Geavanceerdere scenario's voor telemetrie
Notitie
In dit artikel wordt Gebruikgemaakt van Het Dashboard van Aspire voor illustratie. Als u liever andere hulpprogramma's gebruikt, raadpleegt u de documentatie van het hulpprogramma dat u gebruikt voor installatie-instructies.
Automatisch functieaanroepen
Automatisch functieaanroepen is een Semantische kernelfunctie waarmee de kernel automatisch functies kan uitvoeren wanneer het model reageert met functieaanroepen en de resultaten weer aan het model geeft. Deze functie is handig voor scenario's waarbij voor een query meerdere iteraties van functie-aanroepen nodig zijn om een uiteindelijke reactie in natuurlijke taal te krijgen. Zie deze GitHub-voorbeelden voor meer informatie.
Notitie
Functie-aanroepen worden niet ondersteund door alle modellen.
Tip
U hoort de term 'tools' en 'tool calling' die soms door elkaar worden gebruikt met 'functies' en 'functie-aanroepen'.
Vereisten
- Een azure OpenAI-chatimplementatie die ondersteuning biedt voor functieaanroepen.
- Docker
- De nieuwste .Net SDK voor uw besturingssysteem.
- Een azure OpenAI-chatimplementatie die ondersteuning biedt voor functieaanroepen.
- Docker
- Python 3.10, 3.11 of 3.12 geïnstalleerd op uw computer.
Notitie
Waarneembaarheid van Semantische kernel is nog niet beschikbaar voor Java.
Instellingen
Een nieuwe consoletoepassing maken
Voer in een terminal de volgende opdracht uit om een nieuwe consoletoepassing te maken in C#:
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Navigeer naar de zojuist gemaakte projectmap nadat de opdracht is voltooid.
De vereiste pakketten installeren
Semantic Kernel
dotnet add package Microsoft.SemanticKernelOpenTelemetry Console Exporter
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Een eenvoudige toepassing maken met Semantische kernel
Open het Program.cs bestand vanuit de projectmap met uw favoriete editor. We gaan een eenvoudige toepassing maken die gebruikmaakt van Semantische kernel om een prompt naar een voltooiingsmodel voor een chat te verzenden. Vervang de bestaande inhoud door de volgende code en vul de vereiste waarden voor deploymentName, endpointen apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
In de bovenstaande code definiëren we eerst een mock-plugin voor het boeken van vergaderruimten met twee functies: FindAvailableRoomsAsync en BookRoomAsync. Vervolgens maken we een eenvoudige consoletoepassing die de invoegtoepassing registreert bij de kernel en vragen we de kernel om de functies automatisch aan te roepen wanneer dat nodig is.
Een nieuwe virtuele Python-omgeving maken
python -m venv telemetry-auto-function-calling-quickstart
Activeer de virtuele omgeving.
telemetry-auto-function-calling-quickstart\Scripts\activate
De vereiste pakketten installeren
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Een eenvoudig Python-script maken met Semantische kernel
Maak een nieuw Python-script en open het met uw favoriete editor.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
We gaan een eenvoudig Python-script maken dat gebruikmaakt van Semantic Kernel om een prompt naar een voltooiingsmodel voor een chat te verzenden. Vervang de bestaande inhoud door de volgende code en vul de vereiste waarden voor deployment_name, endpointen api_key:
import asyncio
import logging
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> list[str]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> str:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
In de bovenstaande code definiëren we eerst een mock-plugin voor het boeken van vergaderruimten met twee functies: find_available_rooms en book_room. Vervolgens maken we een eenvoudig Python-script dat de invoegtoepassing registreert bij de kernel en vragen we de kernel om de functies automatisch aan te roepen wanneer dat nodig is.
Omgevingsvariabelen
Raadpleeg dit artikel voor meer informatie over het instellen van de vereiste omgevingsvariabelen, zodat de kernel spans kan verzenden voor AI-connectors.
Notitie
Waarneembaarheid van Semantische kernel is nog niet beschikbaar voor Java.
Het Dashboard van Aspire starten
Volg de instructies hier om het dashboard te starten. Zodra het dashboard wordt uitgevoerd, opent u een browser en gaat u naar toegang tot http://localhost:18888 het dashboard.
Uitvoeren
Voer de consoletoepassing uit met de volgende opdracht:
dotnet run
Voer het Python-script uit met de volgende opdracht:
python telemetry_auto_function_calling_quickstart.py
Notitie
Waarneembaarheid van Semantische kernel is nog niet beschikbaar voor Java.
Als het goed is, wordt ongeveer de volgende uitvoer weergegeven:
Room 101 has been successfully booked for you today.
Telemetriegegevens inspecteren
Nadat u de toepassing hebt uitgevoerd, gaat u naar het dashboard om de telemetriegegevens te controleren.
Zoek de tracering voor de toepassing op het tabblad Traceringen . U moet vijf spans in de tracering hebben:
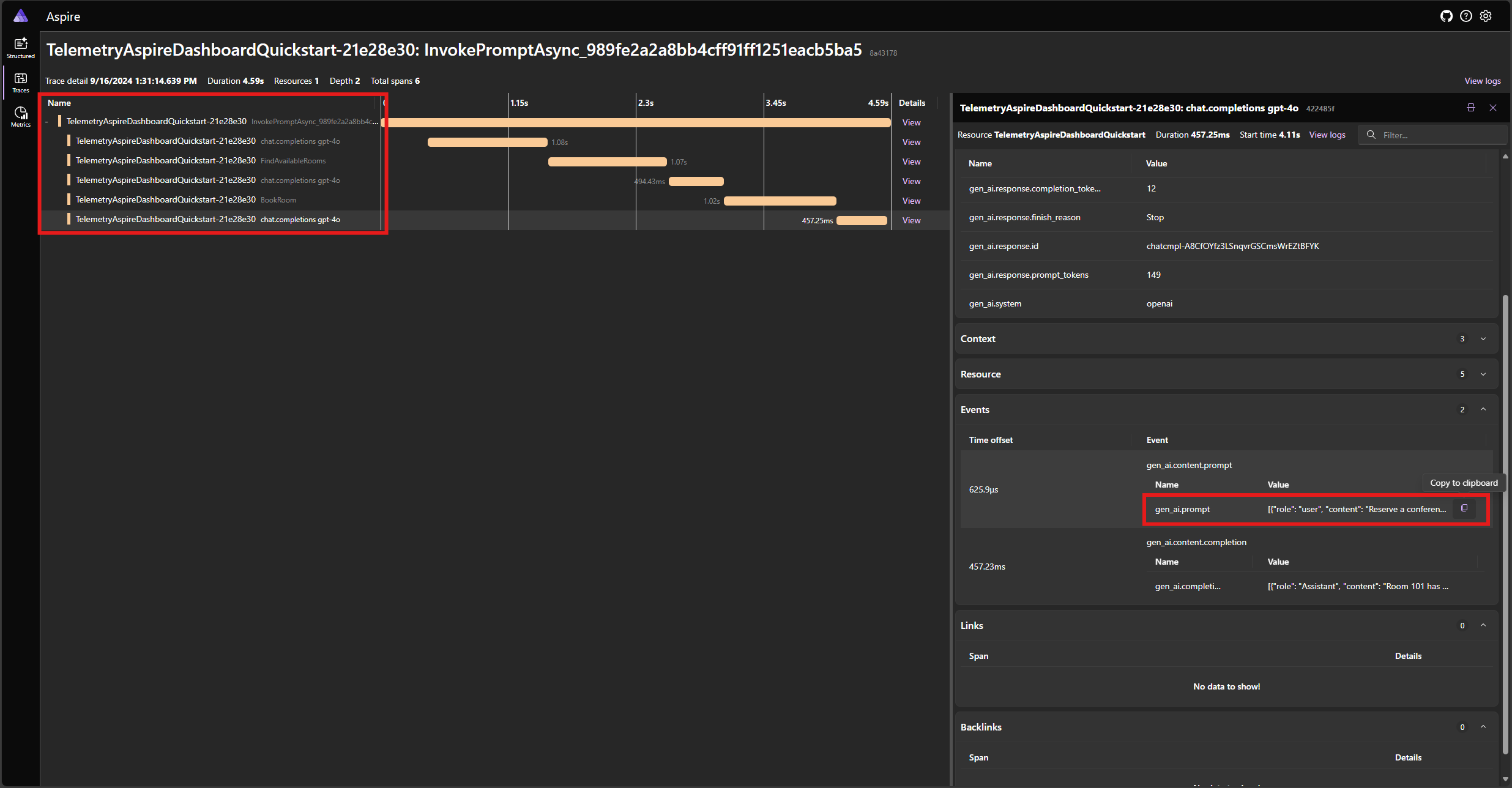
Deze 5 spanten vertegenwoordigen de interne bewerkingen van de kernel met automatische functieaanroepen ingeschakeld. Eerst wordt het model aangeroepen, dat een functie-aanroep aanvraagt. Vervolgens voert de kernel de functie FindAvailableRoomsAsync automatisch uit en retourneert het resultaat aan het model. Het model vraagt vervolgens een andere functie-aanroep uit om een reservering te maken. De kernel voert de functie BookRoomAsync automatisch uit en retourneert het resultaat naar het model. Ten slotte retourneert het model een reactie van natuurlijke taal op de gebruiker.
En als u op de laatste periode klikt en de prompt in de gen_ai.content.prompt gebeurtenis zoekt, ziet u iets vergelijkbaars met het volgende:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Dit is de chatgeschiedenis die wordt opgebouwd als het model en de kernel met elkaar communiceren. Dit wordt in de laatste iteratie naar het model verzonden om een reactie in natuurlijke taal te krijgen.
Zoek de tracering voor de toepassing op het tabblad Traceringen . U moet vijf spanen in de tracering gegroepeerd onder het AutoFunctionInvocationLoop bereik:
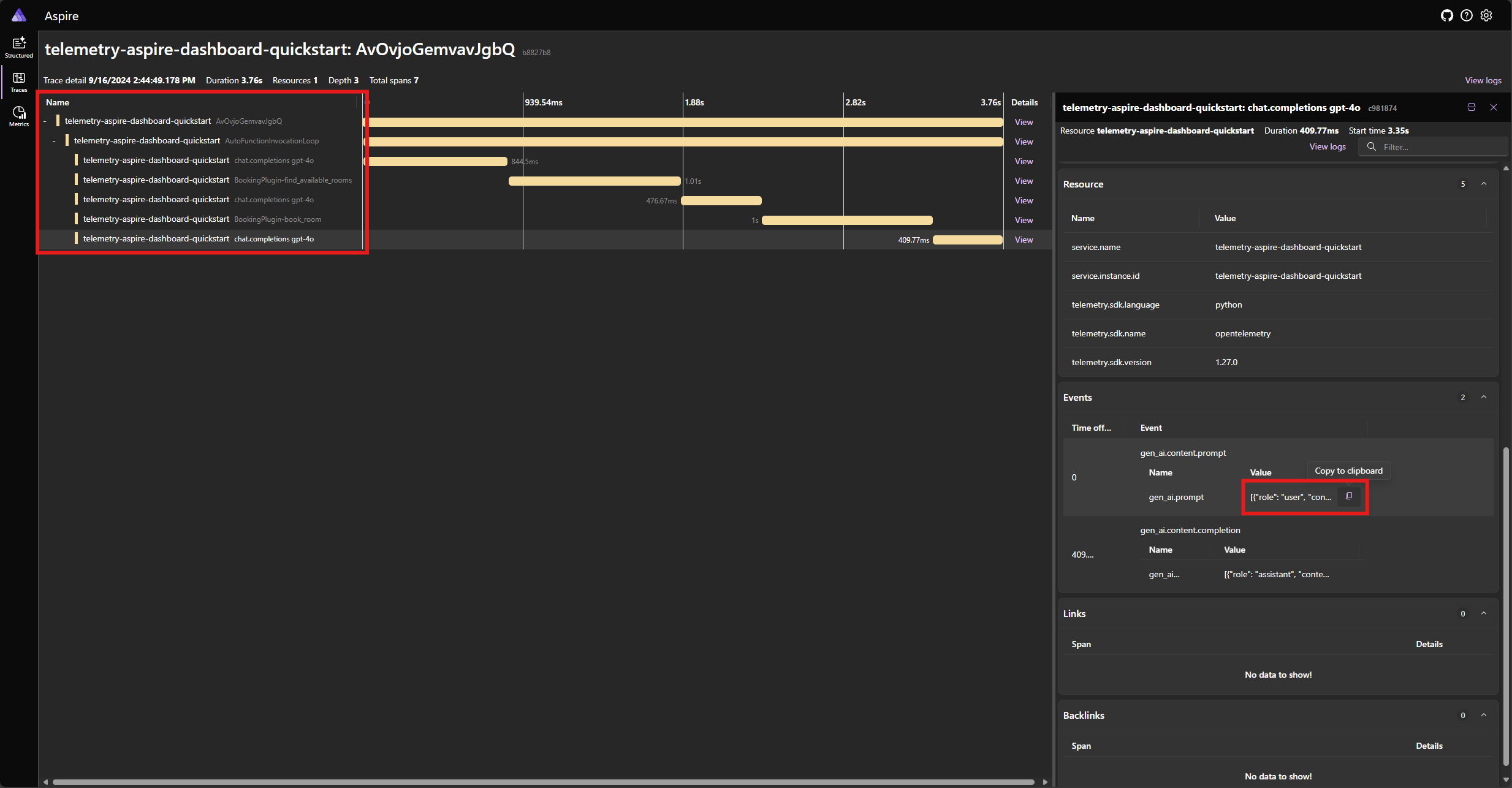
Deze 5 spanten vertegenwoordigen de interne bewerkingen van de kernel met automatische functieaanroepen ingeschakeld. Eerst wordt het model aangeroepen, dat een functie-aanroep aanvraagt. Vervolgens voert de kernel de functie find_available_rooms automatisch uit en retourneert het resultaat aan het model. Het model vraagt vervolgens een andere functie-aanroep uit om een reservering te maken. De kernel voert de functie book_room automatisch uit en retourneert het resultaat naar het model. Ten slotte retourneert het model een reactie van natuurlijke taal op de gebruiker.
En als u op de laatste periode klikt en de prompt in de gen_ai.content.prompt gebeurtenis zoekt, ziet u iets vergelijkbaars met het volgende:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Dit is de chatgeschiedenis die wordt opgebouwd als het model en de kernel met elkaar communiceren. Dit wordt in de laatste iteratie naar het model verzonden om een reactie in natuurlijke taal te krijgen.
Notitie
Waarneembaarheid van Semantische kernel is nog niet beschikbaar voor Java.
Foutafhandeling
Als er een fout optreedt tijdens de uitvoering van een functie, wordt de fout automatisch door de kernel onderscheppen en wordt er een foutbericht geretourneerd naar het model. Het model kan dit foutbericht vervolgens gebruiken om de gebruiker een natuurlijke taal te geven.
Wijzig de BookRoomAsync functie in de C#-code om een fout te simuleren:
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
Voer de toepassing opnieuw uit en bekijk de tracering in het dashboard. U ziet nu het bereik dat de kernelfunctieaanroep vertegenwoordigt met een fout:
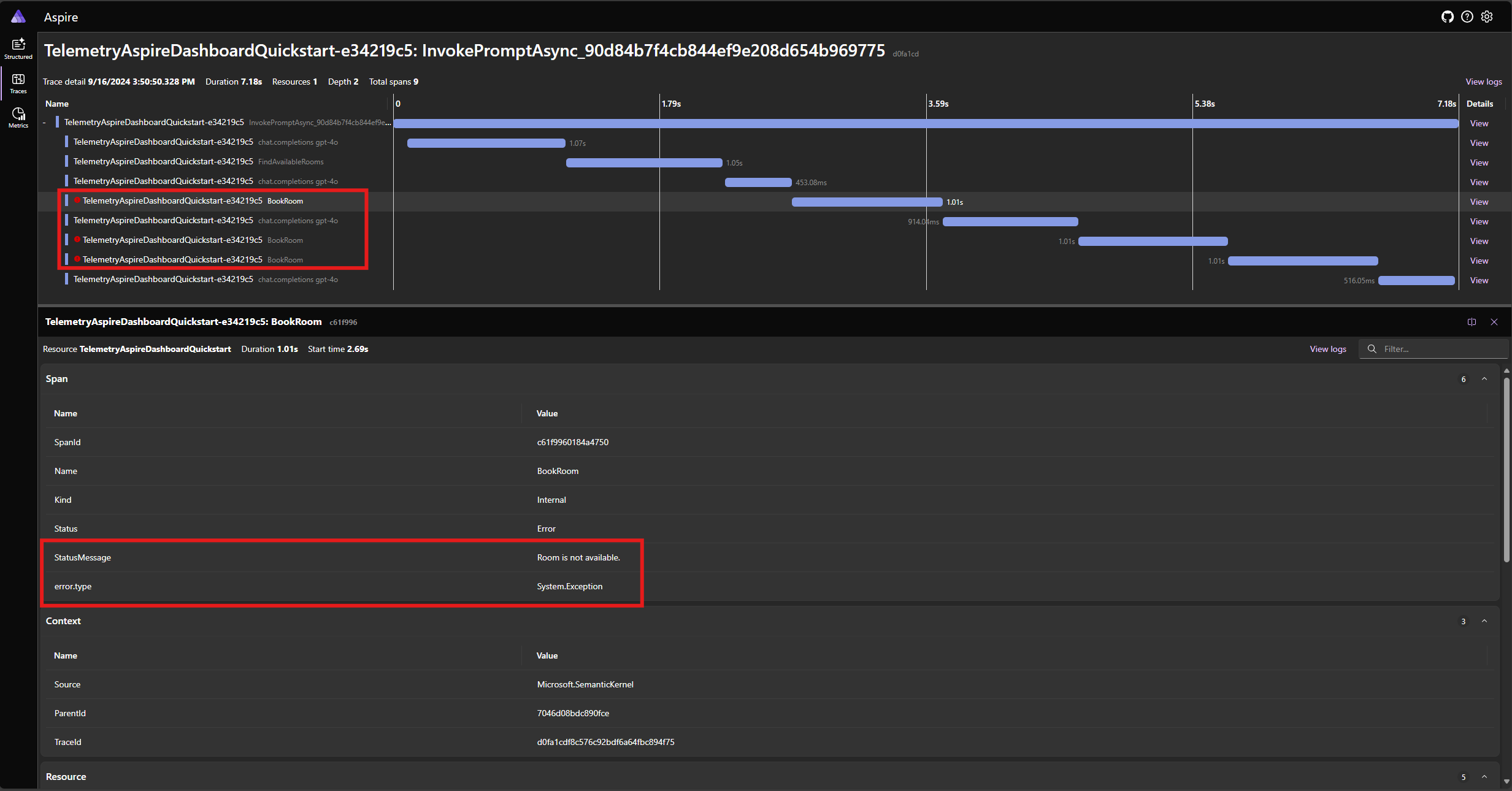
Notitie
Het is zeer waarschijnlijk dat de modelreacties op de fout variëren telkens wanneer u de toepassing uitvoert, omdat het model stochastisch is. Mogelijk ziet u dat het model alle drie de ruimten tegelijk reserveert of dat u een van de eerste keer reserveert en vervolgens de andere twee de tweede keer reserveert, enzovoort.
Wijzig de book_room functie in de Python-code om een fout te simuleren:
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> str:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
Voer de toepassing opnieuw uit en bekijk de tracering in het dashboard. U ziet nu het bereik dat de kernelfunctieaanroep vertegenwoordigt met een fout en de stack-trace:
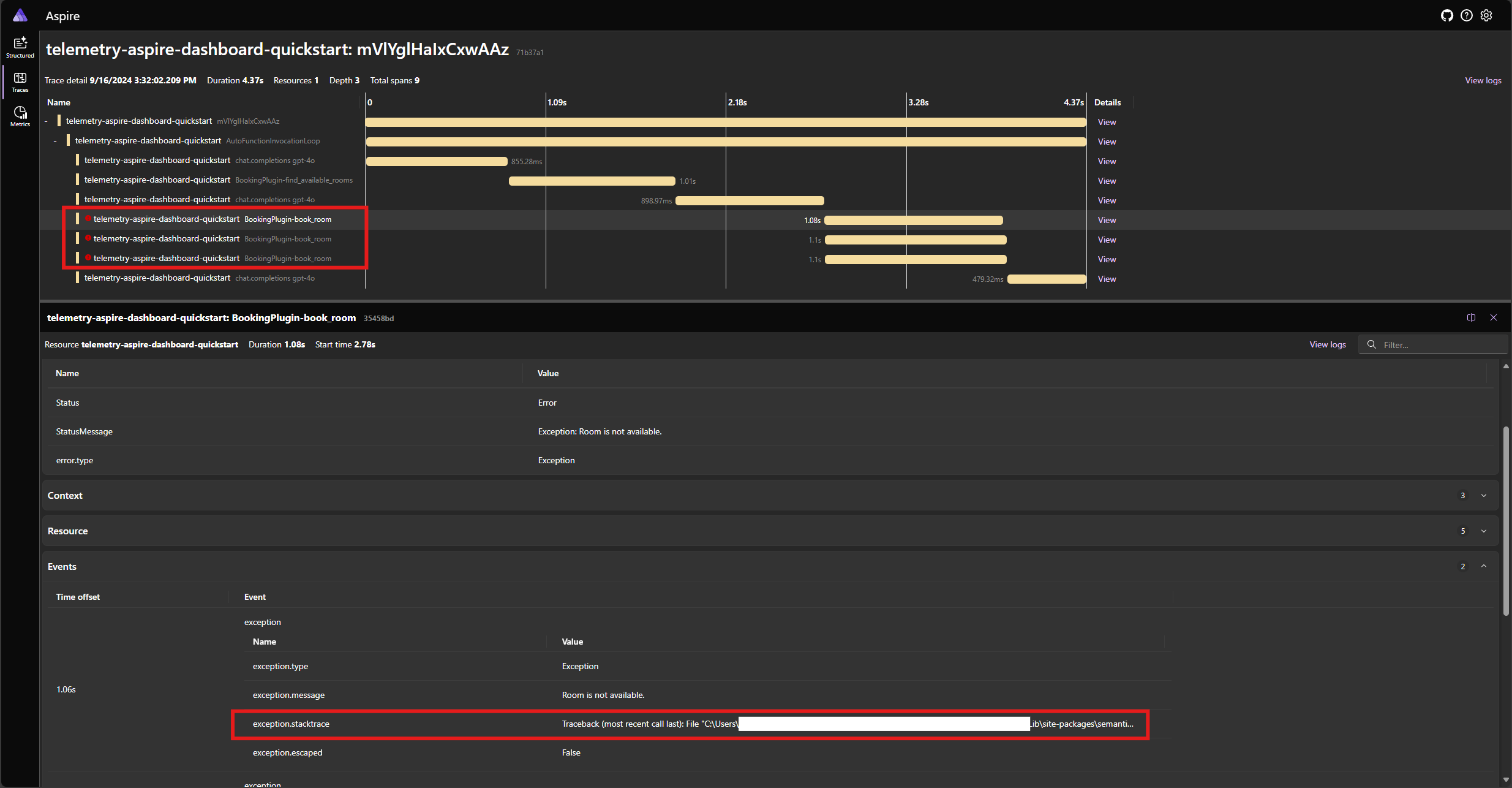
Notitie
Het is zeer waarschijnlijk dat de modelreacties op de fout variëren telkens wanneer u de toepassing uitvoert, omdat het model stochastisch is. Mogelijk ziet u dat het model alle drie de ruimten tegelijk reserveert of dat u een van de eerste keer reserveert en vervolgens de andere twee de tweede keer reserveert, enzovoort.
Notitie
Waarneembaarheid van Semantische kernel is nog niet beschikbaar voor Java.
Volgende stappen en verder lezen
In productie kunnen uw services een groot aantal aanvragen krijgen. Semantische kernel genereert een grote hoeveelheid telemetriegegevens. sommige hiervan zijn mogelijk niet nuttig voor uw use-case en zullen onnodige kosten voor het opslaan van de gegevens veroorzaken. U kunt de samplingfunctie gebruiken om de hoeveelheid verzamelde telemetriegegevens te verminderen.
Waarneembaarheid in Semantische kernel wordt voortdurend verbeterd. U vindt de nieuwste updates en nieuwe functies in de GitHub-opslagplaats.