Een vooraf samengesteld model gebruiken om informatie te extraheren uit eenvoudige documenten in Microsoft Syntex
Het eenvoudige documentverwerkingsmodel biedt een flexibele, vooraf getrainde oplossing voor het extraheren van informatie uit gestructureerde basisdocumenten, waaronder informatie zoals:
Sleutel-waardeparen : denk aan deze als labels en de bijbehorende informatie, zoals 'Naam: Adele Vance'.
Selectiemarkeringen : dit zijn selectievakjes of andere markeringen die keuzes of selecties in een document aangeven.
Benoemde entiteiten : dit zijn specifieke items, zoals namen van personen, plaatsen of organisaties die worden vermeld in de tekst van een document.
Streepjescodes : dit zijn machineleesbare weergaven van gegevens die kunnen worden gebruikt voor tracerings- of identificatiedoeleinden in een document.
In tegenstelling tot andere vooraf gemaakte modellen met vaste schema's, kan dit model sleutels identificeren die anderen mogelijk missen, wat een waardevol alternatief is voor aangepaste modellabels en -training. Dit model ondersteunt ook streepjescodes en taaldetectie.
Typen documenten
Eenvoudige documentverwerking werkt het beste met de typen documenten die gestructureerde informatie bevatten, zoals:
Forms: deze hebben vaak duidelijke velden en labels, waardoor sleutel-waardeparen gemakkelijker kunnen worden geëxtraheerd.
Facturen : bevatten doorgaans consistente indelingen met tabellen en sleutel-waardeparen.
Ontvangstbewijzen : net als facturen hebben ze gestructureerde gegevens die eenvoudig kunnen worden geëxtraheerd.
Contracten : bevat goed gedefinieerde secties en componenten die effectief kunnen worden geparseerd.
Bankafschriften : bevat tabellen en gestructureerde gegevens die ideaal zijn voor extractie.
Deze documenten profiteren van de mogelijkheden voor optische tekenherkenning (OCR) en deep learning-processen die worden gebruikt om sleutel-waardeparen, selectiemarkeringen, tabellen en benoemde entiteiten te extraheren.
Opmerking
Dit model is momenteel beschikbaar voor .pdf- en afbeeldingsbestandstypen en in meer dan 100 talen. In toekomstige versies worden meer ondersteunde bestandstypen toegevoegd.
Voer de volgende stappen uit om een eenvoudig documentverwerkingsmodel te gebruiken:
- Stap 1: het model maken
- Stap 2: een voorbeeldbestand uploaden om te analyseren
- Stap 3: Extractors voor uw model selecteren
- Stap 4: het model toepassen
Stap 1: het model maken
Volg de instructies in Een model maken in Syntex om een eenvoudig documentverwerkingsmodel te maken. Ga vervolgens verder met de volgende stappen om uw model te voltooien.
Stap 2: een voorbeeldbestand uploaden om te analyseren
Selecteer op de pagina Modellen in de sectie Een bestand toevoegen om te analyseren de optie Een bestand toevoegen.
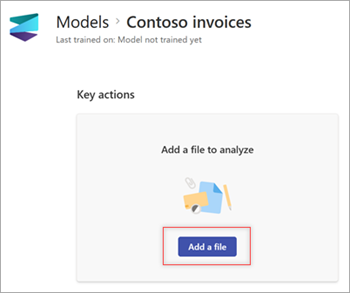
Selecteer op de pagina Bestanden om het model te analyserende optie Toevoegen om het bestand te vinden dat u wilt gebruiken.
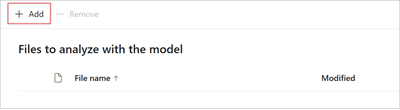
Selecteer op de pagina Een bestand toevoegen vanuit de bibliotheek met trainingsbestanden het bestand en selecteer vervolgens Toevoegen.
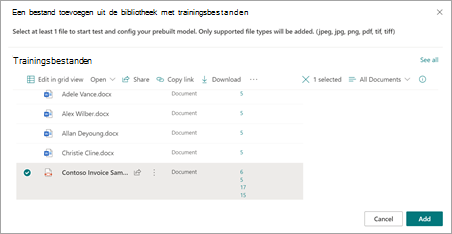
Selecteer volgende op de pagina Bestanden om het model te analyseren.
Stap 3: Extractors voor uw model selecteren
Op de pagina met gegevens van de extractor ziet u het documentgebied aan de rechterkant van de pagina en het deelvenster Extractors aan de linkerkant . In het deelvenster Extractors ziet u de lijst met extractoren die in het document zijn geïdentificeerd.
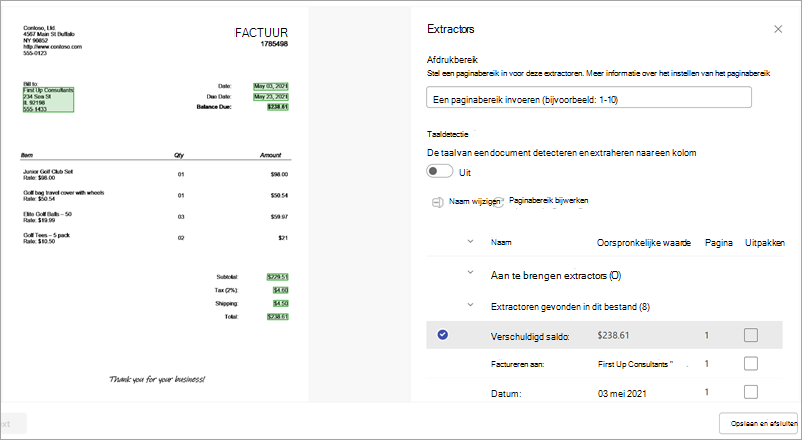
De entiteitsvelden die groen zijn gemarkeerd in het documentgebied, zijn de items die door het model zijn gedetecteerd tijdens de analyse van het bestand. Wanneer u een entiteit selecteert die u wilt extraheren, verandert het gemarkeerde veld in blauw. Als u later besluit de entiteit niet op te nemen, verandert het gemarkeerde veld in grijs. De markeringen maken het gemakkelijker om de huidige status te zien van de extractoren die u selecteert.
Tip
Als u wilt in- of uitzoomen om de entiteitsvelden te lezen, gebruikt u het schuifwieltje van uw muis of de zoombesturingselementen onder aan het documentgebied.
Een extractorentiteit selecteren
U kunt een extractor selecteren in het documentgebied of in het deelvenster Extractors , afhankelijk van uw voorkeur.
- Als u een extractor wilt selecteren in het documentgebied, selecteert u het entiteitsveld.
- Als u een extractor wilt selecteren in het deelvenster Extractors , schakelt u in de kolom Extraheren het bijbehorende selectievakje rechts van de naam van de entiteit in.
Wanneer u een extractor selecteert, wordt het vak Extractor selecteren? weergegeven in het documentgebied. In het vak ziet u de sleutelnaam (de naam die wordt gegenereerd voor de extractor), de gedetecteerde waarde (de waarde van dat veld in het document), het kolomtype en de optie om de entiteit als extractor te selecteren.
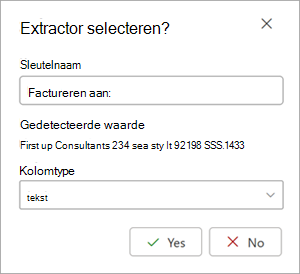
De sleutelnaam wordt gebruikt als de kolomnaam wanneer het model wordt toegepast op een SharePoint-bibliotheek. U kunt desgewenst de naam van de sleutel zo wijzigen dat deze meer beschrijvend is. Het kolomtype laat zien hoe de informatie wordt weergegeven in een bibliotheek. U kunt het kolomtype wijzigen om te laten zien hoe u de informatie wilt weergeven. Wanneer het model wordt toegepast op een bibliotheek, kunt u kolomopmaak gebruiken om op te geven hoe het model eruit moet zien in het document.
Ga door met het selecteren van andere extractoren die u wilt gebruiken. U kunt ook andere bestanden toevoegen om te analyseren voor deze modelconfiguratie.
De naam van een extractor wijzigen
Er zijn drie manieren waarop u de naam van een extractor kunt wijzigen:
Selecteer in het documentgebied van de pagina met gegevens van de extractor het entiteitsveld. Voer in het vak Extractor selecteren? in het veld Sleutelnaam een nieuwe naam in voor de extractor.
Selecteer in het deelvenster Extractors van de pagina met details van de extractor de extractor waarvan u de naam wilt wijzigen en selecteer vervolgens Naam wijzigen.
Selecteer op de startpagina van het model in de sectie Extractoren de extractor die u wilt wijzigen en selecteer vervolgens Naam wijzigen.
Een paginabereik instellen voor verwerking
Voor dit model kunt u opgeven om een bereik van pagina's voor een bestand te verwerken in plaats van het hele bestand. Selecteer in het deelvenster Extractors in de sectie Paginabereik de pagina die u wilt verwerken. Standaard is de instelling Paginabereik leeg. Als er geen paginabereik wordt opgegeven, wordt het hele document verwerkt. Zie Een paginabereik instellen om informatie uit specifieke pagina's te extraheren voor meer informatie.
De taal van een document detecteren
Voor dit model kunt u de taal van een document detecteren en extraheren naar een kolom. Schakel in het deelvenster Extractors in de sectie Taaldetectie de wisselknop in om taaldetectie in te schakelen. U ziet de ISO-code van de gedetecteerde taal.

U kunt taaldetectie ook in- of uitschakelen via het deelvenster Modelinstellingen voor het model.
Stap 4: het model toepassen
Als u wijzigingen wilt opslaan en wilt terugkeren naar de startpagina van het model, selecteert u Opslaan en afsluiten in het deelvenster Extractors.
Als u klaar bent om het model toe te passen op een bibliotheek , selecteert u volgende in het documentgebied. Kies in het deelvenster Toevoegen aan bibliotheek de bibliotheek waaraan u het model wilt toevoegen en selecteer vervolgens Toevoegen.
Zie Vereisten en beperkingen voor de verwerking van vooraf samengestelde documenten in SharePoint voor informatie over bestandstypen, talen, optische tekenherkenning en andere overwegingen voor dit vooraf samengestelde model.