Semantische modelmodi in de Power BI-service
Dit artikel bevat een technische uitleg van de semantische modelmodi van Power BI. Het is van toepassing op semantische modellen die een liveverbinding vertegenwoordigen met een extern gehost Analysis Services-model en ook op modellen die zijn ontwikkeld in Power BI Desktop. Het artikel benadrukt de logica voor elke modus en mogelijke gevolgen voor Power BI-capaciteitsbronnen.
De drie semantische modelmodi zijn:
Modus Importeren
De importmodus is de meest voorkomende modus die wordt gebruikt voor het ontwikkelen van semantische modellen. Deze modus biedt snelle prestaties dankzij query's in het geheugen. Het biedt ook ontwerpflexibiliteit voor modelleerders en ondersteuning voor specifieke Power BI-service functies (Q&A, Snelle inzichten, enzovoort). Vanwege deze sterke punten is het de standaardmodus bij het maken van een nieuwe Power BI Desktop-oplossing.
Het is belangrijk te weten dat geïmporteerde gegevens altijd op schijf worden opgeslagen. Wanneer er query's worden uitgevoerd of vernieuwd, moeten de gegevens volledig in het geheugen van de Power BI-capaciteit worden geladen. In het geheugen kunnen importmodellen vervolgens zeer snelle queryresultaten bereiken. Het is ook belangrijk om te begrijpen dat er geen concept is van een importmodel dat gedeeltelijk in het geheugen wordt geladen.
Bij het vernieuwen worden gegevens gecomprimeerd en geoptimaliseerd en vervolgens opgeslagen op schijf door de VertiPaq-opslagengine. Wanneer de schijf wordt geladen in het geheugen, is het mogelijk om 10 keer compressie te zien. Het is dus redelijk om te verwachten dat 10 GB aan brongegevens kan worden gecomprimeerd tot ongeveer 1 GB in grootte. Opslaggrootte op schijf kan een vermindering van 20% bereiken ten opzichte van de gecomprimeerde grootte. Het verschil in grootte kan worden bepaald door de bestandsgrootte van Power BI Desktop te vergelijken met het geheugengebruik van Taakbeheer van het bestand.
Ontwerpflexubiliteit kan op drie manieren worden bereikt:
- Integreer gegevens door gegevens uit gegevensstromen en externe gegevensbronnen in de cache te plaatsen, ongeacht het type of de indeling van de gegevensbron.
- Gebruik de volledige set formuletaal van Power Query M, aangeduid als M, functies bij het maken van query's voor gegevensvoorbereiding.
- Pas de volledige set DAX-functies (Data Analysis Expressions) toe bij het verbeteren van het model met bedrijfslogica. Er is ondersteuning voor berekende kolommen, berekende tabellen en metingen.
Zoals wordt weergegeven in de volgende afbeelding, kan een importmodel gegevens uit een willekeurig aantal ondersteunde gegevensbrontypen integreren.
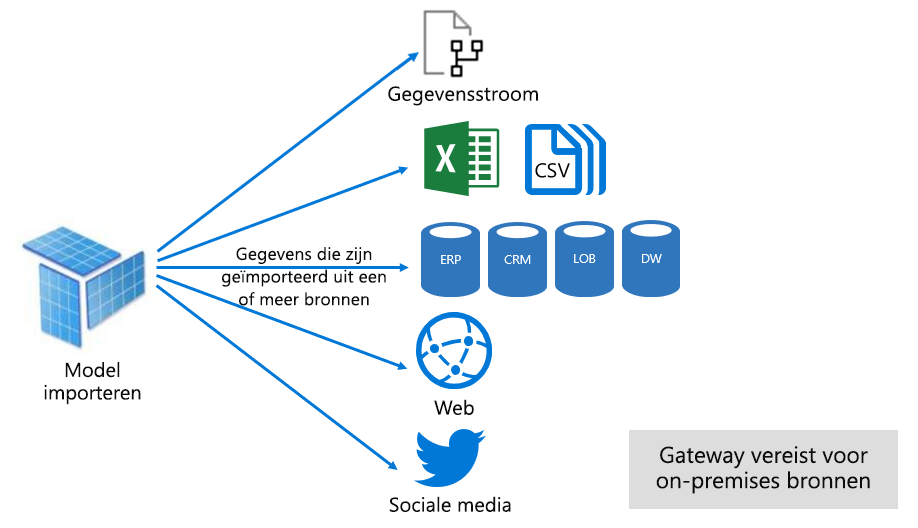
Hoewel er echter aantrekkelijke voordelen zijn gekoppeld aan Import-modellen, zijn er ook nadelen:
- Het hele model moet in het geheugen worden geladen voordat Power BI een query kan uitvoeren op het model, waardoor de beschikbare capaciteitsbronnen onder druk kunnen worden geplaatst, met name naarmate het aantal en de grootte van importmodellen toenemen.
- Modelgegevens zijn alleen zo actueel als de meest recente vernieuwing en importmodellen moeten dus worden vernieuwd, meestal op basis van een geplande basis.
- Met een volledige vernieuwing worden alle gegevens uit alle tabellen verwijderd en opnieuw geladen uit de gegevensbron. Deze bewerking kan duur zijn in termen van tijd en resources voor de Power BI-service en de gegevensbronnen.
Notitie
Power BI kan incrementeel vernieuwen bereiken om te voorkomen dat hele tabellen worden afgekapt en opnieuw geladen. Zie Incrementeel vernieuwen en realtime gegevens voor semantische modellen voor meer informatie, waaronder ondersteunde abonnementen en licenties.
Vanuit het perspectief van een Power BI-service resource is het volgende vereist voor het importeren van modellen:
- Voldoende geheugen om het model te laden wanneer het wordt opgevraagd of vernieuwd.
- Resources en extra geheugenbronnen verwerken om gegevens te vernieuwen.
DirectQuery-modus
De DirectQuery-modus is een alternatief voor de importmodus. Bij modellen die zijn ontwikkeld in de DirectQuery-modus worden geen gegevens geïmporteerd. In plaats daarvan bestaan ze alleen uit metagegevens die de modelstructuur definiëren. Wanneer het model wordt opgevraagd, worden systeemeigen query's gebruikt om gegevens op te halen uit de onderliggende gegevensbron.
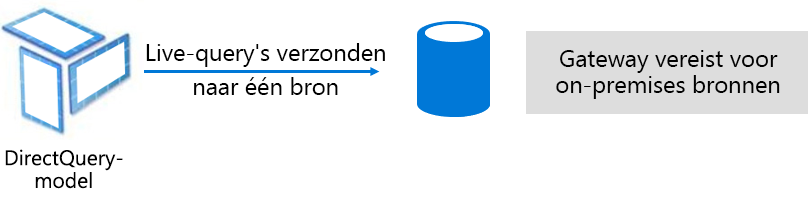
Er zijn twee belangrijke redenen om een DirectQuery-model te ontwikkelen:
- Wanneer gegevensvolumes te groot zijn, zelfs wanneer methoden voor gegevensreductie worden toegepast, om in een model te laden of praktisch te vernieuwen.
- Wanneer rapporten en dashboards bijna realtime gegevens moeten leveren, buiten wat binnen geplande vernieuwingslimieten kan worden bereikt. Geplande vernieuwingslimieten zijn acht keer per dag voor gedeelde capaciteit en 48 keer per dag voor een Premium-capaciteit.
Er zijn verschillende voordelen gekoppeld aan DirectQuery-modellen:
- Limieten voor modelgrootte importeren zijn niet van toepassing.
- Voor modellen is geen geplande gegevensvernieuwing vereist.
- Rapportgebruikers zien de meest recente gegevens bij interactie met rapportfilters en slicers. Rapportgebruikers kunnen ook het hele rapport vernieuwen om de huidige gegevens op te halen.
- Realtime rapporten kunnen worden ontwikkeld met behulp van de functie Pagina automatisch vernieuwen .
- Dashboardtegels, wanneer ze zijn gebaseerd op DirectQuery-modellen, kunnen automatisch worden bijgewerkt zo vaak als elke 15 minuten.
Er zijn echter enkele beperkingen gekoppeld aan DirectQuery-modellen:
- Power Query-/Mashup-expressies kunnen alleen functies zijn die kunnen worden getransponeerd naar systeemeigen query's die worden begrepen door de gegevensbron.
- DAX-formules zijn beperkt tot het gebruik van alleen functies die kunnen worden getransponeerd naar systeemeigen query's die door de gegevensbron worden begrepen. Berekende tabellen worden niet ondersteund.
- Snelle inzichten functies worden niet ondersteund.
Vanuit het oogpunt van een Power BI-service resource is voor DirectQuery-modellen het volgende vereist:
- Minimaal geheugen om het model (alleen metagegevens) te laden wanneer er query's op worden uitgevoerd.
- Soms moet de Power BI-service aanzienlijke processorresources gebruiken om query's te genereren en verwerken die naar de gegevensbron worden verzonden. Wanneer deze situatie zich voordoet, kan dit van invloed zijn op de doorvoer, met name wanneer gelijktijdige gebruikers query's uitvoeren op het model.
Zie DirectQuery gebruiken in Power BI Desktop voor meer informatie.
Samengestelde modus
De samengestelde modus kan import- en DirectQuery-modi combineren of meerdere DirectQuery-gegevensbronnen integreren. Modellen die zijn ontwikkeld in de samengestelde modus ondersteunen het configureren van de opslagmodus voor elke modeltabel. Deze modus ondersteunt ook berekende tabellen, gedefinieerd met DAX.
De tabelopslagmodus kan worden geconfigureerd als Import, DirectQuery of Dual. Een tabel die is geconfigureerd als dual-opslagmodus, is zowel Import als DirectQuery. Met deze instelling kan de Power BI-service bepalen welke modus het meest efficiënt kan worden gebruikt op basis van query's.
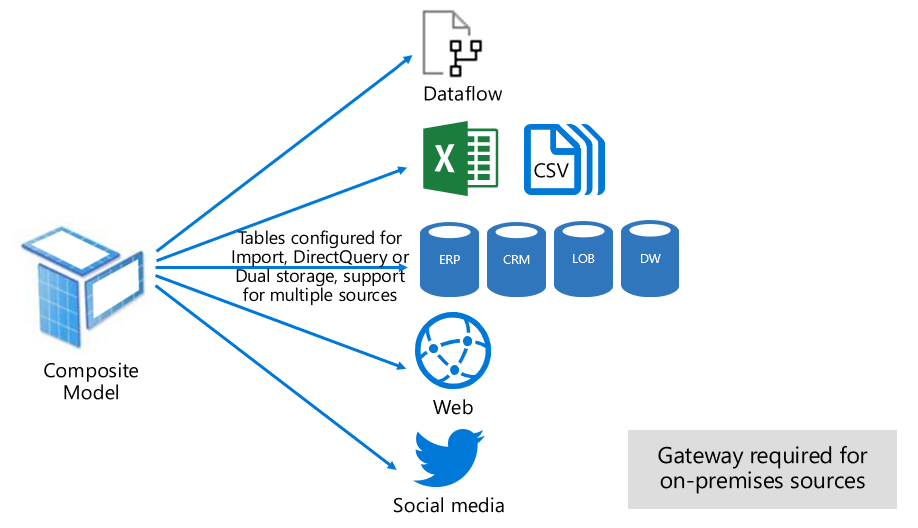
Samengestelde modellen streven ernaar om het beste van import- en DirectQuery-modi te leveren. Wanneer ze op de juiste manier zijn geconfigureerd, kunnen ze de hoge queryprestaties van in-memory modellen combineren met de mogelijkheid om bijna realtime gegevens op te halen uit gegevensbronnen.
Zie Samengestelde modellen gebruiken in Power BI Desktop voor meer informatie.
Pure Import- en DirectQuery-tabellen
Gegevensmodelleerders die samengestelde modellen ontwikkelen, configureren waarschijnlijk dimensietabellen in de import- of dual-opslagmodus en feitentabellen in de DirectQuery-modus. Zie Stervormige schema's en het belang van Power BI voor meer informatie over modeltabelrollen.
Denk bijvoorbeeld aan een model met een dimensietabel Product in de dual-modus en een feitentabel Sales in de DirectQuery-modus. De tabel Product kan efficiënt en snel vanuit het geheugen worden opgevraagd om een rapportslicer weer te geven. De tabel Verkoop kan ook worden opgevraagd in de DirectQuery-modus met de gerelateerde tabel Product . Met deze laatste query kan één efficiënte systeemeigen SQL-query worden gegenereerd waarmee product - en verkooptabellen worden samengevoegd en gefilterd op de slicerwaarden.
Hybride tabellen
Gegevensmodelleerders die samengestelde modellen ontwikkelen, kunnen ook feitentabellen als hybride tabellen configureren. Een hybride tabel is een tabel met een of meerdere Import-partities en één DirectQuery-partitie. Het voordeel van een hybride tabel is dat deze efficiënt en snel vanuit het geheugen kan worden opgevraagd, terwijl tegelijkertijd de meest recente gegevenswijzigingen van de gegevensbron die zich na de laatste importcyclus hebben voorgedaan, kunnen worden opgevraagd, zoals in de volgende visualisatie wordt geïllustreerd.
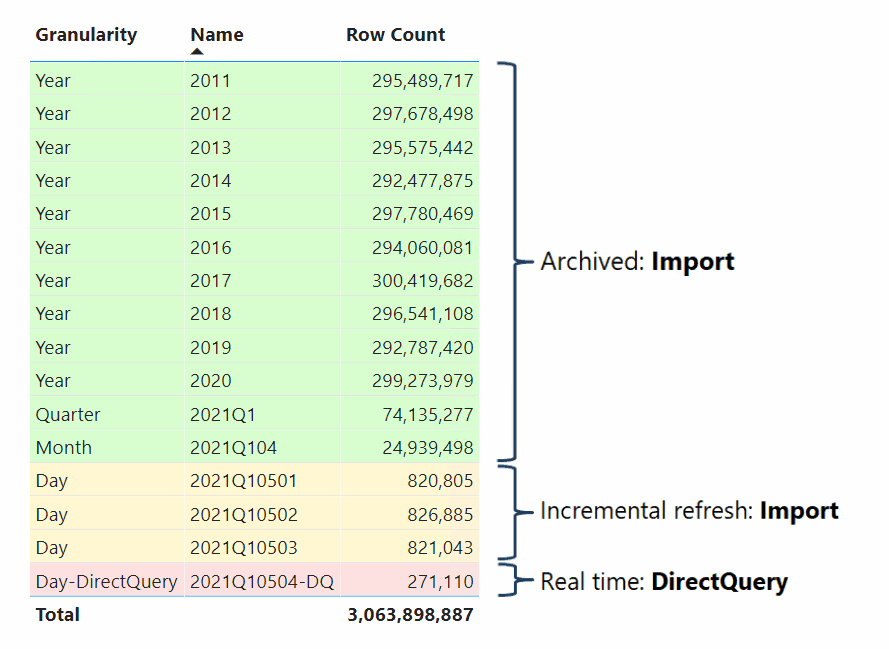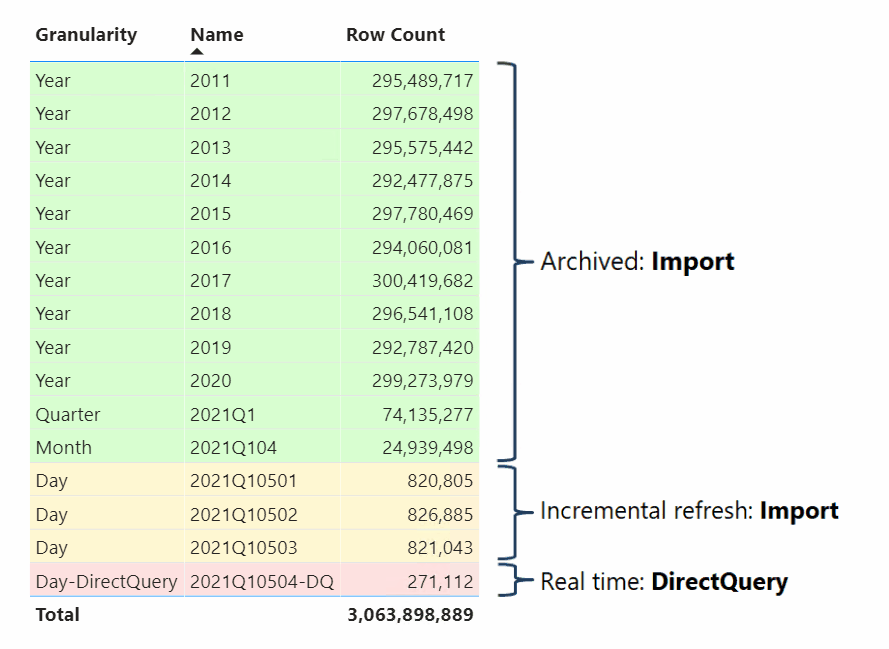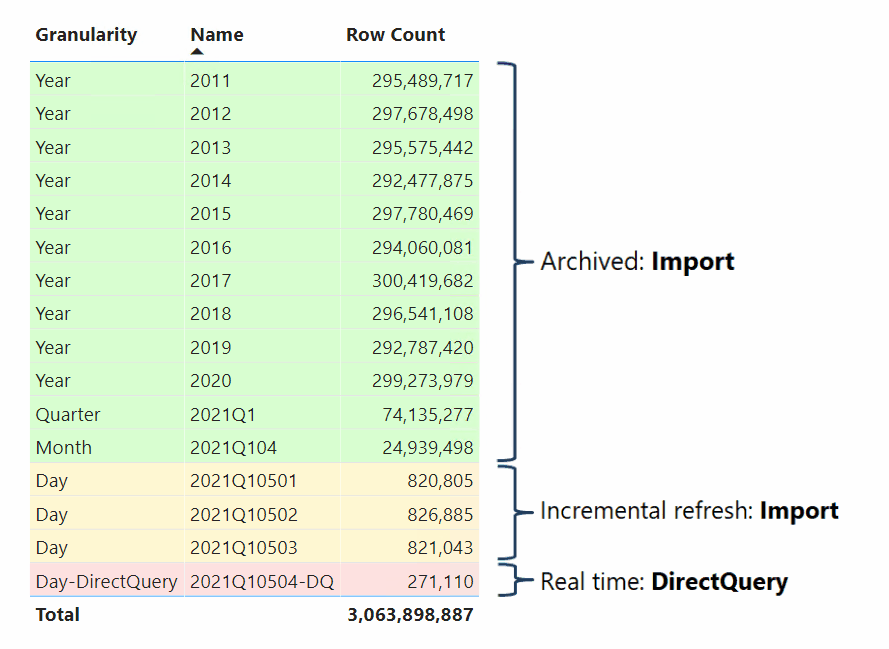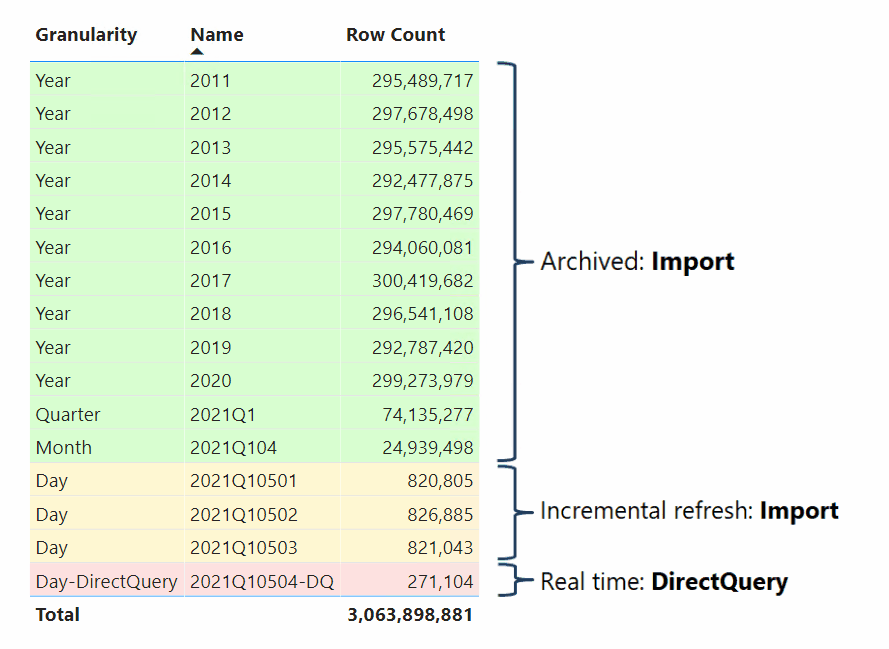
De eenvoudigste manier om een hybride tabel te maken, is door een beleid voor incrementeel vernieuwen in Power BI Desktop te configureren en de optie De meest recente gegevens in realtime ophalen in te schakelen met DirectQuery (alleen Premium). Wanneer Power BI een beleid voor incrementeel vernieuwen toepast waarvoor deze optie is ingeschakeld, wordt de tabel gepartitioneerd zoals het partitioneringsschema dat in het vorige diagram wordt weergegeven. Om goede prestaties te garanderen, configureert u uw dimensietabellen in de dual-opslagmodus, zodat Power BI efficiënte systeemeigen SQL-query's kan genereren bij het uitvoeren van query's op de DirectQuery-partitie.
Notitie
Power BI ondersteunt alleen hybride tabellen wanneer het semantische model wordt gehost in werkruimten op Premium-capaciteiten. Daarom moet u uw semantische model uploaden naar een Premium-werkruimte als u een beleid voor incrementeel vernieuwen configureert met de optie om de meest recente gegevens in realtime op te halen met DirectQuery. Zie Incrementeel vernieuwen en realtime gegevens voor semantische modellen voor meer informatie.
Het is ook mogelijk om een importtabel te converteren naar een hybride tabel door een DirectQuery-partitie toe te voegen met behulp van TMSL (Tabular Model Scripting Language) of het Tabular Object Model (TOM) of met behulp van een hulpprogramma van derden. U kunt bijvoorbeeld een feitentabel partitioneren, zodat het grootste deel van de gegevens in het datawarehouse wordt achtergelaten, terwijl slechts een fractie van de meest recente gegevens wordt geïmporteerd. Deze aanpak kan helpen om de prestaties te optimaliseren als het grootste deel van deze gegevens historische gegevens zijn die niet vaak worden geopend. Een hybride tabel kan meerdere importpartities hebben, maar slechts één DirectQuery-partitie.