OCR uitvoeren op meertalige documenten
Optische tekenherkenning (OCR) stelt u in staat om tekst uit afbeeldingen of het scherm te lokaliseren en te extraheren.
Hoewel de meeste scenario's vereisen dat u tekst in een specifieke taal afhandelt, zijn er gevallen waarin de bronnen meertalig zijn.
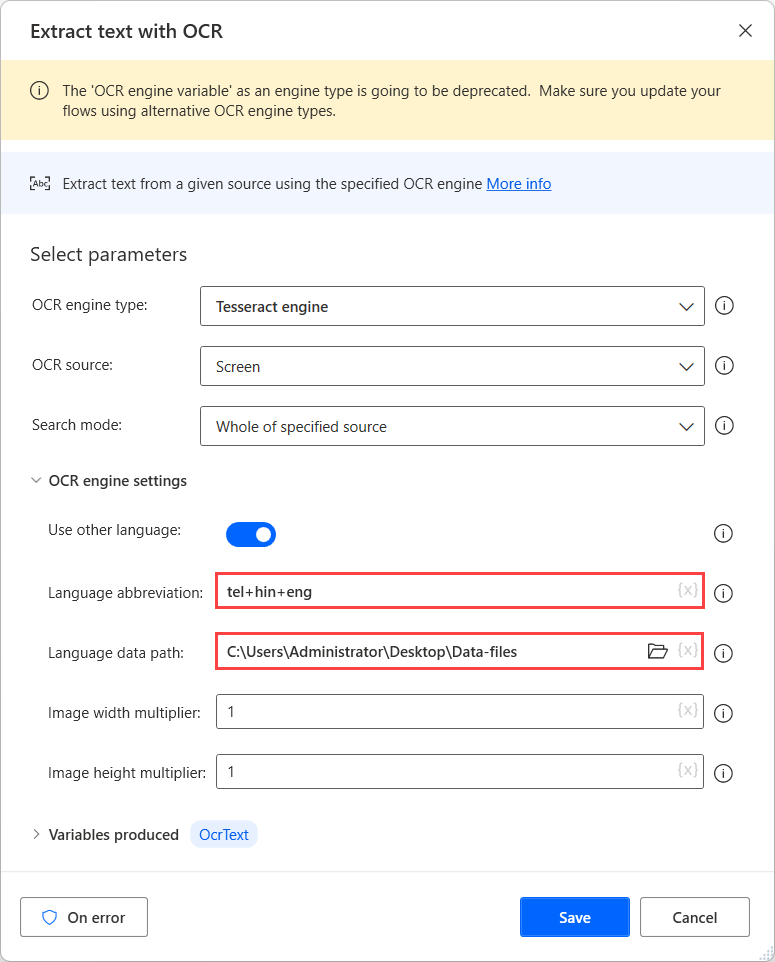
Als u OCR op deze bronnen wilt uitvoeren, gebruikt u een Tesseract-engine in de respectieve OCR-actie en schakelt u de optie Andere talen gebruiken in de engine-instellingen in.
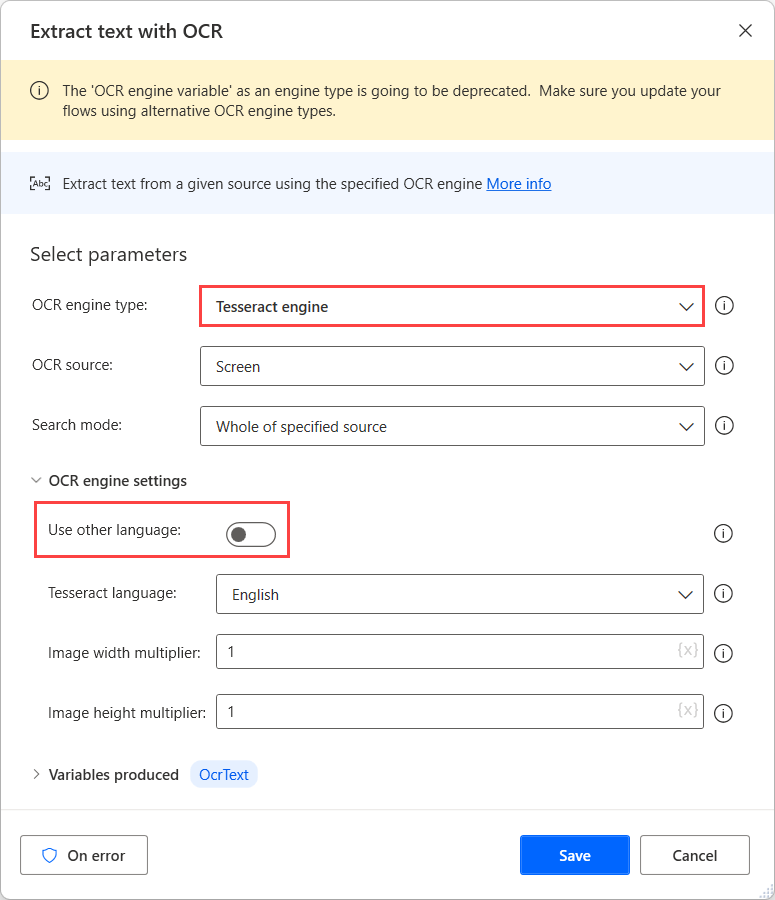
Wanneer de Andere talen gebruiken optie is ingeschakeld, geeft de actie twee extra instellingen weer: de Taalafkorting en Taal gegevenspad velden.
De Taalafkorting veld geeft aan de engine aan naar welke taal moet worden gezocht tijdens OCR. Het veld Pad voor taalgegevens bevat de taalgegevensbestanden (.traineddata) die worden gebruikt om de OCR-engine te trainen.
Nadat u de gegevensbestanden voor de benodigde talen hebt gedownload, verplaatst u ze naar een gemeenschappelijke map om ze onder hetzelfde pad beschikbaar te maken.
Selecteer vervolgens de aangemaakte map in het Taal gegevenspad veld, en vul de corresponderende taalcodes in het Taalafkorting veld. Om de taalcodes te scheiden,, gebruik het plusteken (+).
Notitie
U vindt alle beschikbare taalcodes in de bron van de taalgegevensbestanden. In het volgende voorbeeld vertegenwoordigen de gebruikte codes Telugu, Hindi en Engels.