JSON-gegevens indexeren
van toepassing op:![]() SQL Server 2016 (13.x) en hoger
SQL Server 2016 (13.x) en hoger ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
U kunt uw query's optimaliseren via JSON-documenten met behulp van standaardindexen. SQL Server heeft geen aangepaste JSON-indexen.
- Momenteel is in SQL Server json- geen ingebouwd gegevenstype.
- Het JSON-gegevenstype is momenteel in preview voor Azure SQL Database en Azure SQL Managed Instance (geconfigureerd met de Always-up-to-date updatebeleid).
Indexen werken op dezelfde manier op JSON-gegevens in varchar,/nvarchar of het systeemeigen json gegevenstype.
Databaseindexen verbeteren de prestaties van filter- en sorteerbewerkingen. Zonder indexen moet SQL Server elke keer dat u gegevens opvraagt een volledige tabelscan uitvoeren.
JSON-eigenschappen indexeren met behulp van berekende kolommen
Wanneer u JSON-gegevens opslaat in SQL Server, wilt u meestal queryresultaten filteren of sorteren op een of meer eigenschappen van de JSON-documenten.
Voorbeeld
In dit voorbeeld wordt ervan uitgegaan dat de tabel AdventureWorks.SalesOrderHeader een Info kolom bevat met verschillende informatie in JSON-indeling over verkooporders. Het bevat bijvoorbeeld ongestructureerde gegevens over klant, verkoper, verzend- en factureringsadressen, enzovoort. U kunt waarden uit de kolom Info gebruiken om verkooporders voor een klant te filteren.
De kolom die Info wordt gebruikt, bestaat standaard niet, maar kan worden gemaakt in de AdventureWorks-database met de volgende code. De volgende voorbeelden zijn niet van toepassing op de AdventureWorksLT reeks voorbeelddatabases.
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Query voor optimalisatie
Hier volgt een voorbeeld van het type query dat u wilt optimaliseren met behulp van een index.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
Voorbeeldindex
Als u uw filters of ORDER BY-componenten wilt versnellen via een eigenschap in een JSON-document, kunt u dezelfde indexen gebruiken die u al in andere kolommen gebruikt. U kunt echter niet rechtstreeks eigenschappen in de JSON-documenten verwijzen.
- Maak eerst een virtuele kolom die de waarden retourneert die u wilt gebruiken voor filteren.
- Maak vervolgens een index op die virtuele kolom.
In het volgende voorbeeld wordt een berekende kolom gemaakt die kan worden gebruikt voor indexering. Vervolgens wordt er een index gemaakt voor de nieuwe berekende kolom. In dit voorbeeld wordt een kolom gemaakt waarin de naam van de klant wordt weergegeven, die is opgeslagen in het $.Customer.Name pad in de JSON-gegevens.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
Met deze statement wordt de volgende waarschuwing gegeven:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
De functie JSON_VALUE retourneert mogelijk tekstwaarden van maximaal 8000 bytes (bijvoorbeeld als de nvarchar(4000) type). De waarden die langer zijn dan 1700 bytes, kunnen echter niet worden geïndexeerd. Als u de waarde probeert in te voeren in de geïndexeerde berekende kolom die langer is dan 1700 bytes, mislukt de DML-bewerking (Data Manipulat Language).
Probeer voor betere prestaties de waarde die u beschikbaar maakt met behulp van een berekende kolom naar het kleinste toepasselijke gegevenstype te casten. Gebruik int en datetime2 typen in plaats van tekenreekstypen.
Meer informatie over de berekende kolom
Een berekende kolom wordt niet behouden. Een computerkolom wordt alleen berekend wanneer de index opnieuw moet worden opgebouwd. Het neemt geen extra ruimte in de tabel in beslag.
Het is belangrijk dat u de berekende kolom maakt met dezelfde expressie die u wilt gebruiken in uw query's. In dit voorbeeld is de expressie JSON_VALUE(Info, '$.Customer.Name').
U hoeft uw query's niet opnieuw te schrijven. Als u expressies gebruikt met de JSON_VALUE-functie, zoals wordt weergegeven in de voorgaande voorbeeldquery, ziet SQL Server dat er een equivalente berekende kolom met dezelfde expressie is en dat er indien mogelijk een index wordt toegepast.
Uitvoeringsplan voor dit voorbeeld
Hier volgt het uitvoeringsplan voor de query in dit voorbeeld.
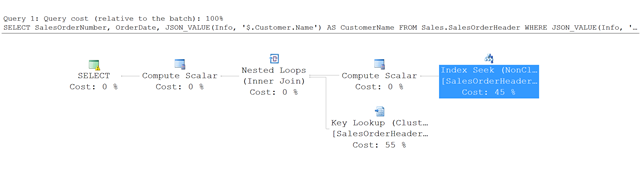
In plaats van een volledige tabelscan gebruikt SQL Server een indexzoekfunctie in de niet-geclusterde index en vindt u de rijen die voldoen aan de opgegeven voorwaarden. Vervolgens wordt een sleutelzoekactie in de SalesOrderHeader tabel gebruikt om de andere kolommen op te halen waarnaar in de query wordt verwezen, in dit voorbeeld SalesOrderNumber en OrderDate.
De index verder optimaliseren met opgenomen kolommen
Als u vereiste kolommen in de index toevoegt, kunt u deze extra zoekactie in de tabel voorkomen. U kunt deze kolommen toevoegen als standaard opgenomen kolommen, zoals wordt weergegeven in het volgende voorbeeld, waarmee het voorgaande CREATE INDEX voorbeeld wordt uitgebreid.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
In dit geval hoeft SQL Server geen extra gegevens uit de SalesOrderHeader tabel te lezen, omdat alles wat nodig is in de niet-geclusterde JSON-index is opgenomen. Dit type index is een goede manier om JSON- en kolomgegevens in query's te combineren en optimale indexen te maken voor uw workload.
JSON-indexen zijn sorteringsbewuste indexen
Een belangrijke functie van indexen via JSON-gegevens is dat de indexen sorteringsbewust zijn. Het resultaat van de JSON_VALUE-functie die u gebruikt bij het maken van de berekende kolom is een tekstwaarde die de sortering overneemt van de invoerexpressie. Daarom worden waarden in de index geordend met behulp van de sorteringsregels die zijn gedefinieerd in de bronkolommen.
Om te laten zien dat de indexen sorteringsbewust zijn, maakt het volgende voorbeeld een eenvoudige verzamelingstabel met een primaire sleutel en JSON-inhoud.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
Met de voorgaande opdracht wordt de Servische Cyrillische sortering voor de kolom json gespecificeerd. In het volgende voorbeeld wordt de tabel gevuld en wordt een index gemaakt voor de naameigenschap.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
Met de voorgaande opdrachten maakt u een standaardindex op de berekende kolom vName, die de waarde van de eigenschap JSON $.name vertegenwoordigt. Op de servische cyrillische codepagina is de volgorde van de letters А, Б, В, Г, Д, Ђ, Е, enzovoort. De volgorde van items in de index voldoet aan de Servische Cyrillische regels omdat het resultaat van de functie JSON_VALUE de sortering van de bronkolom overneemt. In het volgende voorbeeld wordt een query uitgevoerd op deze verzameling en worden de resultaten gesorteerd op naam.
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
Als u het werkelijke uitvoeringsplan bekijkt, ziet u dat er gebruik wordt gemaakt van gesorteerde waarden uit de niet-geclusterde index.

Hoewel de query een ORDER BY-component heeft, maakt het uitvoeringsplan geen gebruik van een sorteeroperator. De JSON-index is al geordend volgens de Servische Cyrillische regels. Daarom kan SQL Server de niet-geclusterde index gebruiken waar de resultaten al zijn gesorteerd.
Als u echter de sortering van de ORDER BY-expressie wijzigt, bijvoorbeeld als u COLLATE French_100_CI_AS_SC toevoegt na de functie JSON_VALUE, krijgt u een ander uitvoeringsplan voor query's.

Omdat de volgorde van waarden in de index niet compatibel is met Franse sorteringsregels, kan SQL Server de index niet gebruiken om resultaten te ordenen. Daarom wordt een sorteeroperator toegevoegd waarmee resultaten worden gesorteerd met behulp van Franse sorteringsregels.
Microsoft video's
Notitie
Sommige videokoppelingen in deze sectie werken momenteel mogelijk niet. Microsoft migreert de inhoud die voorheen op het platform Channel 9 stond naar een nieuw platform. We werken de koppelingen bij naarmate de video's naar het nieuwe platform worden gemigreerd.
Zie de volgende video's voor een visuele inleiding tot de ingebouwde JSON-ondersteuning in SQL Server en Azure SQL Database:
Verwante inhoud
- JSON-verwerking optimaliseren met OLTP- in het geheugen
- JSON-gegevens in SQL Server
- JSON-gegevenstype