Sql Server AlwaysOn-beschikbaarheidsgroep configureren in Windows en Linux (platformoverschrijdend)
van toepassing op:![]() SQL Server 2017 (14.x) en hoger
SQL Server 2017 (14.x) en hoger
In dit artikel worden de stappen uitgelegd voor het maken van een AlwaysOn-beschikbaarheidsgroep (AG) met één replica op een Windows-server en de andere replica op een Linux-server.
Belangrijk
SQL Server-platformoverschrijdende beschikbaarheidsgroepen, waaronder heterogene replica's met volledige ondersteuning voor hoge beschikbaarheid en herstel na noodgevallen, is beschikbaar met DH2i DxEnterprise. Zie SQL Server-beschikbaarheidsgroepen met gemengde besturingssystemenvoor meer informatie.
Bekijk de volgende video voor meer informatie over platformoverschrijdende beschikbaarheidsgroepen met DH2i.
Deze configuratie is platformoverschrijdend omdat de replica's zich op verschillende besturingssystemen bevinden. Gebruik deze configuratie voor migratie van het ene naar het andere platform of herstel na noodgevallen. Deze configuratie biedt geen ondersteuning voor hoge beschikbaarheid.

Voordat u doorgaat, moet u bekend zijn met de installatie en configuratie voor SQL Server-exemplaren in Windows en Linux.
Scenario
In dit scenario bevinden twee servers zich op verschillende besturingssystemen. Een Windows Server 2022 met de naam WinSQLInstance fungeert als host voor de primaire replica. Een Linux-server met de naam LinuxSQLInstance host de secundaire replica.
De beschikbaarheidsgroep configureren
De stappen om de AG te maken zijn dezelfde als de stappen om een AG voor leesschaal-workloadste maken. Het clustertype AG is GEEN, omdat er geen clusterbeheer is.
Voor de scripts in dit artikel identificeren de punthaken < en > waarden die u voor uw omgeving moet vervangen. De hoekhaken zelf zijn niet vereist voor de scripts.
Installeer SQL Server 2022 (16.x) op Windows Server 2022, schakel AlwaysOn-beschikbaarheidsgroepen in vanuit SQL Server Configuration Manager en stel verificatie in gemengde modus in.
Tip
Als u deze oplossing in Azure valideert, plaatst u beide servers in dezelfde beschikbaarheidsset om ervoor te zorgen dat ze worden gescheiden in het datacenter.
Beschikbaarheidsgroepen inschakelen
Zie Always On-beschikbaarheidsfunctie in- of uitschakelen van de beschikbaarheidsgroepvoor instructies.
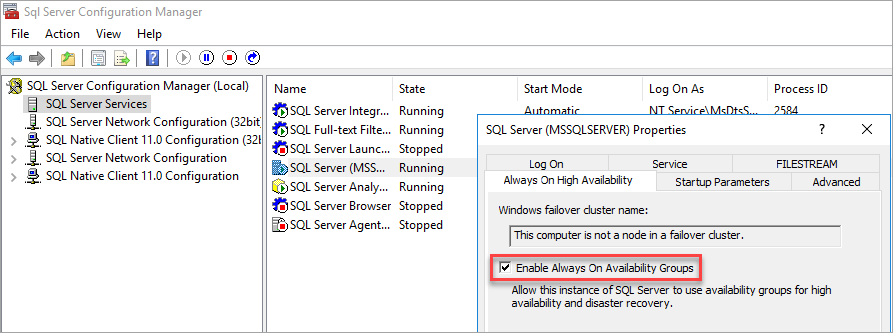
SQL Server Configuration Manager merkt op dat de computer geen knooppunt in een failovercluster is.
Nadat u beschikbaarheidsgroepen hebt ingeschakeld, start u SQL Server opnieuw op.
verificatie in gemengde modus instellen
Zie Serververificatiemodus wijzigenvoor instructies.
Installeer SQL Server 2022 (16.x) op Linux. Zie Installatierichtlijnen voor SQL Server op Linuxvoor instructies. Activeer
hadrmet mssql-conf.Als u
hadrwilt inschakelen via mssql-conf vanaf een shellprompt, voert u de volgende opdracht uit:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Nadat u
hadrhebt ingeschakeld, start u het SQL Server-exemplaar opnieuw op:sudo systemctl restart mssql-server.serviceConfigureer het
hosts-bestand op beide servers of registreer de servernamen bij DNS.Open firewallpoorten voor TCP 1433 en 5022 op zowel Windows als Linux.
Maak op de primaire replica een aanmeldings- en wachtwoord voor de database.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOVoorzichtigheid
Uw wachtwoord moet voldoen aan het standaard wachtwoordbeleid van SQL Server . Standaard moet het wachtwoord ten minste acht tekens lang zijn en tekens bevatten uit drie van de volgende vier sets: hoofdletters, kleine letters, basis-10 cijfers en symbolen. Wachtwoorden mogen maximaal 128 tekens lang zijn. Gebruik wachtwoorden die zo lang en complex mogelijk zijn.
Maak op de primaire replica een hoofdsleutel en certificaat en maak vervolgens een back-up van het certificaat met een persoonlijke sleutel.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOVoorzichtigheid
Uw wachtwoord moet voldoen aan het standaard SQL Server wachtwoordbeleid . Standaard moet het wachtwoord ten minste acht tekens lang zijn en tekens bevatten uit drie van de volgende vier sets: hoofdletters, kleine letters, basis-10 cijfers en symbolen. Wachtwoorden mogen maximaal 128 tekens lang zijn. Gebruik wachtwoorden die zo lang en complex mogelijk zijn.
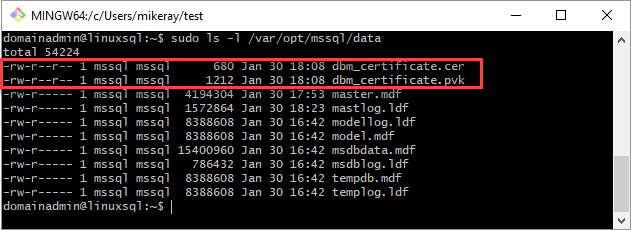
Kopieer het certificaat en de persoonlijke sleutel naar de Linux-server (secundaire replica) op
/var/opt/mssql/data. U kuntpscpgebruiken om de bestanden naar de Linux-server te kopiëren.Stel de groep en het eigendom van de persoonlijke sleutel en het certificaat in op
mssql:mssql.Met het volgende script wordt de groep en het eigendom van de bestanden ingesteld.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerIn het volgende diagram worden eigendom en groep correct ingesteld voor het certificaat en de sleutel.
Maak op de secundaire replica een databaseaanmelding en -wachtwoord en maak een hoofdsleutel.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOVoorzichtigheid
Uw wachtwoord moet voldoen aan het standaard wachtwoordbeleidvan SQL Server. Standaard moet het wachtwoord ten minste acht tekens lang zijn en tekens bevatten uit drie van de volgende vier sets: hoofdletters, kleine letters, basis-10 cijfers en symbolen. Wachtwoorden mogen maximaal 128 tekens lang zijn. Gebruik wachtwoorden die zo lang en complex mogelijk zijn.
Herstel op de secundaire replica het certificaat dat u naar
/var/opt/mssql/datahebt gekopieerd.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GOVervang in het vorige voorbeeld
<private-key-password>door hetzelfde wachtwoord dat u hebt gebruikt bij het maken van het certificaat op de primaire replica.Maak een eindpunt op de primaire replica.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOBelangrijk
De firewall moet zijn geopend voor de TCP-poort van de listener. In het voorgaande script is de poort 5022. Gebruik elke beschikbare TCP-poort.
Maak het eindpunt op de secundaire replica. Herhaal het voorgaande script op de secundaire replica om het eindpunt te maken.
Maak de beschikbaarheidsgroep aan op de primaire replica met
CLUSTER_TYPE = NONE. In het voorbeeldscript wordtSEEDING_MODE = AUTOMATICgebruikt om de AG (beschikbaarheidsgroep) te maken.Notitie
Wanneer het Windows-exemplaar van SQL Server verschillende paden gebruikt voor gegevens- en logboekbestanden, mislukt het automatisch seeden naar het Linux-exemplaar van SQL Server, omdat deze paden niet bestaan op de secundaire replica. Om het volgende script te gebruiken voor een cross-platform AG, vereist de database hetzelfde pad voor de data- en logbestanden op de Windows-server. U kunt het script ook bijwerken om
SEEDING_MODE = MANUALin te stellen en vervolgens een back-up van de database te maken en de database te herstellen metNORECOVERYom de database te seeden.Dit gedrag is van toepassing op Azure Marketplace-images.
Zie Automatisch zaaien - Schijfindelingvoor meer informatie over automatisch zaaien.
Voordat u het script uitvoert, moet u de waarden voor uw AG's bijwerken.
Vervang
<WinSQLInstance>door de servernaam van het SQL Server-exemplaar van de primaire replica.Vervang
<LinuxSQLInstance>door de servernaam van het SQL Server-exemplaar van de secundaire replica.
Om de beschikbaarheidsgroep (AG) te maken, werkt u de waarden bij en voert u het script uit op de primaire replica.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GOZie CREATE AVAILABILITY GROUPvoor meer informatie.
Voeg op de secundaire replica de beschikbaarheidsgroep toe.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOMaak een database voor de AG. In de voorbeeldstappen wordt een database met de naam
TestDBgebruikt. Als u automatische seeding gebruikt, stelt u hetzelfde pad in voor zowel de gegevens als de logboekbestanden.Voordat u het script uitvoert, moet u de waarden voor uw database bijwerken.
Vervang
TestDBdoor de naam van uw database.Vervang
<F:\Path>door het pad voor uw database en logboekbestanden. Gebruik hetzelfde pad voor de database- en logboekbestanden.
U kunt ook de standaardpaden gebruiken.
Voer het script uit om uw database te maken.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOMaak een volledige back-up van de database.
Als u geen automatische seeding gebruikt, herstelt u de database op de secundaire replicaserver (Linux). migreer een SQL Server-database van Windows naar Linux met behulp van back-up en herstel. Herstel de database
WITH NORECOVERYop de secundaire replica.Voeg de database toe aan de AG. Werk het voorbeeldscript bij. Vervang
TestDBdoor de naam van uw database. Voer op de primaire replica de T-SQL-query uit om de database toe te voegen aan de beschikbaarheidsgroep.ALTER AG [ag1] ADD DATABASE TestDB; GOControleer of de database wordt gevuld op de secundaire replica.

Failover van de primaire replica
Elke beschikbaarheidsgroep heeft slechts één primaire replica. De primaire replica staat lees- en schrijfbewerkingen toe. Als u wilt wijzigen welke replica primair is, kunt u een failover uitvoeren. In een typische beschikbaarheidsgroep automatiseert de clusterbeheerder het failoverproces. In een beschikbaarheidsgroep met clustertype NONE is het failoverproces handmatig.
Er zijn twee manieren om een failover uit te voeren voor de primaire replica in een beschikbaarheidsgroep met clustertype NONE:
- Handmatige failover zonder gegevensverlies
- Geforceerde handmatige failover met gegevensverlies
Handmatige failover zonder gegevensverlies
Gebruik deze methode wanneer de primaire replica beschikbaar is, maar u moet tijdelijk of permanent wijzigen welk exemplaar als host fungeert voor de primaire replica. Als u mogelijk gegevensverlies wilt voorkomen, moet u ervoor zorgen dat de secundaire doelreplica up-to-date is voordat u de handmatige failover uitvoert.
Handmatig een failover uitvoeren zonder gegevensverlies:
Maak de huidige primaire replica en de doelsecundaire replica
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Voer de volgende query uit om te bepalen dat actieve transacties worden doorgevoerd in de primaire replica en ten minste één synchrone secundaire replica:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;De secundaire replica wordt gesynchroniseerd wanneer
synchronization_state_descisSYNCHRONIZED.Werk
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITbij naar 1.Met het volgende script wordt
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITingesteld op 1 op een beschikbaarheidsgroep met de naamag1. Voordat u het volgende script uitvoert, vervangt uag1door de naam van uw beschikbaarheidsgroep:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Deze instelling zorgt ervoor dat elke actieve transactie wordt doorgevoerd in de primaire replica en ten minste één synchrone secundaire replica.
Notitie
Deze instelling is niet specifiek voor failover en moet worden ingesteld op basis van de vereisten van de omgeving.
Zet de primaire replica en de secundaire replica('s) die niet deelnemen aan de failover, offline om de rolwijziging voor te bereiden.
ALTER AVAILABILITY GROUP [AGRScale] OFFLINENiveau verhogen van de secundaire doelreplica naar primair.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Werk de rol van de oude primaire en andere secundaire databases bij naar
SECONDARYen voer de volgende opdracht uit op het SQL Server-exemplaar dat als host fungeert voor de oude primaire replica:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Notitie
Als u een beschikbaarheidsgroep wilt verwijderen, gebruikt u DROP AVAILABILITY GROUP. Voor een beschikbaarheidsgroep die is gemaakt met clustertype NONE of EXTERNAL, voert u de opdracht uit op alle replica's die deel uitmaken van de beschikbaarheidsgroep.
Hervat gegevensverplaatsing, voer de volgende opdracht uit voor elke database in de beschikbaarheidsgroep op het SQL Server-exemplaar dat als host fungeert voor de primaire replica:
ALTER DATABASE [db1] SET HADR RESUMEHergemaakt een listener die u hebt gemaakt voor leesschaaldoeleinden en die niet wordt beheerd door een clusterbeheerder. Als de oorspronkelijke listener naar de oude primaire verwijst, verwijdert u deze en maakt u het opnieuw zodat het naar de nieuwe primaire verwijst.
Geforceerde handmatige failover met gegevensverlies
Als de primaire replica niet beschikbaar is en niet onmiddellijk kan worden hersteld, moet u een failover naar de secundaire replica afdwingen met gegevensverlies. Echter, als de oorspronkelijke primaire replica hersteld is na een failover, zal het weer de primaire rol op zich nemen. Als u wilt voorkomen dat elke replica een andere status heeft, verwijdert u de oorspronkelijke primaire replica uit de beschikbaarheidsgroep na een geforceerde failover met gegevensverlies. Zodra de oorspronkelijke primaire versie weer online is, verwijdert u de beschikbaarheidsgroep volledig.
Als u een handmatige failover wilt afdwingen met gegevensverlies van primaire replica N1 naar secundaire replica N2, voert u de volgende stappen uit:
Start op de secundaire replica (N2) de geforceerde failover:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Verwijder op de nieuwe primaire replica (N2) de oorspronkelijke primaire replica (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Controleer of al het toepassingsverkeer naar de listener en/of de nieuwe primaire replica wijst.
Als de oorspronkelijke primaire (N1) online komt, zet u de beschikbaarheidsgroep AGRScale onmiddellijk offline op de oorspronkelijke primaire (N1).
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEAls er gegevens of niet-gesynchroniseerde wijzigingen zijn, behoudt u deze gegevens via back-ups of andere opties voor het repliceren van gegevens die aansluiten bij uw zakelijke behoeften.
Verwijder vervolgens de beschikbaarheidsgroep uit de oorspronkelijke primaire groep (N1):
DROP AVAILABILITY GROUP [AGRScale];Verwijder de beschikbaarheidsgroepdatabase op de oorspronkelijke primaire replica (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Optioneel) Desgewenst kunt u N1 weer toevoegen als een nieuwe secundaire replica aan de beschikbaarheidsgroep AGRScale.
In dit artikel worden de stappen besproken voor het maken van een platformoverschrijdende beschikbaarheidsgroep (AG) ter ondersteuning van migratie- of lees-schaalbare workloads. Deze kan worden gebruikt voor handmatig herstel na noodgevallen. Ook wordt uitgelegd hoe u een failover van de beschikbaarheidsgroep uitvoert. Een platformoverschrijdende AG maakt gebruik van clustertype NONE en biedt geen ondersteuning voor hoge beschikbaarheid.