Databases, deployment topologies, and backup
Azure DevOps Server 2022 | Azure DevOps Server 2020 | Azure DevOps Server 2019 | TFS 2018
You can help protect your deployment from data loss by creating a regular schedule of backups for the databases that Azure DevOps Server depends on. To restore your Azure DevOps Server deployment completely, first back up all Azure DevOps Server databases.
If your deployment includes SQL Server Reporting Services, you must also back up the databases that Azure DevOps uses within those components. To prevent synchronization errors or data mismatch errors, you must synchronize all backups to the same time stamp. The easiest way to ensure successful synchronization is by using marked transactions. By routinely marking related transactions in every database, you establish a series of common recovery points in the databases. For step-by-step guidance for backing up a single-server deployment that uses reporting, see Create a backup schedule and plan.
Backing up databases
Protect your Azure DevOps deployment against data loss by creating database backups. The following table and accompanying illustrations show which databases to back up, and provide examples of how those databases might be physically distributed in a deployment.
| Database Type | Product | Required component? |
|---|---|---|
| Configuration database | Azure DevOps Server | Yes |
| Warehouse database | Azure DevOps Server | Yes |
| Project collection databases | Azure DevOps Server | Yes |
| Reporting databases | SQL Server Reporting Services | No |
| Analysis databases | SQL Server Analysis Services | No |
Deployment topologies
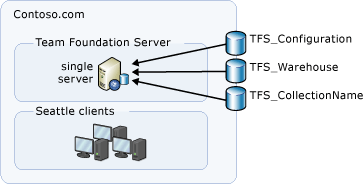
Based on your deployment configuration, all the databases that require backing up might be on the same physical server, as in this example topology.
Note
This example does not include Reporting Services or SharePoint Products, so you do not have to back up any databases that are associated with reporting, analysis, or SharePoint Products.
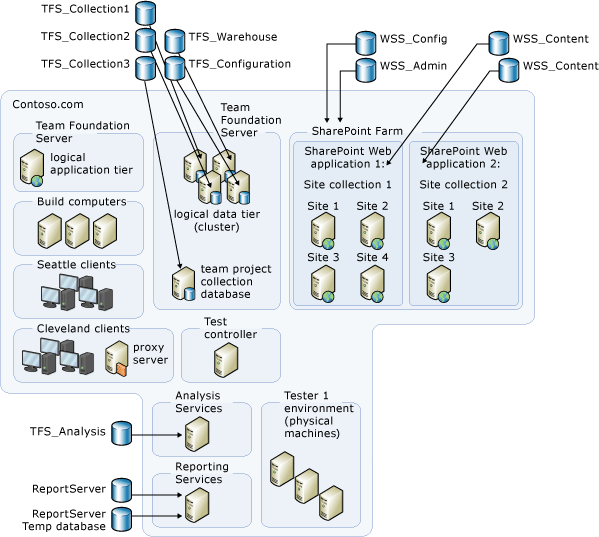
As an alternative, the databases might be distributed across many servers and server farms. In this example topology, you must back up the following databases, which are scaled across six servers or server farms:
the configuration database
the warehouse database
the project collection databases that are located on the SQL Server cluster
the collection database that is located on the stand-alone server that is running SQL Server
the databases that are located on the server that is running Reporting Services
the database that is located on the server that is running Analysis Services
the SharePoint Products administrative databases and the site collection databases for both SharePoint web applications
If your SharePoint databases are scaled across multiple servers, you cannot use the Scheduled Backups feature to back them up. You must manually configure backups for those databases, and ensure that those backups are synchronized with the Azure DevOps Server database backups. For more information, see Manually back up Azure DevOps Server.
In both of these examples, you do not have to back up any of the clients that connect to the server. However, you might need to manually clear the caches for Azure DevOps Server on the client computers before they can reconnect to the restored deployment.
Databases to back up
The following list provides additional details regarding what you must back up, depending on your deployment resources.
Important
All the databases in the following list are SQL Server databases. Although you can use SQL Server Management Studio to back up individual databases at any time, you should avoid using such individual backups when possible. You might experience unexpected results if you restore from individual backups because the databases that Azure DevOps uses are all related. If you back up only one database, the data in that database may not be synchronized with the data in the other databases.
- Databases for Azure DevOps Server - The logical data tier for Azure DevOps Server includes several SQL Server databases, including the configuration database, the warehouse database, and a database for each project collection in the deployment. These databases might all be on the same server, distributed across several instances in the same SQL Server deployment, or distributed across multiple servers. Regardless of their physical distribution, you must back up all of the databases to the same time stamp to help ensure against data loss. You can perform database backups manually or automatically by using maintenance plans that run at specific times or intervals.
Important
The list of Azure DevOps databases isn't static. A new database is created every time you create a collection. When you create a collection, make sure that you add the database for that collection to your maintenance plan.
- Databases for Reporting Services and Analysis Services - If your deployment uses SQL Server Reporting Services or SQL Server Analysis Services to generate reports for Azure DevOps Server, you must back up the reporting and analysis databases. However, you must still regenerate certain databases after restoration, such as the warehouse.
- Encryption key for the report server - The report server has an encryption key that you must back up. This key safeguards sensitive information that is stored in the database for the report server. You can manually back up this key by using either the Reporting Services Configuration tool or a command-line tool.
Advanced preparation for backups
When you deploy Azure DevOps, you should keep a record of the accounts that you create and any computer names, passwords, and setup options that you specify. You should also keep a copy of all recovery materials, documents, and database and transaction log backups at a secure location. To safeguard against a disaster, such as a fire or an earthquake, you should keep duplicates of your server backups in a different location from the location of the servers. This strategy will help protect you against the loss of critical data. As a best practice, you should keep three copies of the backup media, and you should keep at least one copy offsite in a controlled environment.
Important
Perform a trial data restoration periodically to verify that your files are correctly backed up. A trial restoration can reveal hardware problems that don't appear with a software-only verification.
When you back up and restore a database, you must back up the data onto media with a network address (for example, tapes and disks that have been shared as network drives). Your backup plan should include provisions for managing media, such as the following tactics:
- A tracking and management plan for storing and recycling backup sets.
- A schedule for overwriting backup media.
- In a multi-server environment, a decision to use either centralized or distributed backups.
- A way of tracking the useful life of media.
- A procedure to minimize the effects of the loss of a backup set or backup media (for example, a tape).
- A decision to store backup sets onsite or offsite and an analysis of how this decision might affect recovery time.
Because Azure DevOps data is stored in SQL Server databases, you don't have to back up the computers on which clients of Azure DevOps are installed. If a media failure or disaster that involved those computers were to occur, you can re-install the client software and reconnect to the server. By re-installing the client software, your users will have a cleaner and more reliable alternative to restoring a client computer from a backup.
You can back up a server by using the Scheduled Backups features available, or by manually creating maintenance plans in SQL Server to back up the databases that relate to your Azure DevOps deployment. The Azure DevOps databases work in relationship with one other, and if you create a manual plan, you should back them up and restore them at the same time. For more information about strategies for backing up databases, see Back up and restore SQL Server Databases.
Types of backups
Understanding the types of backups available helps you determine the best options for backing up your deployment. For example, if you are working with a large deployment and want to protect against data loss while efficiently using limited storage resources, you can configure differential backups as well as full data backups. If you are using SQL Server Always On, you can take backups of your secondary database. You can also try using backup compression or splitting backups across multiple files. Here are brief descriptions of your backup options:
Full data backups (databases)
A full database backup is necessary for the recoverability of your deployment. A full backup includes part of the transaction log so that you can recover the full backup. Full backups are self-contained in that they represent the entire database as it existed when you backed it up. For more information, see Full database backups.
Differential data backups (databases)
A differential database backup records only the data that has changed since the last full database backup, which is called the differential base. Differential database backups are smaller and faster than full database backups. This option saves backup time at the cost of increased complexity. For large databases, differential backups can occur at shorter intervals than database backups, which reduces the work-loss exposure. For more information, see Differential database backups.
You should also back up your transaction logs regularly. These backups are necessary for recovering data when you use the full database backup model. If you back up transaction logs, you can recover the database to the point of failure or to an earlier point in time.
Transaction log backups
The transaction log is a serial record of all modifications that have occurred in a database in addition to the transaction that performed each modification. The transaction log records the start of each transaction, the changes to the data, and, if necessary, enough information to undo the modifications made during that transaction. The log grows continuously as logged operations occur in the database.
By backing up transaction logs, you can recover the database to an earlier point in time. For example, you can restore the database to a point before unwanted data was entered or a failure occurred. Besides database backups, transaction log backups must be part of your recovery strategy. For more information, see Transaction Log Backups (SQL Server).
Transaction log backups generally use fewer resources than full backups. Therefore, you can create transaction log backups more frequently than full backups, which reduces your risk of losing data. However, sometimes a transaction log backup is larger than a full backup. For example, a database with a high transaction rate causes the transaction log to grow quickly. In this situation, you should create transaction log backups more frequently. For more information, see Troubleshoot a full transaction log (SQL Server Error 9002).
You can perform the following types of transaction log backups:
- A pure log backup contains only transaction log records for an interval, without any bulk changes.
- A bulk log backup contains log and data pages that were changed by bulk operations. Point-in-time recovery is not allowed.
- A tail-log backup is taken from a possibly damaged database to capture the log records that have not yet been backed up. A tail-log backup is taken after a failure to prevent work loss and can contain either pure log or bulk log data.
Because synchronization of data is critical for successful restoration of Azure DevOps Server, you should use marked transactions as part of your backup strategy if you are configuring backups manually. For more information, see Create a backup schedule and plan and Manually back up Azure DevOps Server.
Application-tier service backups
The only backup needed for the logical application tier is for the encryption key for Reporting Services. If you use the Scheduled Backups feature to back up your deployment, this key will be backed up for you as part of the plan. You might assume that you must back up web sites used as project portals.
Although you can back up an application tier more easily than a data tier, there are still several steps to restore an application tier. You must install another application tier for Azure DevOps Server, redirect project collections to use the new application tier, and redirect the portal sites for projects.
Default database names
If you do not customize the names of your databases, you can use the following table to identify the databases used in your deployment of Azure DevOps Server. As mentioned previously, not all deployments have all these databases. For example, if you did not configure Azure DevOps Server with Reporting Services, you will not have the ReportServer or ReportServerTempDB databases. Similarly, you will not have the database for System Center Virtual Machine Manager (SCVMM), VirtualManagerDB, unless you configure Azure DevOps Server to support Lab Management. In addition, the databases that Azure DevOps Server uses might be distributed across more than one instance of SQL Server or across more than one server.
Note
By default, the prefix TFS_ is added to the names of any databases that are created automatically when you install Azure DevOps Server or while it is operating.
| Database | Description |
|---|---|
| TFS_Configuration | The configuration database for Azure DevOps Server contains the catalog, server names, and configuration data for the deployment. The name of this database might include additional characters between TFS_ and Configuration, such as the user name of the person who installed Azure DevOps Server. For example, the name of the database might be TFS_UserNameConfiguration |
| TFS_Warehouse | The warehouse database contains the data for building the warehouse that Reporting Services uses. The name of this database might include additional characters between TFS_ and Warehouse, such as the user name of the person who installed Azure DevOps Server. For example, the name of the database might be TFS_UserNameWarehouse. |
| TFS_CollectionName | The database for a project collection contains all data for the projects in that collection. This data includes source code, build configurations, and lab management configurations. The number of collection databases will equal the number of collections. For example, if you have three collections in your deployment, you must back up these three collection databases. The name of each database might include additional characters between TFS_ and CollectionName, such as the user name of the person who created the collection. For example, the name of a collection database might be TFS_UserNameCollectionName. |
| TFS_Analysis | The database for SQL Server Analysis Services contains the data sources and cubes for your deployment of Azure DevOps Server. The name of this database might include additional characters between TFS_ and Analysis, such as the user name of the person who installed Analysis Services. For example, the name of the database might be TFS_UserNameAnalysis. Note: You can back up this database, but you must rebuild the warehouse from the restored TFS_Warehouse database. |
| ReportServer | The database for Reporting Services contains the reports and report settings for your deployment of Azure DevOps Server. Note: If Reporting Services is installed on a separate server from Azure DevOps Server, this database might not be present on the data-tier server for Azure DevOps Server. In that case, you must configure, back up, and restore it separately from Azure DevOps Server. You should synchronize the maintenance of the databases to avoid synchronization errors. |
| ReportServerTempDB | The temporary database for Reporting Services temporarily stores information when you run specific reports. Note: If Reporting Services is installed on a separate server than Azure DevOps Server, this database might not be present on the data-tier server for Azure DevOps Server. In this case, you must configure, back up, and restore it separately from Azure DevOps Server. However, you should synchronize the maintenance of the databases to avoid synchronization errors. |
| VirtualManagerDB | The administration database for SCVMM contains the information that you view in the SCVMM Administrator Console, such as virtual machines, virtual machine hosts, virtual machine library servers, and their properties. Note: If SCVMM is installed on a separate server than Azure DevOps Server, this database might not be present on the data-tier server for Azure DevOps Server. In that case, you must configure, back up, and restore it separately from Azure DevOps Server. However, you should use marked transactions and synchronize the maintenance of the databases to avoid synchronization errors. |