Meerdere GPU's en machines
1. Inleiding
CNTK ondersteunt momenteel vier parallelle SGD-algoritmen:
Vereisten
Als u parallelle training wilt uitvoeren, moet u ervoor zorgen dat er een implementatie van de Message Passing Interface (MPI) is geïnstalleerd:
Installeer in Windows versie 7 (7.0.12437.6) van Microsoft MPI (MS-MPI), een Microsoft-implementatie van de Message Passing Interface-standaard, vanaf deze downloadpagina, gemarkeerd als 'versie 7' in de paginatitel. Klik op de knop Downloaden en selecteer vervolgens de runtime (
MSMpiSetup.exe).Installeer Op Linux OpenMPI versie 1.10.x. Volg de instructies hier om het zelf te bouwen.
2. Parallelle training configureren in CNTK in Python
Om gegevensparalle SGD in Python te kunnen gebruiken, moet de gebruiker een gedistribueerde cursist maken en doorgeven aan de trainer:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Voor een door de gebruiker gedefinieerde trainingslus (in plaats van training_session), moeten gebruikers doorgeven num_data_partitions en partition_index naar MinibatchSource.next_minibatch() de methode gaan, zodat verschillende MPI-knooppunten gegevens uit verschillende gegevenspartities lezen (nadat distributed_after de voorbeelden zijn gelezen).
Houd er rekening mee dat Communicator.finalize() deze alleen moeten worden aangeroepen voor het geval de gedistribueerde training is voltooid. Als een gedistribueerde werkrol mislukt, mag deze methode niet worden aangeroepen.
Zie het ConvNet-voorbeeld voor een volledig functioneel voorbeeld.
3. Parallelle training configureren in CNTK in BrainScript
Als u parallelle training in CNTK BrainScript wilt inschakelen, moet u eerst de volgende schakeloptie inschakelen in het configuratiebestand of op de opdrachtregel:
parallelTrain = true
Ten tweede moet het SGD blok in het configuratiebestand een subblok ParallelTrain met de volgende argumenten bevatten:
parallelizationMethod: (verplicht) legitieme waarden zijnDataParallelSGD,BlockMomentumSGDenModelAveragingSGD.Hiermee geeft u op welk parallel algoritme moet worden gebruikt.
distributedMBReading: (optioneel) accepteert Booleaanse waarde:trueoffalse; standaardwaarde isfalseHet wordt aanbevolen om gedistribueerde minibatch in te schakelen om de I/O-kosten in elke werknemer te minimaliseren. Als u CNTK Text Format Reader, Image Reader of Composite Data Reader gebruikt, moet gedistribueerdeMBReading zijn ingesteld op waar.
parallelizationStartEpoch: (optioneel) accepteert geheel getalwaarde; standaard is 1.Hiermee wordt aangegeven vanaf welke periode, parallelle trainingsalgoritmen worden gebruikt; voordat alle werknemers dezelfde training uitvoeren, maar slechts één werknemer het model mag opslaan. Deze optie kan handig zijn als parallelle training een 'warmstartfase' vereist.
syncPerfStats: (optioneel) accepteert geheel getalwaarde; standaard is 0.Hiermee geeft u op hoe vaak de prestatiestatistieken worden afgedrukt. Deze statistieken omvatten de tijd die is besteed aan communicatie en/of berekening in een synchronisatieperiode, wat handig kan zijn om het knelpunt van parallelle trainingsalgoritmen te begrijpen.
0 betekent dat er geen statistieken worden afgedrukt. Andere waarden geven aan hoe vaak de statistieken worden afgedrukt. Betekent bijvoorbeeld
syncPerfStats=5dat statistieken na elke 5 synchronisaties worden afgedrukt.Een subblok met details van elk algoritme voor parallelle training. De naam van het subblok moet gelijk zijn aan
parallelizationMethod. (verplichte)
Python biedt meer flexibiliteit en gebruik worden hieronder weergegeven voor verschillende parallelle methoden.
4. Parallelle training uitvoeren met CNTK
Parallellisatie in CNTK wordt geïmplementeerd met MPI.
4.1 Parallelle training uitvoeren met BrainScript
Gezien een van de bovenstaande BrainScript-configuraties voor parallelle training, kunnen de volgende opdrachten worden gebruikt om een parallelle MPI-taak te starten:
Parallelle training op dezelfde computer met Linux:
mpiexec --npernode $num_workers $cntk configFile=$configParallelle training op dezelfde computer met Windows:
mpiexec -n %num_workers% %cntk% configFile=%config%Parallelle training op meerdere rekenknooppunten met Linux:
Stap 1: Een hostbestand maken $hostfile met behulp van uw favoriete editor
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Waarbij name_of_node(n) gewoon een DNS-naam of IP-adres van het werkknooppunt is.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
Parallelle training op meerdere rekenknooppunten met Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
waarbij $cntk moet worden verwezen naar het pad van het uitvoerbare CNTK-bestand ($x is de manier om omgevingsvariabelen te vervangen door de Linux-shell, het equivalent van %x% in de Windows-shell).
4.2 Parallelle training uitvoeren met Python
Hier vindt u voorbeelden voor gedistribueerde training voor CNTK v2 met Python:
Gezien een CNTK v2 Python-script training.py kunnen de volgende opdrachten worden gebruikt om een parallelle MPI-taak te starten:
Parallelle training op dezelfde computer met Linux:
mpiexec --npernode $num_workers python training.pyParallelle training op dezelfde computer met Windows:
mpiexec -n %num_workers% python training.pyParallelle training op meerdere rekenknooppunten met Linux:
Stap 1: Een hostbestand maken $hostfile met behulp van uw favoriete editor
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
Waarbij name_of_node(n) gewoon een DNS-naam of IP-adres van het werkknooppunt is.
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
Parallelle training op meerdere rekenknooppunten met Windows:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel Training met 1-bits SGD
CNTK implementeert de 1-bits SGD-techniek [1]. Met deze techniek kan elke minibatch over K werkrollen worden verdeeld. De resulterende gedeeltelijke kleurovergangen worden vervolgens na elke minibatch uitgewisseld en geaggregeerd. "1 bit" verwijst naar een techniek die is ontwikkeld bij Microsoft om de hoeveelheid gegevens te verminderen die voor elke kleurovergangswaarde wordt uitgewisseld tot één bit.
5.1 Het 1-bits SGD-algoritme
Voor het rechtstreeks uitwisselen van gedeeltelijke kleurovergangen na elke minibatch is een te hoge communicatiebandbreedte vereist. Om dit aan te pakken, kwantiseert de 1-bits SGD elke kleurovergangswaarde agressief... tot één bit (!) per waarde. Praktisch betekent dit dat grote kleurovergangswaarden worden afgekapt, terwijl kleine waarden kunstmatig worden opgepompt. Verbazingwekkend, dit beschadigt convergentie niet als, en alleen als, een truc wordt gebruikt.
De truc is dat voor elke minibatch het algoritme de gekwantiseerde kleurovergangen (die tussen werkrollen worden uitgewisseld) vergelijkt met de oorspronkelijke kleurovergangswaarden (die moeten worden uitgewisseld). Het verschil tussen de twee (de kwantisatiefout) wordt berekend en onthouden als het residu. Deze residuen worden vervolgens toegevoegd aan de volgende minibatch.
Als gevolg hiervan wordt, ondanks de agressieve kwantisatie, elke kleurovergangswaarde uiteindelijk uitgewisseld met volledige nauwkeurigheid; gewoon bij een vertraging. Experimenten tonen aan dat, zolang dit model wordt gecombineerd met een warme start (een seed-model dat is getraind op een kleine subset van de trainingsgegevens zonder parallellisatie), deze techniek heeft aangetoond dat dit leidt tot geen of zeer klein verlies van nauwkeurigheid, terwijl een versnelling niet te ver van lineair is toegestaan (de beperkingsfactor is dat GPU's inefficiënt worden bij het berekenen van te kleine subbatches).
Voor maximale efficiëntie moet de techniek worden gecombineerd met automatische minibatch schaling, waarbij de trainer nu en dan probeert de minibatch groter te maken. Evalueren op een kleine subset van het komende tijdvak van gegevens, zal de trainer de grootste minibatchgrootte selecteren die geen afbreuk doet aan convergentie. Hier is het handig dat CNTK de leersnelheid en momentum hyperparameters op een agnostische manier op een minibatch-grootte specificeert.
5.2 Met behulp van 1-bits SGD in BrainScript
De 1-bits SGD zelf heeft geen andere parameter dan het inschakelen en waarna deze moet beginnen. Daarnaast moet automatische minibatch-schaling zijn ingeschakeld. Deze worden geconfigureerd door de volgende parameters toe te voegen aan het SGD-blok:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
Houd er rekening mee dat Data-Parallel SGD ook kan worden gebruikt zonder 1-bits kwantisatie. In typische scenario's, met name scenario's waarin elke modelparameter slechts eenmaal wordt toegepast, zoals voor een feed-forward DNN, is dit niet efficiënt vanwege hoge communicatiebandbreedtebehoeften.
In sectie 2.2.3 hieronder ziet u de resultaten van een 1-bits SGD voor een spraaktaak, vergeleken met de Block-Momentum SGD-methode die hierna wordt beschreven. Beide methoden hebben geen of bijna geen verlies van nauwkeurigheid bij bijna lineaire snelheid.
5.3 Met behulp van 1-bits SGD in Python
Om gegevensparalle SGD in Python te gebruiken, optioneel met 1-bits SGD, moet de gebruiker een gedistribueerde cursist maken en doorgeven aan de trainer:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Als u num_quantization_bits wijzigt in 32 tijdens het maken van distributed_learner, wordt er gebruikgemaakt van niet-gekwantificeerde Data-Parallel SGD. In dit geval is er geen warme start nodig.
6 Block-Momentum SGD
Block-Momentum SGD is de implementatie van de 'blockwise model update and filtering', of BMUF, algoritme, short Block Momentum [2].
6.1 Het Block-Momentum SGD-algoritme
In de volgende afbeelding ziet u een overzicht van de procedure in het algoritme Block-Momentum.

6.2 Configureren van Block-Momentum SGD in BrainScript
Als u Block-Momentum SGD wilt gebruiken, moet u een subblok hebben met BlockMomentumSGDSGD de volgende opties:
syncPeriod. Dit is vergelijkbaar met desyncPeriodinModelAveragingSGD, waarmee wordt aangegeven hoe vaak een modelsynchronisatie wordt uitgevoerd. De standaardwaarde voorBlockMomentumSGDis 120.000.resetSGDMomentum. Dit betekent dat na elk synchronisatiepunt de vloeiende kleurovergang die in de lokale SGD wordt gebruikt, wordt ingesteld op 0. De standaardwaarde van deze variabele is waar.useNesterovMomentum. Dit betekent dat de Nesterov-stijl momentum-update wordt toegepast op het blokniveau. Zie [2] voor meer informatie. De standaardwaarde van deze variabele is waar.
De blokdynamiek en blokleersnelheid worden meestal automatisch ingesteld op basis van het aantal gebruikte werknemers, d.w.v.
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
Onze ervaring geeft aan dat deze instellingen vaak vergelijkbare convergentie opleveren als het standaard-SGD-algoritme tot 64 GPU's, wat het grootste experiment is dat we hebben uitgevoerd. Het is ook mogelijk om handmatig de volgende parameters op te geven met behulp van de volgende opties:
blockMomentumAsTimeConstanthiermee geeft u de tijdconstante van het filter met lage doorvoer in modelupdate op blokniveau. Deze wordt berekend als:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRategeeft de leersnelheid van het blok op.
Hieronder volgt een voorbeeld van Block-Momentum SGD-configuratiesectie:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 Met behulp van Block-Momentum SGD in BrainScript
1. Leerparameters opnieuw afstemmen
Om een vergelijkbare doorvoer per werkrol te bereiken, is het noodzakelijk om het aantal steekproeven in een minibatch evenredig te verhogen met het aantal werknemers. Dit kan worden bereikt door het aanpassen
minibatchSizeofnbruttsineachrecurrentiter, afhankelijk van of randomisatie in framemodus wordt gebruikt.Het is niet nodig om de leersnelheid aan te passen (in tegenstelling tot Model-Averaging SGD, zie hieronder).
Het wordt aanbevolen om Block-Momentum SGD te gebruiken met een warm gestart model. Voor onze spraakherkenningstaken wordt een redelijke convergentie bereikt bij het starten van seed-modellen die zijn getraind op 24 uur (8,6 miljoen monsters) tot 120 uur (43,2 miljoen steekproeven) met behulp van standaard-SGD.
2. ASR-experimenten
We hebben de Block-Momentum SGD en de 1-bits SGD-algoritmen (Data-Parallel) gebruikt om DNN's en LSTM's te trainen op een spraakherkenningstaak van 2600 uur en de nauwkeurigheid van woordherkenning vergeleken versus snelheidsfactoren. In de volgende tabellen en afbeeldingen ziet u de resultaten (*).
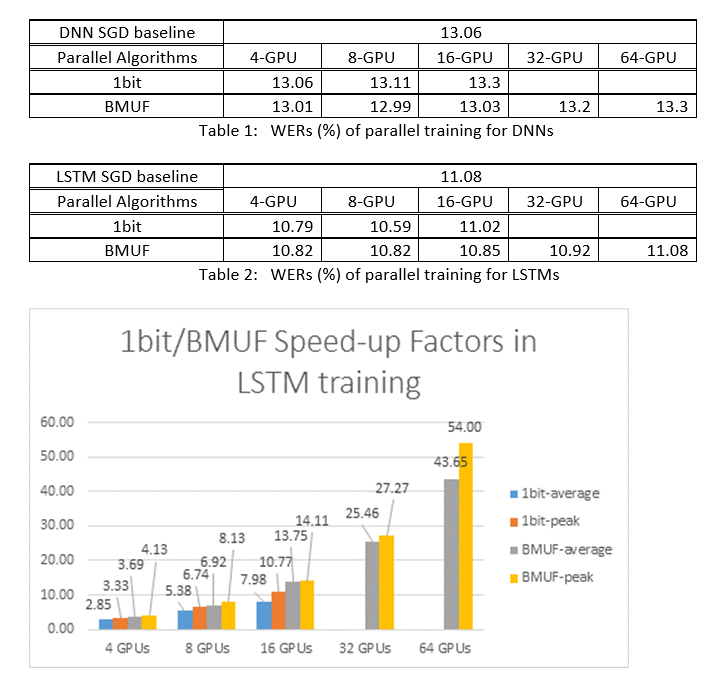
(*): Pieksnelheidsfactor: voor 1-bits SGD, gemeten door de maximale snelheidsfactor (vergeleken met de SGD-basislijn) die in één minibatch is behaald; voor blokdynamiek, gemeten door de maximale snelheid die in één blok is bereikt; Gemiddelde versnellingsfactor: de verstreken tijd in de SGD-basislijn gedeeld door de waargenomen verstreken tijd. Deze twee metrische gegevens worden geïntroduceerd vanwege de latentie in I/O, kan de gemiddelde snelheidsfactormeting aanzienlijk beïnvloeden, met name wanneer de synchronisatie wordt uitgevoerd op minibatchniveau. Tegelijkertijd is de maximale snelheidsfactor relatief robuust.
3. Kanttekeningen
Het wordt aanbevolen om in te stellen
resetSGDMomentumop true, anders leidt dit vaak tot afwijking van het trainingscriterium. Het opnieuw instellen van de SGD-momentum op 0 nadat elke modelsynchronisatie de bijdrage van de laatste minibatches afneemt. Daarom wordt het aanbevolen om geen grote SGD-momentum te gebruiken. Voor eensyncPeriodvan 120.000 zien we bijvoorbeeld een aanzienlijk nauwkeurigheidsverlies als het momentum dat wordt gebruikt voor SGD 0,99 is. Het verminderen van de SGD-momentum tot 0,9, 0,5 of zelfs het uitschakelen ervan biedt vergelijkbare nauwkeurigheiden, omdat het kan worden bereikt door het standaard-SGD-algoritme.Block-Momentum SGD vertraagt en distribueert modelupdates van één blok over volgende blokken. Daarom is het noodzakelijk om ervoor te zorgen dat modelsynchronisaties vaak genoeg worden uitgevoerd in de training. Een snelle controle is om te gebruiken
blockMomentumAsTimeConstant. Het wordt aanbevolen om het aantal unieke trainingsvoorbeelden teNvoldoen aan de volgende vergelijking:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
De benadering komt voort uit de volgende feiten: (1) Block Momentum wordt vaak ingesteld als (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers.
6.4 Met Block-Momentum in Python
Om Block-Momentum in Python in te schakelen, vergelijkbaar met de 1-bits SGD, moet de gebruiker een gedistribueerde blok-momentum-cursist maken en doorgeven aan de trainer:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
Zie het ConvNet-voorbeeld voor een volledig functioneel voorbeeld.
7 Model-Averaging SGD
Model-Gemiddeldeing SGD is een implementatie van het modelmiddelingsalgoritmen die in [3,4] worden beschreven zonder gebruik te maken van natuurlijke kleurovergang. Het idee hier is om elke werkrol een subset van gegevens te laten verwerken, maar het gemiddelde van de modelparameters van elke werkrol na een opgegeven periode.
Model-Averaging SGD convergeert over het algemeen langzamer en tot een slechtere optimale, vergeleken met 1-bits SGD en Block-Momentum SGD, dus het wordt niet meer aanbevolen.
Als u Model-Averaging SGD wilt gebruiken, moet u een subblok hebben met ModelAveragingSGDSGD de volgende opties:
syncPeriodgeeft het aantal steekproeven op dat elke werkrol moet verwerken voordat een modelmiddeling wordt uitgevoerd. De standaardwaarde is 40.000.
7.1 Met behulp van Model-Averaging SGD in BrainScript
Om Model-Averaging SGD maximaal effectief en efficiënt te maken, moeten gebruikers enkele hyperparameters afstemmen:
minibatchSizeofnbruttsineachrecurrentiter. Stel datnwerknemers deelnemen aan de Model-Averaging SGD-configuratie. De huidige gedistribueerde leesimplementatie wordt in elke werkrol geladen1/n. Om ervoor te zorgen dat elke werkrol dezelfde doorvoer produceert als de standaard-SGD, is het noodzakelijk om de minibatchgrootten-vouw te vergroten. Voor modellen die worden getraind met randomisatie in framemodus, kan dit worden bereikt door tijden te vergrotenminibatchSizen; voor modellen worden getraind met behulp van randomisatie in de volgordemodus, zoals RNN's, moeten sommige lezers in plaats daarvan toenemennbruttsineachrecurrentitermetn.learningRatesPerSample. Onze ervaring geeft aan dat om vergelijkbare convergentie als de standaard-SGD te krijgen, het noodzakelijk is om delearningRatesPerSampleby-timesnte verhogen. Er is een uitleg te vinden in [2]. Aangezien het leerpercentage wordt verhoogd, is er extra zorg nodig om ervoor te zorgen dat de training niet afwijkt- en dit is in feite de belangrijkste kanttekening van Model-Averaging SGD. U kunt deAutoAdjustinstellingen gebruiken om het vorige beste model opnieuw te laden als er een toename van het trainingscriterium wordt waargenomen.warme start. Er wordt vastgesteld dat Model-Averaging SGD meestal beter convergeert als het wordt gestart vanuit een seed-model dat wordt getraind door het standaard-SGD-algoritme (zonder parallellisatie). Voor onze spraakherkenningstaken wordt een redelijke convergentie bereikt bij het starten van seed-modellen die zijn getraind op 24 uur (8,6 miljoen monsters) tot 120 uur (43,2 miljoen steekproeven) met behulp van standaard-SGD.
Hier volgt een voorbeeld van ModelAveragingSGD een configuratiesectie:
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 Met Model-Averaging SGD in Python
Hier wordt aan gewerkt.
8 Data-Parallel Training met parameterserver
Parameterserver is een veelgebruikt framework in gedistribueerde machine learning [5][6][7]. Het belangrijkste voordeel dat het oplevert, is de asynchrone parallelle training met veel werknemers. De parameterserver wordt geïntroduceerd als een gedistribueerd modelarchief. In plaats van direct gebruik te maken van AllReduce-primitieven voor het synchroniseren van parameterupdates tussen werkrollen, biedt het parameterserverframework gebruikers de interfaces zoals 'Toevoegen' en 'Ophalen', zodat lokale werknemers globale parameters van de parameterserver kunnen bijwerken en ophalen. Op deze manier hoeven lokale werknemers niet op elkaar te wachten tijdens het trainingsproces, wat veel tijd bespaart, met name wanneer het aantal werknemers groot is.
Bovendien is parameterservers een gedistribueerd framework waarmee modelparameters worden opgeslagen, kunnen werknemers alleen de parameters ophalen die ze nodig hebben tijdens het minibatchtrainingsproces, dit biedt zeer goede flexibiliteit bij het ontwerpen van gedistribueerde trainingsmethode en verbetert ook de efficiëntie bij het uitvoeren van training met sparse-modelupdates. In deze release richten we ons eerst op de asynchrone parallelle training, later geven we meer informatie over het gebruik van parameterserverframework voor efficiënte modeltraining met sparse-updates.
8.1 Met behulp van Data-Parallel ASGD
- Als u parameterservers wilt gebruiken voor de Asynchrone SGD (verkort. als ASGD), moet u CNTK bouwen met Multiverso ondersteund. Multiverso is een algemeen parameterserverframework voor gedistribueerde machine learning-taken die zijn ontwikkeld door het Microsoft Research Asia-team.
Clone Code: kloon de code onder de hoofdmap van CNTK met behulp van:
git submodule update --init Source/Multiverso
Linux: bouw mee--asgd=yesin het configuratieproces.Windows: voeg deze toeCNTK_ENABLE_ASGDaan uw systeemomgeving en stel de waarde in optrue
- warme start. In sommige gevallen is het beter om de asynchrone modeltraining te laten starten vanaf een seed-model (dat wordt getraind met een standaard-SGD-algoritme). In zekere zin brengt Asynchrone SGD meer ruis voor de training vanwege de vertraagde updates van asynchroonheid tussen werknemers. Sommige modellen zijn zeer gevoelig voor dergelijke ruis aan het begin, wat kan leiden tot afwijken van modeltraining. Onder dergelijke omstandigheden is een warme start nodig.
8.2 Configureren van Data-Parallel ASGD in BrainScript
Als u Data-Parallel ASGD in CNTK wilt gebruiken, moet u een subblok DataParallelASGD in het SGD-blok hebben met de volgende opties
-
syncPeriodPerWorkers. Hiermee wordt het aantal voorbeelden opgegeven dat elke werkrol moet verwerken voordat deze communiceert met de parameterservers. De standaardwaarde is 256. Het wordt aanbevolen als grootte van minibatch. Het is duidelijk dat regelmatige synchronisatie leidt tot aanzienlijke hoge communicatiekosten. In onze test is het niet nodig om in de meeste gevallen de waarde in te stellen op 1.
-
usePipeline. Hiermee wordt aangegeven of de pijplijn van het ophalen van modellen en lokale berekeningen wordt ingeschakeld. Als u de pijplijn inschakelt, wordt de totale doorvoer van training aanzienlijk verhoogd, omdat sommige of alle communicatiekosten hierdoor worden verborgen. Soms kan het echter de convergeersnelheid vertragen, omdat er meer vertraging wordt geïntroduceerd door pijplijn toe te voegen. Over het algemeen wordt de kloktijd opgeslagen in de meeste gevallen met pijplijn.
-
AdjustLearningRateAtBeginning. Volgens onlangs gepubliceerd document [5], is training ASGD minder stabiel en vereist het gebruik van veel kleinere leersnelheid om af en toe explosies van het trainingsverlies te voorkomen, daarom wordt het leerproces minder efficiënt. We hebben echter vastgesteld dat het gebruik van een lager leerpercentage niet vereist is voor alle taken. En voor deze taken die gevoelig zijn in het begin, beginnen we de training met een klein leerpercentage en breiden we het geleidelijk uit in het beginstadium van het trainingsproces totdat het de eerste leersnelheid bereikt die wordt gebruikt in de normale SGD. Op deze manier komt de uiteindelijke nauwkeurigheid overeen met SGD terwijl deze overeenkomt met de snelheid van ASGD. Daarom bieden we deze optie voor ASGD-gebruikers om deze truc te gebruiken. Het is een subblok in DataParallelASGD met twee parameters: adjustCoefficient en adjustNBMiniBatch. De logica is dat het leerpercentage begint bij adjustCoefficient van de initiële SGD-leersnelheid en toeneemt door adjustCoefficient van de initiële SGD-leersnelheid elke adjustNBMiniBatch minibatch .
Hier volgt een voorbeeld van DataParallelASGD een configuratiesectie:
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 Configureren van Data-Parallel ASGD in Python
Hier wordt aan gewerkt.
8.4 Experimenten
In de volgende afbeelding ziet u de experimenten voor het testen van ASGD met CIFAR-10-gegevensset. Het model dat in dit experiment wordt gebruikt, is een ResNet met 20 lagen. Het asynchrone algoritme vermindert de kosten voor het wachten op alle werkknooppunten. ASGD is in dit geval duidelijk sneller dan de synchrone algoritmen, zoals MA en SSGD. *In de experimenten synchroniseren alle parallelle modi de parameters elke iteratie (mini-batch-update). En voor SSGD hebben we 32-bits parameterupdates gebruikt. Asynchroon algoritme profiteert aanzienlijk van de trainingsdoorvoer die wordt gemeten door de verwerkingssnelheid van het voorbeeld, met name wanneer het werkknooppuntnummer tot 16 gaat.
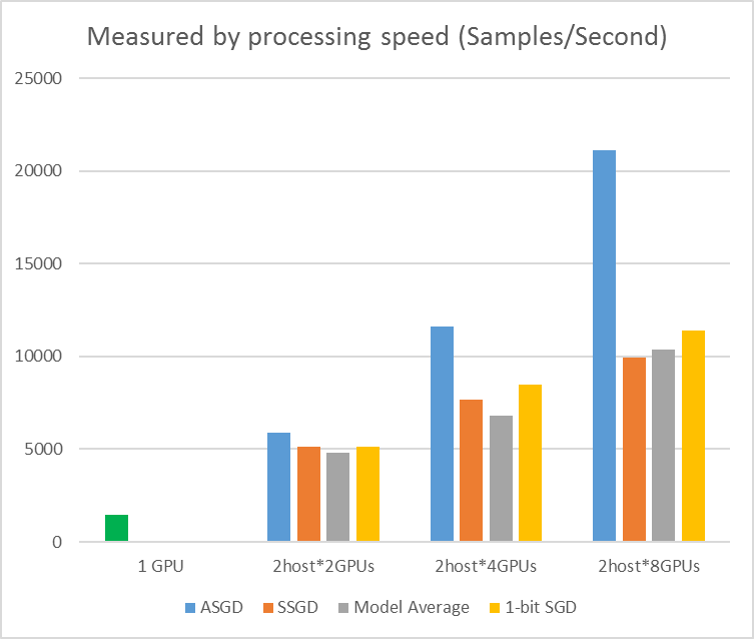 Afbeelding 2.4 de snelheid voor verschillende trainingsmethoden
Afbeelding 2.4 de snelheid voor verschillende trainingsmethoden
Referenties
[1] F. Seide, Opgegeven Fu, Jasha Droppo, Gang Li en Dong Yu, "1-bits stochastische gradiëntafname en de toepassing ervan op gegevensparallel gedistribueerde training van spraak-DN's", in Proceedings of Interspeech, 2014.
[2] K. Chen en Q. Huo, "Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering", in Proceedings of ICASSP, 2016.
[3] M. Zinkppa, M. Weimer, L. Li en A. J. Smola, "Parallelized stochastic gradient descent", in Proceedings of Advances in NIPS, 2010, pp. 2595–2603.
[4] D. Povey, X. Linkerkant en S. Khudanpur, "Parallelle training van DNN's met natuurlijke kleurovergang en parameter gemiddelde," in Proceedings of the International Conference on Learning Representations, 2014.
[5] Chen J, Monga R, Bengio S, et al. Revisiting Distributed Synchronous SGD. ICLR, 2016.
[6] Dean Jeffrey, Greg Corrado, Rajat Monga, Kai Chen, Matthewieu Devin, Mark Mao, Andrew Senior et al. Grootschalige gedistribueerde deep networks. Op voorhand in neurale informatieverwerkingssystemen, pp. 1223-1231. 2012.
[7] Li Mu, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, David G. Andersen en Alexander Smola. 'Parameterserver voor gedistribueerde machine learning'. In Big Learning NIPS Workshop, vol. 6, p. 2. 2013.