hll_merge()
Van toepassing op: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel-
Hiermee worden de HLL-resultaten samengevoegd. Dit is de scalaire versie van de cumulatieve versie hll_merge().
Lees meer over het onderliggende algoritme van (HyperLogLog) en schattingsnauwkeurigheid.
Belangrijk
De resultaten van hll(), hll_if() en hll_merge() kunnen worden opgeslagen en later worden opgehaald. U kunt bijvoorbeeld een dagelijkse unieke gebruikerssamenvatting maken, die vervolgens kan worden gebruikt om wekelijkse aantallen te berekenen. De nauwkeurige binaire weergave van deze resultaten kan echter na verloop van tijd veranderen. Er is geen garantie dat deze functies identieke resultaten produceren voor identieke invoer, en daarom raden we u niet aan om erop te vertrouwen.
Syntaxis
hll_merge(
hll,hll2, [ hll3, ... ])
Meer informatie over syntaxisconventies.
Parameters
| Naam | Type | Vereist | Beschrijving |
|---|---|---|---|
| hll, hll2, ... | string |
✔️ | De kolomnamen met HLL-waarden die moeten worden samengevoegd. De functie verwacht tussen 2 en 64 argumenten. |
Retourneert
Retourneert één HLL-waarde. De waarde is het resultaat van het samenvoegen van de kolommen hll, hll2, ... hllN-.
Voorbeelden
In dit voorbeeld ziet u de waarde van de samengevoegde kolommen.
range x from 1 to 10 step 1
| extend y = x + 10
| summarize hll_x = hll(x), hll_y = hll(y)
| project merged = hll_merge(hll_x, hll_y)
| project dcount_hll(merged)
uitvoer
dcount_hll_merged |
|---|
| 20 |
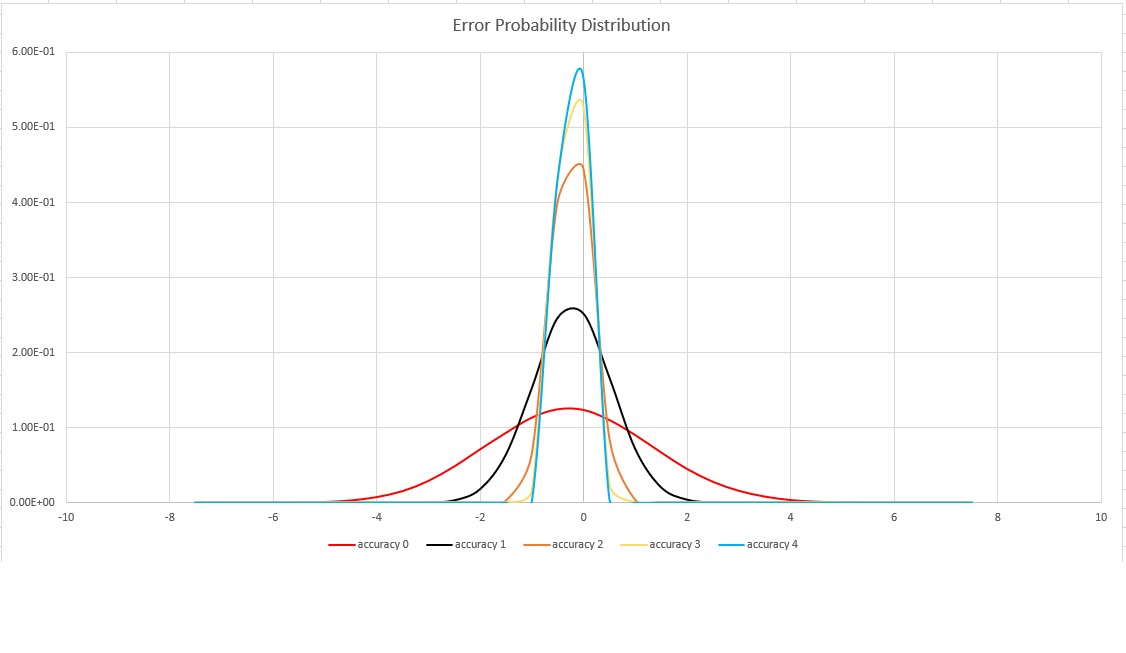
Nauwkeurigheid van schatting
Deze functie maakt gebruik van een variant van het HyperLogLog-algoritme (HLL), waarmee een stochastische schatting van de setkardinaliteit wordt uitgevoerd. Het algoritme biedt een 'knop' die kan worden gebruikt om de nauwkeurigheid en uitvoeringstijd per geheugengrootte te verdelen:
| Nauwkeurigheid | Fout (%) | Aantal vermeldingen |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0.8 | 214 |
| 2 | 0.4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Notitie
De kolom Aantal vermeldingen is het aantal 1-bytetellers in de HLL-implementatie.
Het algoritme bevat enkele voorzieningen voor het uitvoeren van een perfecte telling (nulfout), als de setkardinaliteit klein genoeg is:
- Wanneer het nauwkeurigheidsniveau wordt
1, worden 1000 waarden geretourneerd - Wanneer het nauwkeurigheidsniveau wordt
2, worden 8000 waarden geretourneerd
De foutgrens is probabilistisch, niet een theoretische gebonden. De waarde is de standaarddeviatie van foutverdeling (de sigma) en 99,7% van de schattingen hebben een relatieve fout van minder dan 3 x sigma.
In de volgende afbeelding ziet u de kansverdelingsfunctie van de relatieve schattingsfout, in percentages, voor alle ondersteunde nauwkeurigheidsinstellingen:
Verwante inhoud
- hll() en tdigest() gebruiken
- hll() (aggregatiefunctie)
- hll_if() (aggregatiefunctie)
- hll_merge() (aggregatiefunctie)