziet u hoe de procedure voor het onderhouden van voorraad eruit kan zien:
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
De spUpdateInventory opgeslagen procedure voegt een nieuw product in de voorraad in of werkt de producthoeveelheid voor de specifieke locatie bij. De bedrijfslogica is eenvoudig en gericht op het voortdurend onderhouden van de meest recente status door het Quantity veld te verhogen/verlagen via tabelupdate, terwijl systeemversietabellen transparant geschiedenisdimensie toevoegen aan de gegevens, zoals wordt weergegeven in het volgende diagram.

U kunt nu efficiënt query's uitvoeren op de meest recente status vanuit de systeemeigen gecompileerde module:
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
Het analyseren van gegevenswijzigingen in de loop van de tijd wordt eenvoudig met de FOR SYSTEM_TIME ALL-component, zoals wordt weergegeven in het volgende voorbeeld:
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
In het volgende diagram ziet u de gegevensgeschiedenis voor één product dat eenvoudig kan worden weergegeven bij het importeren van de vorige weergave in Power Query, Power BI of een vergelijkbaar hulpprogramma voor business intelligence:

Tijdelijke tabellen kunnen in dit scenario worden gebruikt om andere typen tijdreisanalyses uit te voeren, zoals het reconstrueren van de status van de inventaris AS OF een bepaald tijdstip in het verleden of het vergelijken van momentopnamen die tot verschillende momenten in de tijd behoren.
Voor dit gebruiksscenario kunt u de tabellen Product en Locatie ook uitbreiden naar tijdelijke tabellen om later een analyse van de geschiedenis van UnitPrice en NumberOfEmployeemogelijk te maken.
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Aangezien het gegevensmodel nu meerdere tijdelijke tabellen omvat, is de aanbevolen procedure voor AS OF analyse om een weergave te maken waarmee de benodigde gegevens uit de gerelateerde tabellen worden geëxtraheerd en FOR SYSTEM_TIME AS OF op de weergave worden toegepast, omdat dit het reconstrueren van de status van het hele gegevensmodel aanzienlijk vereenvoudigt:
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
In de volgende schermopname ziet u het uitvoeringsplan dat is gegenereerd voor de SELECT-query. Dit illustreert dat de database-engine alle complexiteit afhandelt bij het omgaan met tijdelijke relaties:

Gebruik de volgende code om de status van de productinventaris te vergelijken tussen twee tijdstippen (een dag geleden en een maand geleden):
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Anomaliedetectie
Anomaliedetectie (of uitbijterdetectie) is de identificatie van items die niet voldoen aan een verwacht patroon of andere items in een gegevensset. U kunt tijdelijke tabellen met systeemversies gebruiken om afwijkingen te detecteren die periodiek of onregelmatig optreden, omdat u tijdelijke query's kunt gebruiken om snel specifieke patronen te vinden. Wat afwijking is, is afhankelijk van het type gegevens dat u verzamelt en uw bedrijfslogica.
In het volgende voorbeeld ziet u vereenvoudigde logica voor het detecteren van pieken in verkoopcijfers. Stel dat u met een tijdelijke tabel werkt die de geschiedenis van de gekochte producten verzamelt:
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
In het volgende diagram ziet u de aankopen in de loop van de tijd:

Ervan uitgaande dat het aantal gekochte producten gedurende de normale dagen een kleine variantie heeft, identificeert de volgende query enkele uitbijters: steekproeven waarvan het verschil met hun directe buren significant is (2x), terwijl de omringende waarnemingen niet aanzienlijk verschillen (minder dan 20%).
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Notitie
Dit voorbeeld is opzettelijk vereenvoudigd. In de productiescenario's gebruikt u waarschijnlijk geavanceerde statistische methoden om steekproeven te identificeren die niet voldoen aan het algemene patroon.
Langzaam veranderende dimensies
Dimensies in datawarehousing bevatten doorgaans relatief statische gegevens over entiteiten, zoals geografische locaties, klanten of producten. In sommige scenario's moet u echter ook gegevenswijzigingen in dimensietabellen bijhouden. Aangezien wijzigingen in dimensies veel minder vaak plaatsvinden, worden deze typen dimensies op onvoorspelbare wijze en buiten het normale updateschema dat van toepassing is op feitentabellen, langzaam veranderende dimensies (SCD) genoemd.
Er zijn verschillende categorieën van langzaam veranderende dimensies op basis van hoe de geschiedenis van wijzigingen behouden blijft:
| Dimensietype | Bijzonderheden |
|---|---|
| type 0 | Geschiedenis blijft niet behouden. Dimensiekenmerken weerspiegelen oorspronkelijke waarden. |
| type 1 | Dimensiekenmerken weerspiegelen de meest recente waarden (eerdere waarden worden overschreven) |
| Type 2 | Elke versie van het dimensielid die wordt weergegeven met een afzonderlijke rij in de tabel, meestal met kolommen die de geldigheidsperiode vertegenwoordigen |
| type 3 | Beperkte geschiedenis voor geselecteerde kenmerken behouden met behulp van extra kolommen in dezelfde rij |
| type 4 | Geschiedenis in de afzonderlijke tabel behouden terwijl de oorspronkelijke dimensietabel de meest recente (huidige) dimensielidversies bewaart |
Wanneer u een SCD-strategie kiest, is dit de verantwoordelijkheid van de ETL-laag (Extract-Transform-Load) om dimensietabellen nauwkeurig te houden, wat meestal complexere code en extra onderhoud vereist.
Tijdelijke tabellen met systeemversies kunnen worden gebruikt om de complexiteit van uw code aanzienlijk te verlagen omdat de geschiedenis van gegevens automatisch wordt bewaard. Gezien de implementatie met behulp van twee tabellen, bevinden tijdelijke tabellen zich het dichtst bij type 4 SCD. Aangezien tijdelijke query's u echter alleen naar de huidige tabel laten verwijzen, kunt u ook tijdelijke tabellen overwegen in omgevingen waarin u van plan bent type 2 SCD te gebruiken.
Als u uw reguliere dimensie wilt converteren naar SCD, kunt u een nieuwe dimensie maken of een bestaande wijzigen om een tijdelijke tabel met systeemversies te worden. Als uw bestaande dimensietabel historische gegevens bevat, maakt u een afzonderlijke tabel en verplaatst u daar historische gegevens en behoudt u actuele (werkelijke) dimensieversies in de oorspronkelijke dimensietabel. Gebruik vervolgens ALTER TABLE-syntaxis om uw dimensietabel om te zetten naar een systeemgeversioneerde tijdstabel met een vooraf gedefinieerde geschiedenistabel.
In het volgende voorbeeld ziet u het proces en wordt ervan uitgegaan dat de dimensietabel DimLocation al ValidFrom en ValidTo heeft als datum/tijd2 niet-nullbare kolommen, die worden ingevuld door het ETL-proces:
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
Er is geen extra code vereist voor het onderhouden van SCD tijdens het laadproces van het datawarehouse zodra u deze hebt gemaakt.
In de volgende afbeelding ziet u hoe u tijdelijke tabellen kunt gebruiken in een eenvoudig scenario met twee SCD's (DimLocation en DimProduct) en één feitentabel.

Om eerdere SCD's in rapporten te gebruiken, moet u de query-instellingen op doeltreffende wijze aanpassen. U kunt bijvoorbeeld het totale verkoopbedrag en het gemiddelde aantal verkochte producten per hoofd van de afgelopen zes maanden berekenen. Beide metrische gegevens vereisen de correlatie van gegevens uit de feitentabel en dimensies die hun kenmerken mogelijk hebben gewijzigd die belangrijk zijn voor de analyse (DimLocation.NumOfCustomers, DimProduct.UnitPrice). Met de volgende query worden de vereiste metrische gegevens correct berekend:
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
Overwegingen
Het gebruik van tijdelijke tabellen met systeemversies voor SCD is acceptabel als de geldigheidsperiode die is berekend op basis van de transactietijd van de database, in orde is met uw bedrijfslogica. Als u gegevens met een aanzienlijke vertraging laadt, is transactietijd mogelijk niet acceptabel.
Tijdelijke tabellen met systeemversies staan standaard niet toe dat historische gegevens na het laden worden gewijzigd (u kunt de geschiedenis wijzigen nadat u SYSTEM_VERSIONING hebt ingesteld op OFF). Dit kan een beperking zijn in gevallen waarin het wijzigen van historische gegevens regelmatig plaatsvindt.
Tijdelijke systeemversietabellen genereren rijversie bij elke kolomwijziging. Als u nieuwe versies van bepaalde kolomwijziging wilt onderdrukken, moet u die beperking opnemen in de ETL-logica.
Als u een aanzienlijk aantal historische rijen in SCD-tabellen verwacht, kunt u overwegen om een geclusterde columnstore-index te gebruiken als de belangrijkste opslagoptie voor de geschiedenistabel. Het gebruik van een columnstore-index vermindert de footprint van de geschiedenistabel en versnelt uw analytische query's.
Beschadigde gegevens op rijniveau corrigeren
U kunt vertrouwen op historische gegevens in tijdelijke tabellen met systeemversies om snel afzonderlijke rijen te herstellen naar een van de eerder vastgelegde statussen. Deze eigenschap van tijdelijke tabellen is handig wanneer u betrokken rijen kunt vinden en/of wanneer u de tijd van ongewenste gegevenswijziging kent. Met deze kennis kunt u efficiënt herstel uitvoeren zonder dat u te maken hebt met back-ups.
Deze aanpak heeft verschillende voordelen:
U kunt het bereik van de reparatie nauwkeurig beheren. Records die niet worden beïnvloed, moeten de meest recente status hebben, wat vaak een kritieke vereiste is.
De bewerking is efficiënt en de database blijft online voor alle workloads die gebruikmaken van de gegevens.
De herstelbewerking zelf is geversioneerd. U hebt audittrail voor reparatiebewerkingen zelf, zodat u kunt analyseren wat er later gebeurt als dat nodig is.
Herstelactie kan met relatief gemak worden geautomatiseerd. In het volgende codevoorbeeld ziet u een opgeslagen procedure die gegevensherstel uitvoert voor de tabel Employee gebruikt in een scenario voor gegevenscontrole.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
Deze opgeslagen procedure neemt @EmployeeID en @versionNumber als invoerparameters. Met deze procedure wordt standaard de rijstatus hersteld naar de laatste versie uit de geschiedenis (@versionNumber = 1).
In de volgende afbeelding ziet u de status van de rij vóór en na de aanroep van de procedure. Rode rechthoek markeert de huidige rijversie die onjuist is, terwijl de groene rechthoek de juiste versie van de geschiedenis markeert.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

Deze opgeslagen herstelprocedure kan worden gedefinieerd om een exacte tijdstempelwaarde te accepteren in plaats van rowversion. Hiermee wordt de rij hersteld naar een versie die actief was voor het opgegeven tijdstip (dat wil gezegd AS OF tijdstip).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
Voor hetzelfde gegevensvoorbeeld illustreert de volgende afbeelding een herstelscenario met een tijdsvoorwaarde. Gemarkeerd zijn de @asOf parameter, geselecteerde rij in de geschiedenis die werkelijk was op het opgegeven tijdstip en nieuwe rijversie in de huidige tabel na herstelbewerking:

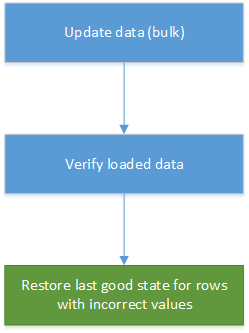
Gegevenscorrectie kan deel uitmaken van geautomatiseerd laden van gegevens in datawarehousing- en rapportagesystemen. Als een nieuwe bijgewerkte waarde niet juist is, is het herstellen van de vorige versie uit de geschiedenis in veel scenario's voldoende oplossing. In het volgende diagram ziet u hoe dit proces kan worden geautomatiseerd:
Verwante inhoud
- tijdelijke tabellen
- Aan de slag met tijdelijke tabellen met systeemversies
- consistentiecontroles van het tijdelijke tabelsysteem
- partitioneren met tijdelijke tabellen
- Tijdelijke tabeloverwegingen en -beperkingen
- tijdelijke tabelbeveiliging
- Systeem-versiebeheerde temporale tabellen met geheugen-geoptimaliseerde tabellen
- weergaven en functies van metagegevens van tijdelijke tabellen