Columnstore-indexen: Overzicht
van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-database in Microsoft Fabric
SQL-database in Microsoft Fabric
Columnstore-indexen zijn de standaard voor het opslaan en opvragen van grote feitentabellen voor datawarehousing. Deze index maakt gebruik van op kolommen gebaseerde gegevensopslag en queryverwerking om tot 10 keer de queryprestaties in uw datawarehouse te verkrijgen ten opzichte van traditionele rijgeoriënteerde opslag. U kunt ook tot 10 keer meer gegevenscompressie bereiken dan de niet-gecomprimeerde gegevensgrootte. Vanaf SQL Server 2016 (13.x) SP1 maken columnstore-indexen operationele analyses mogelijk: de mogelijkheid om actieve realtime analyses uit te voeren op een transactionele workload.
Meer informatie over een gerelateerd scenario:
- Columnstore-indexen in data warehousing
- Aan de slag met columnstore voor realtime operationele analyses
Wat is een columnstore-index?
Een columnstore-index is een technologie voor het opslaan, ophalen en beheren van gegevens met behulp van een kolomvormige gegevensindeling, ook wel een columnstore-genoemd.
Belangrijke termen en concepten
De volgende belangrijke termen en concepten zijn gekoppeld aan columnstore-indexen.
Kolomstore
Een columnstore is gegevens die logisch zijn ingedeeld als een tabel met rijen en kolommen, en fysiek zijn opgeslagen in een gegevensindeling die in kolomvorm wordt opgeslagen.
Rowstore
Een rijopslag is gegevens die logisch zijn ingedeeld als een tabel met rijen en kolommen, en fysiek zijn opgeslagen in een gegevensindeling die in rijvorm is opgeslagen. Deze indeling is de traditionele manier om relationele tabelgegevens op te slaan. In SQL Server verwijst rowstore naar een tabel waarin de onderliggende gegevensopslagindeling een heap, een geclusterde index of een tabel is die is geoptimaliseerd voor geheugen.
Notitie
In discussies over columnstore-indexen worden de termen rowstore en columnstore gebruikt om de indeling voor de gegevensopslag te benadrukken.
Rijgroep
Een rijgroep is een groep rijen die tegelijkertijd worden gecomprimeerd in columnstore-indeling. Een rijgroep bevat meestal het maximum aantal rijen per rijgroep, dat 1.048.576 rijen is.
Voor hoge prestaties en hoge compressieverhoudingen segmenteert de columnstore-index de tabel in rijgroepen en comprimeert vervolgens elke rijgroep per kolom. Het aantal rijen in de rijgroep moet groot genoeg zijn om de compressiesnelheden te verbeteren en klein genoeg om te profiteren van in-memory bewerkingen.
Een rijgroep van waaruit alle gegevens zijn verwijderd, verandert van GECOMPRIMEERD in TOMBSTONE-status en wordt later verwijderd door een achtergrondproces met de naam tuple-mover. Voor meer informatie over rijgroepstatussen, zie sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Tip
Als u te veel kleine rijengroepen hebt, wordt de kwaliteit van de columnstore-index verlaagd. TotDAT SQL Server 2017 (14.x) is een herorganisatiebewerking vereist voor het samenvoegen van kleinere gecomprimeerde rijgroepen, volgens een intern drempelwaardebeleid dat bepaalt hoe verwijderde rijen moeten worden verwijderd en de gecomprimeerde rijgroepen moeten worden gecombineerd.
Vanaf SQL Server 2019 (15.x) werkt een achtergrondsamenvoegtaak ook om GECOMPRIMEERDE rijengroepen samen te voegen waaruit een groot aantal rijen is verwijderd.
Na het samenvoegen van kleinere rijgroepen moet de indexkwaliteit worden verbeterd.
Notitie
Vanaf SQL Server 2019 (15.x), Azure SQL Database, Azure SQL Managed Instance en toegewezen SQL-pools in Azure Synapse Analytics wordt de tuple-mover geholpen door een samenvoegtaak op de achtergrond waarmee automatisch kleinere OPEN Delta-rijgroepen worden gecomprimeerd die al enige tijd bestaan, zoals bepaald door een interne drempelwaarde, of gecomprimeerde rijgroepen worden samengevoegd waaruit een groot aantal rijen is verwijderd. Dit verbetert de kwaliteit van de columnstore-index in de loop van de tijd.
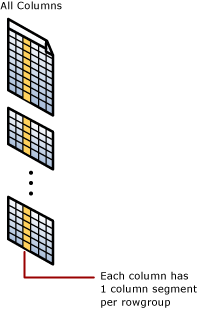
Kolomsegment
Een kolomsegment is een kolom met gegevens uit de rijgroep.
- Elke rijgroep bevat één kolomsegment voor elke kolom in de tabel.
- Elk kolomsegment wordt samen gecomprimeerd en opgeslagen op fysieke media.
- Er zijn metagegevens voor elk segment, zodat segmenten snel kunnen worden verwijderd zonder ze te lezen.
Geclusterde columnstore-index
Een geclusterde columnstore-index is de fysieke opslag voor de hele tabel.
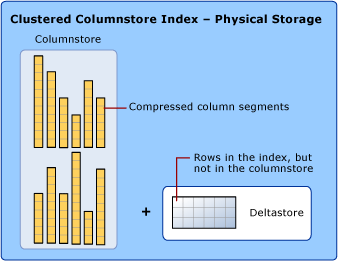
Om de fragmentatie van de kolomsegmenten te verminderen en de prestaties te verbeteren, kunnen sommige gegevens tijdelijk worden opgeslagen in een geclusterde index, een deltastore- en een B-structuurlijst met id's voor verwijderde rijen. De deltastore-bewerkingen worden achter de schermen afgehandeld. Als u de juiste queryresultaten wilt retourneren, combineert de geclusterde columnstore-index queryresultaten uit zowel de columnstore als de deltastore.
Notitie
Documentatie maakt gebruik van de term B-tree in het algemeen in verwijzing naar indexen. In rijstore-indexen implementeert de Database Engine een B+-boom. Dit geldt niet voor columnstore-indexen of indexen voor tabellen die zijn geoptimaliseerd voor geheugen. Zie de SQL Server- en Azure SQL-indexarchitectuur en ontwerphandleidingvoor meer informatie.
Delta-rijgroep
Een deltarijgroep is een geclusterde B-tree-index die alleen wordt gebruikt met columnstore-indexen. Het verbetert de columnstore-compressie en prestaties door rijen op te slaan totdat het aantal rijen een drempelwaarde bereikt (1.048.576 rijen) en vervolgens naar de columnstore worden verplaatst.
Wanneer een deltarijgroep het maximum aantal rijen bereikt, wordt deze overgestapt van de status OPEN naar GESLOTEN. Een achtergrondproces met de naam tuple-mover controleert op gesloten rijgroepen. Als in het proces een gesloten rijgroep wordt gevonden, wordt de deltarijgroep gecomprimeerd en opgeslagen in de columnstore als een gecomprimeerde rijgroep.
Wanneer een deltarijgroep is gecomprimeerd, verandert de bestaande deltarijgroep naar de TOMBSTONE-status en wordt deze later door de tuple-mover verwijderd wanneer er geen verwijzingen meer naar zijn.
Voor meer informatie over rijgroepstatussen, zie sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Notitie
Vanaf SQL Server 2019 (15.x) wordt de tuple-mover geholpen door een samenvoegtaak op de achtergrond waarmee automatisch kleinere OPEN Delta-rijgroepen worden gecomprimeerd die al enige tijd bestaan, zoals bepaald door een interne drempelwaarde, of worden GECOMPRIMEERDE rijgroepen samengevoegd waaruit een groot aantal rijen is verwijderd. Dit verbetert de kwaliteit van de columnstore-index in de loop van de tijd.
Deltastore
Een columnstore-index kan meer dan één delta-rijgroep hebben. Alle deltarijgroepen samen worden de deltastore genoemd.
Tijdens een grote bulklading gaan de meeste rijen rechtstreeks naar de columnstore zonder door de deltastore te gaan. Sommige rijen aan het einde van de bulkbelasting zijn mogelijk te weinig in aantal om te voldoen aan de minimale grootte van een rijgroep, namelijk 102.400 rijen. Als gevolg hiervan gaan de laatste rijen naar de deltastore in plaats van de columnstore. Voor kleine bulkbeladingen met minder dan 102.400 rijen gaan al deze rijen rechtstreeks naar de deltastore.
Niet-geclusterde columnstore-index
Een niet-geclusterde columnstore-index en een geclusterde columnstore-index functioneren op dezelfde manier. Het verschil is dat een niet-geclusterde index een secundaire index is die wordt gemaakt in een rowstore-tabel, maar een geclusterde columnstore-index is de primaire opslag voor de hele tabel.
De niet-geclusterde index bevat een kopie van een deel of alle rijen en kolommen in de onderliggende tabel. De index wordt gedefinieerd als een of meer kolommen van de tabel en heeft een optionele voorwaarde waarmee de rijen worden gefilterd.
Een niet-geclusterde columnstore-index maakt realtime operationele analyses mogelijk waarbij de OLTP-workload gebruikmaakt van de onderliggende geclusterde index terwijl analyses gelijktijdig worden uitgevoerd op de columnstore-index. Zie Aan de slag met columnstore voor realtime operationele analysesvoor meer informatie.
Uitvoering van batchmodus
Batchmodus uitvoeren is een queryverwerkingsmethode die wordt gebruikt om meerdere rijen samen te verwerken. De uitvoering van batchmodus is nauw geïntegreerd met en geoptimaliseerd rond de columnstore-opslagindeling. Uitvoering van batchmodus wordt ook wel vectorgebaseerde of vectorized uitvoering genoemd. Query's in columnstore-indexen maken gebruik van batchmodusuitvoering, waardoor de queryprestaties doorgaans twee tot vier keer worden verbeterd. Zie de architectuurhandleiding voor queryverwerkingvoor meer informatie.
Waarom moet ik een columnstore-index gebruiken?
Een columnstore-index kan een zeer hoog gegevenscompressieniveau bieden, meestal met 10 keer, om de opslagkosten van uw datawarehouse aanzienlijk te verlagen. Voor analyse biedt een columnstore-index een orde van grootte betere prestaties dan een B-tree-index. Columnstore-indexen zijn de voorkeursindeling voor gegevensopslag voor datawarehousing- en analyseworkloads. Vanaf SQL Server 2016 (13.x) kunt u columnstore-indexen gebruiken voor realtime analyses voor uw operationele workload.
Redenen waarom columnstore-indexen zo snel zijn:
Kolommen slaan waarden op uit hetzelfde domein en hebben vaak vergelijkbare waarden, wat resulteert in hoge compressiesnelheden. I/O-knelpunten in uw systeem worden geminimaliseerd of geëlimineerd en de geheugenvoetafdruk wordt aanzienlijk verminderd.
Hoge compressiesnelheden verbeteren de queryprestaties met behulp van een kleinere footprint in het geheugen. Op zijn beurt kunnen queryprestaties worden verbeterd omdat SQL Server meer query- en gegevensbewerkingen in het geheugen kan uitvoeren.
Batchuitvoering verbetert de queryprestaties, meestal twee tot vier keer, door meerdere rijen samen te verwerken.
Query's selecteren vaak slechts enkele kolommen uit een tabel, waardoor de totale I/O van de fysieke media wordt verminderd.
Wanneer moet ik een columnstore-index gebruiken?
Aanbevolen gebruiksvoorbeelden:
Gebruik een geclusterde kolomopslagindex om feitentabellen en grote dimensietabellen op te slaan voor data warehousing workloads. Deze methode verbetert de queryprestaties en gegevenscompressie tot 10 keer. Zie voor meer informatie Columnstore-indexen voor datawarehousing.
Gebruik een niet-geclusterde columnstore-index om in realtime een analyse uit te voeren op een OLTP-workload. Zie Aan de slag met columnstore voor realtime operationele analysesvoor meer informatie.
Zie Kies de beste columnstore-index voor uw behoeftenvoor meer gebruiksscenario's voor columnstore-indexen.
Hoe kan ik kiezen tussen een rowstore-index en een columnstore-index?
Rowstore-indexen presteren het beste voor query's die naar de gegevens zoeken, bij het zoeken naar een bepaalde waarde of voor query's op een klein bereik met waarden. Gebruik rowstore-indexen met transactionele werkbelastingen omdat ze meestal tabelzoekopdrachten vereisen in plaats van tabelscans.
Columnstore-indexen bieden hoge prestatieverbeteringen voor analysequery's die grote hoeveelheden gegevens scannen, met name op grote tabellen. Gebruik columnstore-indexen voor datawarehousing- en analyseworkloads, met name voor feitentabellen, omdat ze meestal volledige tabelscans vereisen in plaats van tabelzoekopdrachten.
Geordende columnstore-indexen verbeteren de prestaties voor query's op basis van geordende kolompredicaten. Geordende columnstore-indexen kunnen de afschaffing van rijgroepen verbeteren, wat prestatieverbeteringen kan opleveren door rijgroepen helemaal over te slaan. Zie Prestaties afstemmen met geordende columnstore-indexenvoor meer informatie. Zie Beschikbaarheid van geordende kolomindexenvoor geordende beschikbaarheid van columnstore-indexen.
Kan ik rowstore en columnstore combineren in dezelfde tabel?
Ja. Vanaf SQL Server 2016 (13.x) kunt u een updatable niet-geclusterde columnstore-index maken in een rowstore-tabel. In de columnstore-index wordt een kopie van de geselecteerde kolommen opgeslagen, dus u hebt extra ruimte nodig voor deze gegevens, maar de geselecteerde gegevens worden gemiddeld 10 keer gecomprimeerd. U kunt tegelijkertijd analyses uitvoeren op de columnstore-index en transacties in de rowstore-index. De columnstore wordt bijgewerkt wanneer de gegevens in de rowstore-tabel worden gewijzigd, zodat beide indexen op dezelfde gegevens werken.
Vanaf SQL Server 2016 (13.x) kunt u een of meer niet-geclusterde rowstore-indexen in een columnstore-index hebben en efficiënte tabelzoekopdrachten uitvoeren op de onderliggende columnstore. Er zijn ook andere opties beschikbaar. U kunt bijvoorbeeld een primaire sleutelbeperking afdwingen met behulp van een UNIQUE-beperking in de rowstore-tabel. Omdat een niet-unieke waarde faalt om ingevoegd te worden in de rowstore-tabel, kan SQL Server de waarde niet invoegen in de columnstore-tabel.
Gesorteerde columnstore-indexen
Door efficiënte segmentverwijdering mogelijk te maken, bieden geordende columnstore-indexen snellere prestaties door grote hoeveelheden geordende gegevens over te slaan die niet overeenkomen met het querypredicaat. Het laden van gegevens in een geordende columnstore-index kan langer duren dan in een niet-geordende index vanwege de sorteerbewerking voor gegevens, maar met geordende columnstore-indexen kunnen query's later sneller worden uitgevoerd.
- Zie voor meer informatie over het afstemmen van prestaties van datawarehousingworkloads in de SQL Database Engine met geordende columnstore-indexen.
- Zie Kies de beste columnstore-index voor uw behoeftenvoor meer informatie over wanneer u welk type columnstore-index moet gebruiken.
Beschikbaarheid van geordende columnstore-indexen
Voor het eerst geïntroduceerd met ![]() SQL Server 2022 (16.x), zijn geordende columnstore-indexen beschikbaar op de volgende platforms:
SQL Server 2022 (16.x), zijn geordende columnstore-indexen beschikbaar op de volgende platforms:
| Perron | Geordende geclusterde columnstore-indexen | Geordende niet-geclusterde columnstore-indexen |
|---|---|---|
| Azure SQL Database | Ja | Ja |
| Azure SQL Managed InstanceAUTD | Ja | Ja |
| Azure SQL Managed Instance2022 | Ja | Nee |
| SQL-database in Microsoft Fabric | Ja1 | Ja |
| SQL Server 2022 (16.x) | Ja | Nee |
| Toegewezen SQL-pool in Azure Synapse Analytics | Ja | Nee |
AUTD- Geldt voor Azure SQL Managed Instance die is geconfigureerd met het Always-up-to-date updatebeleid.
2022 Is van toepassing op Azure SQL Managed Instance dat is geconfigureerd met het updatebeleid voor SQL Server 2022.
1In Fabric SQL-database worden tabellen met geclusterde columnstore-indexen niet gespiegeld naar Fabric OneLake.
Metagegevens
Alle kolommen in een columnstore-index worden opgeslagen in de metagegevens als opgenomen kolommen. De columnstore-index heeft geen sleutelkolommen.
Gerelateerde taken
Alle relationele tabellen gebruiken 'rowstore' als de onderliggende gegevensindeling, tenzij u aangeeft dat deze als een geclusterde columnstore-index worden gebruikt.
CREATE TABLE maakt een rijopslagtabel, tenzij u de optie WITH CLUSTERED COLUMNSTORE INDEX opgeeft.
Wanneer u een tabel met de instructie CREATE TABLE maakt, kunt u de tabel maken als een columnstore door de optie WITH CLUSTERED COLUMNSTORE INDEX op te geven. Als u al een rowstore-tabel hebt en deze wilt converteren naar een columnstore, kunt u de instructie CREATE COLUMNSTORE INDEX gebruiken.
| Taak | Naslagartikelen | Notities |
|---|---|---|
| Maak een tabel in een columnstore-formaat. | CREATE TABLE (Transact-SQL) | Vanaf SQL Server 2016 (13.x) kunt u de tabel maken als een geclusterde columnstore-index. U hoeft niet eerst een rowstore-tabel te maken en deze vervolgens te converteren naar columnstore. |
| Maak een tabel die is geoptimaliseerd voor geheugen met een columnstore-index. | CREATE TABLE (Transact-SQL) | Vanaf SQL Server 2016 (13.x) kunt u een tabel maken die is geoptimaliseerd voor geheugen met een columnstore-index. De columnstore-index kan ook worden toegevoegd nadat de tabel is gemaakt met behulp van de ALTER TABLE ADD INDEX syntaxis. |
| Converteer een rowstore-tabel naar een columnstore. | MAAK COLUMNSTORE-INDEX (Transact-SQL) AAN | Converteer een bestaande heap of B-tree naar een columnstore. Voorbeelden laten zien hoe bestaande indexen worden verwerkt en ook de naam van de index bij het uitvoeren van deze conversie. |
| Converteer een columnstore-tabel naar een rowstore. | CREATE CLUSTERED INDEX (Transact-SQL) of Converteer een columnstore-tabel terug naar een rowstore-heap | Meestal is deze conversie niet nodig, maar er kunnen momenten zijn waarop u moet converteren. Voorbeelden laten zien hoe u een columnstore converteert naar een heap- of geclusterde index. |
| Een columnstore-index maken in een rowstore-tabel. | MAAK COLUMNSTORE-INDEX (Transact-SQL) AAN | Een rowstore-tabel kan één columnstore-index hebben. Vanaf SQL Server 2016 (13.x) kan de columnstore-index een gefilterde voorwaarde hebben. Voorbeelden geven de basissyntaxis weer. |
| Maak performante indexen voor operationele analyses. | Aan de slag met columnstore voor realtime operationele analyses | Hierin wordt beschreven hoe u complementaire columnstore- en B-tree-indexen maakt, zodat OLTP-query's gebruikmaken van B-tree-indexen en analysequery's gebruikmaken van columnstore-indexen. |
| Maak performante columnstore-indexen voor datawarehousing. | Columnstore-indexen voor dataopslag | Hierin wordt beschreven hoe u B-tree-indexen gebruikt voor columnstore-tabellen om performante query's voor datawarehousing te maken. |
| Gebruik een B-tree-index om een primaire-sleutelbeperking af te dwingen voor een columnstore-index. | Columnstore-indexen voor dataopslag | Laat zien hoe u B-tree- en columnstore-indexen combineert om primaire-sleutelbeperkingen voor de columnstore-index af te dwingen. |
| Een columnstore-index verwijderen. | DROP INDEX (Transact-SQL) | Het verwijderen van een columnstore-index maakt gebruik van de standaard-DROP INDEX syntaxis die B-tree-indexen gebruiken. Door een geclusterde columnstore-index te verwijderen, wordt de columnstore-tabel geconverteerd naar een heap. |
| Een rij verwijderen uit een columnstore-index. | DELETE (Transact-SQL) | Gebruik DELETE (Transact-SQL) om een rij te verwijderen. columnstore-rij: SQL Server markeert de rij als logisch verwijderd, maar maakt de fysieke opslag voor de rij pas vrij als de index opnieuw is opgebouwd. deltastore-rij: SQL Server verwijdert de rij logisch en fysiek. |
| Werk een rij in de columnstore-index bij. | UPDATE (Transact-SQL) | Gebruik UPDATE (Transact-SQL) om een rij bij te werken. columnstore-rij: SQL Server markeert de rij als logisch verwijderd en voegt vervolgens de bijgewerkte rij in de deltastore in. deltastore-rij: SQL Server werkt de rij in de deltastore bij. |
| Gegevens laden in een columnstore-index. | Columnstore indexeert het laden van gegevens | |
| Dwing alle rijen in de deltastore om naar de columnstore te gaan. |
ALTER INDEX (Transact-SQL) ... REBUILDIndexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen |
ALTER INDEX met de optie REBUILD dwingt u alle rijen om naar de columnstore te gaan. |
| Een columnstore-index defragmenteren. | ALTER INDEX (Transact-SQL) |
ALTER INDEX ... REORGANIZE defragmenteert columnstore-indexen online. |
| Tabellen samenvoegen met columnstore-indexen. | SAMENVOEGEN (Transact-SQL) |
Verwante inhoud
- Wat is er nieuw in columnstore-indexen
- Columnstore-indexen - Richtlijnen voor het laden van gegevens
- Columnstore-indexen - Querystatistieken
- Aan de slag met Columnstore voor realtime operationele analyses
- Columnstore-indexen bij datawarehousing
- Defragmenteren van columnstore-indexen
- architectuur en ontwerphandleiding voor SQL Server- en Azure SQL-indexen
- Columnstore-indexarchitectuur
- MAAK COLUMNSTORE-INDEX (Transact-SQL) AAN