TripPin deel 10 - Eenvoudige query folding
Notitie
Deze inhoud verwijst momenteel naar inhoud uit een verouderde implementatie voor logboeken in Visual Studio. De inhoud wordt in de nabije toekomst bijgewerkt om de nieuwe Power Query SDK in Visual Studio Code te behandelen.
Deze meerdelige zelfstudie bevat informatie over het maken van een nieuwe gegevensbronextensie voor Power Query. De zelfstudie is bedoeld om opeenvolgend te worden uitgevoerd. Elke les bouwt voort op de connector die in de vorige lessen is gemaakt, en voegt incrementeel nieuwe mogelijkheden toe aan uw connector.
In deze les gaat u het volgende doen:
- Meer informatie over de basisbeginselen van het vouwen van query's
- Meer informatie over de functie Table.View
- OData query folding handlers repliceren voor:
$top$skip$count$select$orderby
Een van de krachtige functies van de M-taal is de mogelijkheid om transformatiewerk naar een of meer onderliggende gegevensbronnen te pushen. Deze mogelijkheid wordt Query Folding genoemd (andere hulpprogramma's/technologieën verwijzen ook naar vergelijkbare functies als Predicate Pushdown of QueryDelegering).
Wanneer u een aangepaste connector maakt die gebruikmaakt van een M-functie met ingebouwde mogelijkheden voor het vouwen van query's, zoals OData.Feed of Odbc.DataSource, neemt uw connector deze mogelijkheid automatisch gratis over.
In deze zelfstudie wordt het ingebouwde gedrag voor het vouwen van query's voor OData gerepliceerd door functie-handlers te implementeren voor de functie Table.View . In dit deel van de zelfstudie worden enkele van de eenvoudigere handlers geïmplementeerd (dat wil weten degenen die geen expressieparsering en statustracering vereisen).
Als u meer wilt weten over de querymogelijkheden die een OData-service kan bieden, gaat u naar URL-conventies voor OData v4.
Notitie
Zoals eerder vermeld, biedt de functie OData.Feed automatisch mogelijkheden voor het vouwen van query's. Omdat de TripPin-serie de OData-service behandelt als een reguliere REST API, met web.contents in plaats van OData.Feed, moet u de handlers voor het vouwen van query's zelf implementeren. Voor praktijkgebruik raden we u aan om waar mogelijk OData.Feed te gebruiken.
Ga naar Overzicht van de query-evaluatie en het vouwen van query's in Power Query voor meer informatie over het vouwen van query's.
Table.View gebruiken
Met de functie Table.View kan een aangepaste connector standaardtransformatiehandlers voor uw gegevensbron overschrijven. Een implementatie van Table.View biedt een functie voor een of meer van de ondersteunde handlers. Als een handler niet is geïmplementeerd of een error tijdens de evaluatie retourneert, valt de M-engine terug op de standaardhandler.
Wanneer een aangepaste connector een functie gebruikt die geen ondersteuning biedt voor impliciete query folding, zoals Web.Contents, worden standaardtransformatiehandlers altijd lokaal uitgevoerd. Als de REST API waarmee u verbinding maakt, ondersteuning biedt voor queryparameters als onderdeel van de query, kunt u met Table.View optimalisaties toevoegen waarmee transformatiewerk naar de service kan worden gepusht.
De functie Table.View heeft de volgende handtekening:
Table.View(table as nullable table, handlers as record) as table
Uw implementatie verpakt uw hoofdgegevensbronfunctie. Er zijn twee vereiste handlers voor Table.View:
GetType— retourneert het verwachtetable typeresultaat van de queryGetRows— retourneert het werkelijketableresultaat van uw gegevensbronfunctie
De eenvoudigste implementatie zou vergelijkbaar zijn met het volgende voorbeeld:
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
Werk de functie bij om aan TripPinNavTable te roepen TripPin.SuperSimpleView in plaats GetEntityvan:
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
Als u de eenheidstests opnieuw uitvoert, ziet u dat het gedrag van uw functie niet wordt gewijzigd. In dit geval wordt uw Table.View-implementatie gewoon doorgegeven door de aanroep naar GetEntity. Omdat u nog geen transformatiehandlers hebt geïmplementeerd, blijft de oorspronkelijke url parameter ongewijzigd.
Eerste implementatie van Table.View
De bovenstaande implementatie van Table.View is eenvoudig, maar niet erg nuttig. De volgende implementatie wordt gebruikt als basislijn. Er wordt geen vouwende functionaliteit geïmplementeerd, maar u hebt de scaffolding die u nodig hebt.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Als u de aanroep naar Table.View bekijkt, ziet u een extra wrapper-functie rond de handlers record.Diagnostics.WrapHandlers Deze helperfunctie is te vinden in de module Diagnostische gegevens (die is geïntroduceerd in de les diagnostische gegevens toevoegen) en biedt u een handige manier om eventuele fouten die door afzonderlijke handlers zijn gegenereerd, automatisch te traceren.
De GetType functies GetRows worden bijgewerkt om gebruik te maken van twee nieuwe helperfuncties,CalculateSchema en CalculateUrl. Op dit moment zijn de implementaties van deze functies vrij eenvoudig: u ziet dat ze delen bevatten van wat eerder door de GetEntity functie is uitgevoerd.
Ten slotte ziet u dat u een interne functie (View) definieert die een state parameter accepteert.
Wanneer u meer handlers implementeert, roepen ze de interne functie recursief aan, waarbij ze de interne View functie bijwerken en doorgeven state wanneer ze gaan.
Werk de TripPinNavTable functie opnieuw bij, vervang de aanroep door TripPin.SuperSimpleView een aanroep naar de nieuwe TripPin.View functie en voer de eenheidstests opnieuw uit. U ziet nog geen nieuwe functionaliteit, maar u hebt nu een solide basislijn voor testen.
Query folding implementeren
Omdat de M-engine automatisch terugvalt op lokale verwerking wanneer een query niet kan worden gevouwen, moet u enkele extra stappen uitvoeren om te controleren of uw Table.View-handlers correct werken.
De handmatige manier om het vouwgedrag te valideren, is door de URL-aanvragen te bekijken die uw eenheidstests doen met behulp van een hulpprogramma zoals Fiddler. U kunt ook de diagnostische logboekregistratie die u hebt toegevoegd voor TripPin.Feed het verzenden van de volledige URL die wordt uitgevoerd, bevatten de OData-queryreeksparameters die uw handlers toevoegen.
Een geautomatiseerde manier om query folding te valideren, is het afdwingen dat de uitvoering van de eenheidstest mislukt als een query niet volledig wordt gevouwen. U kunt dit doen door de projecteigenschappen te openen en Error on Folding Failure in True in te stellen. Als deze instelling is ingeschakeld, resulteert elke query waarvoor lokale verwerking is vereist de volgende fout:
De expressie kan niet worden gevouwen naar de bron. Probeer een eenvoudigere expressie.
U kunt dit testen door een nieuw Fact bestand toe te voegen aan uw eenheidstestbestand dat een of meer tabeltransformaties bevat.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Notitie
De instelling Fout bij vouwen is een 'alles of niets'-benadering. Als u query's wilt testen die niet zijn ontworpen om te worden gevouwen als onderdeel van uw eenheidstests, moet u voorwaardelijke logica toevoegen om tests dienovereenkomstig in of uit te schakelen.
In de resterende secties van deze zelfstudie wordt elk een nieuwe Table.View-handler toegevoegd. U neemt een TDD-benadering (Test Driven Development), waarbij u eerst mislukte eenheidstests toevoegt en vervolgens de M-code implementeert om deze op te lossen.
In de volgende handlersecties worden de functionaliteit beschreven die wordt geleverd door de handler, de equivalente OData-querysyntaxis, de eenheidstests en de implementatie. Voor elke handler-implementatie zijn twee wijzigingen vereist met behulp van de eerder beschreven scaffoldercode:
- De handler toevoegen aan Table.View waarmee de
staterecord wordt bijgewerkt. CalculateUrlWijzigen om de waarden op te halen uit destateurl en/of queryreeksparameters toe te voegen.
Table.FirstN verwerken met OnTake
De OnTake handler ontvangt een count parameter, het maximum aantal rijen waaruit GetRowsmoet worden opgehaald.
In OData-termen kunt u dit vertalen naar de $top queryparameter.
U gebruikt de volgende eenheidstests:
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
Deze tests gebruiken beide Table.FirstN om te filteren op de resultatenset op het eerste X-aantal rijen. Als u deze tests uitvoert met Error on Folding Failure ingesteld op False (de standaardinstelling), moeten de tests slagen, maar als u Fiddler uitvoert (of de traceerlogboeken controleert), ziet u dat de aanvraag die u verzendt geen OData-queryparameters bevat.
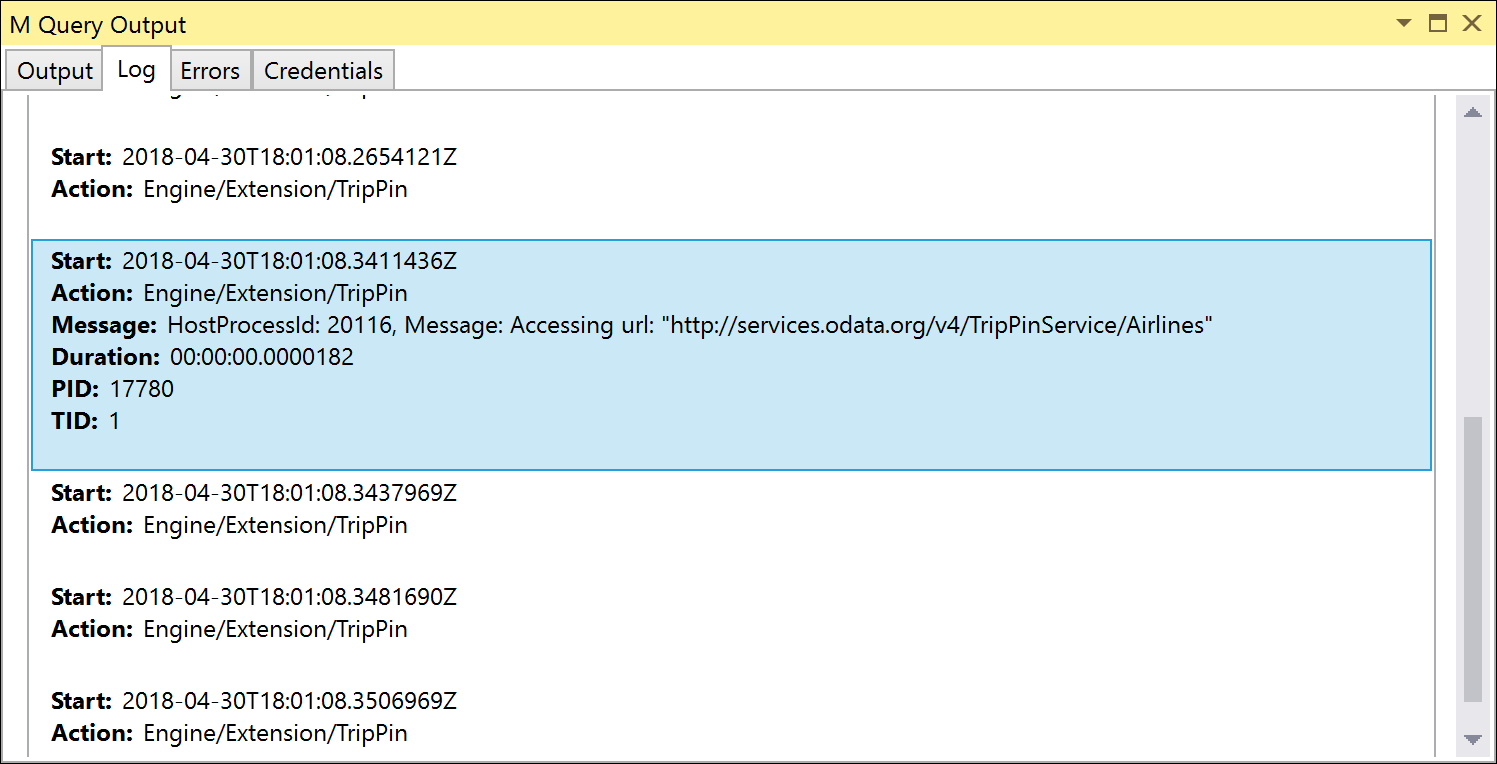
Als u Error on Folding Failure to instelt, mislukken de tests met de Please try a simpler expression. Truefout. U kunt deze fout oplossen door uw eerste Table.View-handler OnTakevoor te definiëren.
De OnTake handler ziet eruit als de volgende code:
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
De CalculateUrl functie wordt bijgewerkt om de waarde uit de Top state record te extraheren en de juiste parameter in de querytekenreeks in te stellen.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
Als u de eenheidstests opnieuw uitvoert, ziet u dat de URL die u nu opent de $top parameter bevat. Vanwege URL-codering wordt $top weergegeven als %24top, maar de OData-service is slim genoeg om deze automatisch te converteren.
Table.Skip verwerken met OnSkip
De OnSkip handler is veel als OnTake. Er wordt een count parameter ontvangen. Dit is het aantal rijen dat moet worden overgeslagen uit de resultatenset. Deze handler vertaalt zich mooi naar de OData -$skip queryparameter.
Eenheidstests:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
Implementatie:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
Overeenkomende updates voor CalculateUrl:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
Meer informatie: Table.Skip
Table.SelectColumns verwerken met OnSelectColumns
De OnSelectColumns handler wordt aangeroepen wanneer de gebruiker kolommen uit de resultatenset selecteert of verwijdert. De handler ontvangt een list waarde text die een of meer kolommen vertegenwoordigt die moeten worden geselecteerd.
In OData-termen wordt deze bewerking toegewezen aan de $select queryoptie.
Het voordeel van het vouwen van kolomselectie wordt duidelijk wanneer u te maken hebt met tabellen met veel kolommen. De $select operator verwijdert niet-geselecteerde kolommen uit de resultatenset, wat resulteert in efficiëntere query's.
Eenheidstests:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
De eerste twee tests selecteren verschillende aantallen kolommen met Table.SelectColumns en bevatten een Table.FirstN-aanroep om de testcase te vereenvoudigen.
Notitie
Als de test alleen de kolomnamen zou retourneren (met behulp van Table.ColumnNames en geen gegevens, wordt de aanvraag naar de OData-service nooit daadwerkelijk verzonden. Dit komt doordat de aanroep die GetType het schema retourneert, dat alle informatie bevat die de M-engine nodig heeft om het resultaat te berekenen.
De derde test maakt gebruik van de optie MissingField.Ignore , waarmee de M-engine alle geselecteerde kolommen negeert die niet aanwezig zijn in de resultatenset. De OnSelectColumns handler hoeft zich geen zorgen te maken over deze optie: de M-engine verwerkt deze automatisch (dat wil gezegd, ontbrekende kolommen worden niet opgenomen in de columns lijst).
Notitie
De andere optie voor Table.SelectColumns, MissingField.UseNull, vereist een connector om de OnAddColumn handler te implementeren. Dit wordt gedaan in een volgende les.
De implementatie doet OnSelectColumns twee dingen:
- Hiermee voegt u de lijst met geselecteerde kolommen toe aan de
state. - Berekent de
Schemawaarde opnieuw, zodat u het juiste tabeltype kunt instellen.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl wordt bijgewerkt om de lijst met kolommen op te halen uit de status en deze te combineren (met een scheidingsteken) voor de $select parameter.
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
Table.Sort verwerken met OnSort
De OnSort handler ontvangt een lijst met records van het type:
type [ Name = text, Order = Int16.Type ]
Elke record bevat een Name veld dat de naam van de kolom aangeeft en een Order veld dat gelijk is aan Order.Ascending of Order.Descending.
In OData-termen wordt deze bewerking toegewezen aan de $orderby queryoptie.
De $orderby syntaxis heeft de kolomnaam gevolgd door asc of desc om oplopende of aflopende volgorde aan te geven. Wanneer u op meerdere kolommen sorteert, worden de waarden gescheiden door een komma. Als de columns parameter meer dan één item bevat, is het belangrijk om de volgorde te behouden waarin ze worden weergegeven.
Eenheidstests:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
Implementatie:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
Updates voor CalculateUrl:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
Table.RowCount verwerken met GetRowCount
In tegenstelling tot de andere query-handlers die u implementeert, retourneert de GetRowCount handler één waarde: het aantal rijen dat in de resultatenset wordt verwacht. In een M-query is deze waarde meestal het resultaat van de transformatie Table.RowCount .
U hebt een aantal verschillende opties voor het afhandelen van deze waarde als onderdeel van een OData-query:
- De $count queryparameter, die het aantal als een afzonderlijk veld in de resultatenset retourneert.
- Het padsegment /$count, dat alleen het totale aantal retourneert als een scalaire waarde.
Het nadeel van de queryparameterbenadering is dat u de hele query nog steeds naar de OData-service moet verzenden. Omdat het aantal inline wordt weergegeven als onderdeel van de resultatenset, moet u de eerste pagina met gegevens uit de resultatenset verwerken. Hoewel dit proces nog steeds efficiënter is dan het lezen van de volledige resultatenset en het tellen van de rijen, is het waarschijnlijk nog steeds meer werk dan u wilt doen.
Het voordeel van de padsegmentbenadering is dat u slechts één scalaire waarde in het resultaat ontvangt. Deze aanpak maakt de hele bewerking veel efficiënter. Zoals beschreven in de OData-specificatie, retourneert het /$count padsegment echter een fout als u andere queryparameters opneemt, zoals $top of $skip, die de bruikbaarheid ervan beperkt.
In deze zelfstudie hebt u de GetRowCount handler geïmplementeerd met behulp van de benadering van het padsegment. Als u de fouten wilt voorkomen die worden weergegeven als andere queryparameters zijn opgenomen, controleert u op andere statuswaarden en retourneert u een 'niet-geïmplementeerde fout' (...) als u deze hebt gevonden. Als u een fout van een Table.View-handler retourneert, wordt aan de M-engine aangegeven dat de bewerking niet kan worden gevouwen en dat deze in plaats daarvan moet terugvallen op de standaardhandler (waarmee in dit geval het totale aantal rijen wordt geteld).
Voeg eerst een eenheidstest toe:
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
Omdat het /$count padsegment één waarde retourneert (in tekst zonder opmaak) in plaats van een JSON-resultatenset, moet u ook een nieuwe interne functie (TripPin.Scalar) toevoegen om de aanvraag te maken en het resultaat te verwerken.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
De implementatie gebruikt deze functie (als er geen andere queryparameters worden gevonden in de state):
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
De CalculateUrl functie wordt bijgewerkt om toe te voegen aan /$count de URL als het RowCountOnly veld is ingesteld in de state.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
De nieuwe Table.RowCount eenheidstest moet nu slagen.
Als u de terugvalcase wilt testen, voegt u een andere test toe die de fout dwingt.
Voeg eerst een helpermethode toe waarmee het resultaat van een bewerking voor een try vouwfout wordt gecontroleerd.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
Voeg vervolgens een test toe die zowel Table.RowCount als Table.FirstN gebruikt om de fout af te dwingen.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
Een belangrijke opmerking hier is dat deze test nu een fout retourneert als Fout bij vouwen is ingesteld falseop , omdat de Table.RowCount bewerking terugvalt op de lokale (standaard) handler. Het uitvoeren van de tests met Fout bij vouwen foutset om true ervoor te zorgen dat de Table.RowCount test mislukt en de test kan slagen.
Conclusie
Het implementeren van Table.View voor uw connector voegt een aanzienlijke mate van complexiteit toe aan uw code. Omdat de M-engine alle transformaties lokaal kan verwerken, maakt het toevoegen van Table.View-handlers geen nieuwe scenario's mogelijk voor uw gebruikers, maar resulteert dit in efficiëntere verwerking (en mogelijk gelukkigere gebruikers). Een van de belangrijkste voordelen van de Table.View-handlers die optioneel zijn, is dat u hiermee incrementeel nieuwe functionaliteit kunt toevoegen zonder dat dit van invloed is op achterwaartse compatibiliteit voor uw connector.
Voor de meeste connectors is OnTake een belangrijke (en eenvoudige) handler die moet worden geïmplementeerd (die wordt $top omgezet in OData), omdat hiermee het aantal geretourneerde rijen wordt beperkt. De Power Query-ervaring voert altijd een OnTake aantal rijen uit bij het weergeven van 1000 voorbeelden in de navigator en query-editor, zodat uw gebruikers mogelijk aanzienlijke prestatieverbeteringen zien bij het werken met grotere gegevenssets.