Ervaringsspecifieke richtlijnen voor herstel na noodgevallen
Dit document bevat ervaringsspecifieke richtlijnen voor het herstellen van uw Fabric-gegevens in het geval van een regionale ramp.
Voorbeeldscenario
In een aantal richtlijnen in dit document wordt het volgende voorbeeldscenario gebruikt voor uitleg en illustratie. Raadpleeg dit scenario indien nodig.
Stel dat u een capaciteit C1 in regio A hebt met een werkruimte W1. Als u herstel na noodgevallen voor capaciteit C1 hebt ingeschakeld, worden OneLake-gegevens gerepliceerd naar een back-up in regio B. Als regio A onderbrekingen ondervindt, voert de Fabric-service in C1 een failover uit naar regio B.
In de volgende afbeelding ziet u dit scenario. In het vak aan de linkerkant ziet u de verstoorde regio. Het vak in het midden vertegenwoordigt de voortdurende beschikbaarheid van de gegevens na een failover en het vak aan de rechterkant toont de volledig gedekte situatie nadat de klant heeft deelgenomen aan het herstellen van hun services naar volledige functie.
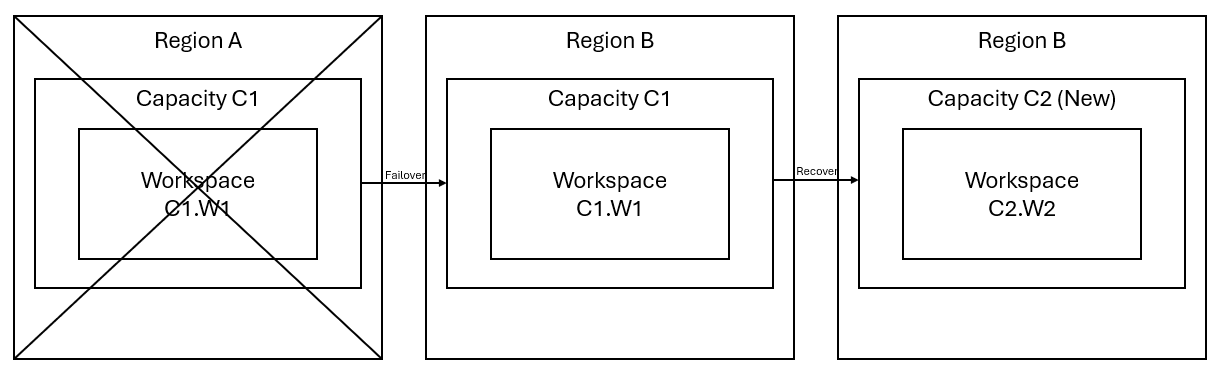
Dit is het algemene herstelplan:
Maak een nieuwe Infrastructuurcapaciteit C2 in een nieuwe regio.
Maak een nieuwe W2-werkruimte in C2, inclusief de bijbehorende items met dezelfde namen als in C1. W1.
Kopieer gegevens uit de onderbroken C1. W1 tot C2. W2.
Volg de speciale instructies voor elk onderdeel om items te herstellen naar hun volledige functie.
Ervaringsspecifieke herstelplannen
De volgende secties bevatten stapsgewijze handleidingen voor elke Fabric-ervaring om klanten te helpen bij het herstelproces.
Data engineer
In deze handleiding wordt u begeleid bij de herstelprocedures voor de Data-engineer-ervaring. Hierin worden lakehouses, notebooks en Spark-taakdefinities behandeld.
Lakehouse
Lakehouses uit de oorspronkelijke regio blijven niet beschikbaar voor klanten. Om een lakehouse te herstellen, kunnen klanten deze opnieuw maken in werkruimte C2. W2. We raden twee benaderingen aan voor het herstellen van lakehouses:
Benadering 1: Aangepast script gebruiken om Lakehouse Delta-tabellen en -bestanden te kopiëren
Klanten kunnen lakehouses opnieuw maken met behulp van een aangepast Scala-script.
Maak het lakehouse (bijvoorbeeld LH1) in de zojuist gemaakte werkruimte C2. W2.
Maak een nieuw notitieblok in de werkruimte C2. W2.
Als u de tabellen en bestanden uit het oorspronkelijke Lakehouse wilt herstellen, raadpleegt u de gegevens met OneLake-paden zoals abfss (zie Verbinding maken met Microsoft OneLake). U kunt het onderstaande codevoorbeeld (zie Inleiding tot Microsoft Spark Utilities) in het notebook gebruiken om de ABFS-paden van bestanden en tabellen op te halen uit het oorspronkelijke lakehouse. (Vervang C1. W1 met de werkelijke naam van de werkruimte)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Gebruik het volgende codevoorbeeld om tabellen en bestanden te kopiëren naar het zojuist gemaakte Lakehouse.
Voor Delta-tabellen moet u tabel één voor één kopiëren om te herstellen in het nieuwe lakehouse. In het geval van Lakehouse-bestanden kunt u de volledige bestandsstructuur met alle onderliggende mappen kopiëren met één uitvoering.
Neem contact op met het ondersteuningsteam voor de tijdstempel van failover die is vereist in het script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Zodra u het script uitvoert, worden de tabellen weergegeven in het nieuwe lakehouse.
Benadering 2: Azure Storage Explorer gebruiken om bestanden en tabellen te kopiëren
Als u alleen specifieke Lakehouse-bestanden of -tabellen uit het oorspronkelijke Lakehouse wilt herstellen, gebruikt u Azure Storage Explorer. Raadpleeg OneLake integreren met Azure Storage Explorer voor gedetailleerde stappen. Gebruik Benadering 1 voor grote gegevensgrootten.
Notitie
Met de twee hierboven beschreven benaderingen worden zowel de metagegevens als de gegevens voor tabellen in Delta-indeling hersteld, omdat de metagegevens zich gezamenlijk bevinden en worden opgeslagen met de gegevens in OneLake. Voor niet-Delta-opgemaakte tabellen (e.g. CSV, Parquet, enzovoort) die zijn gemaakt met DDL-scripts (Spark Data Definition Language), is de gebruiker verantwoordelijk voor het onderhouden en opnieuw uitvoeren van de Spark DDL-scripts/-opdrachten om ze te herstellen.
Notebook
Notebooks uit de primaire regio blijven niet beschikbaar voor klanten en de code in notebooks wordt niet gerepliceerd naar de secundaire regio. Als u notebookcode in de nieuwe regio wilt herstellen, zijn er twee benaderingen voor het herstellen van notebookcode-inhoud.
Benadering 1: door de gebruiker beheerde redundantie met Git-integratie (in openbare preview)
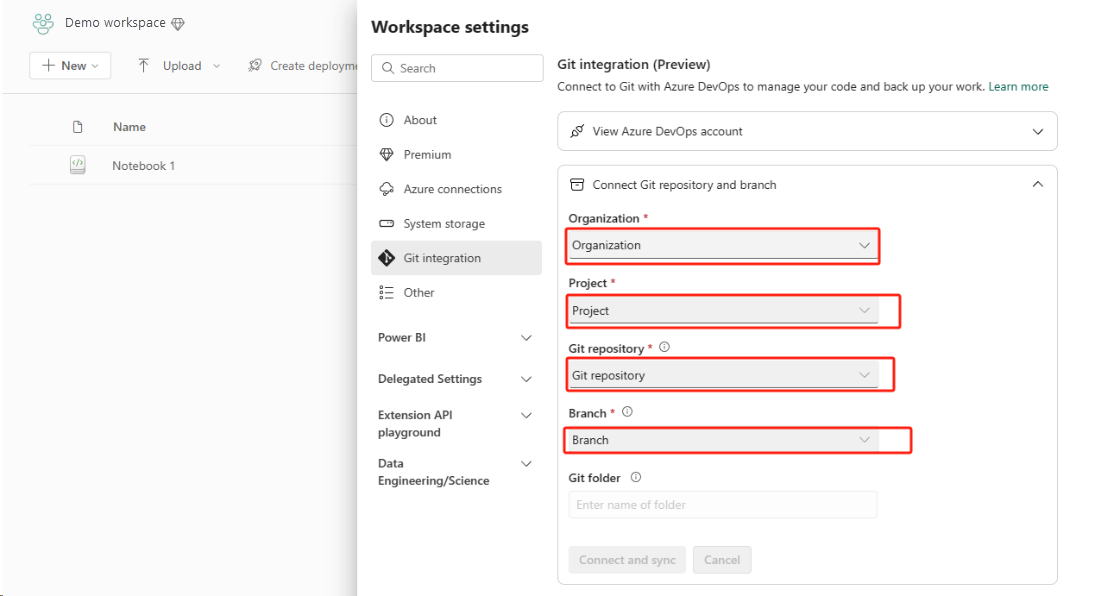
De beste manier om dit eenvoudig en snel te maken, is door Fabric Git-integratie te gebruiken en uw notebook vervolgens te synchroniseren met uw ADO-opslagplaats. Nadat de service een failover naar een andere regio heeft uitgevoerd, kunt u de opslagplaats gebruiken om het notebook opnieuw op te bouwen in de nieuwe werkruimte die u hebt gemaakt.
Configureer Git-integratie voor uw werkruimte en selecteer Verbinding maken en synchroniseren met ADO-opslagplaats.
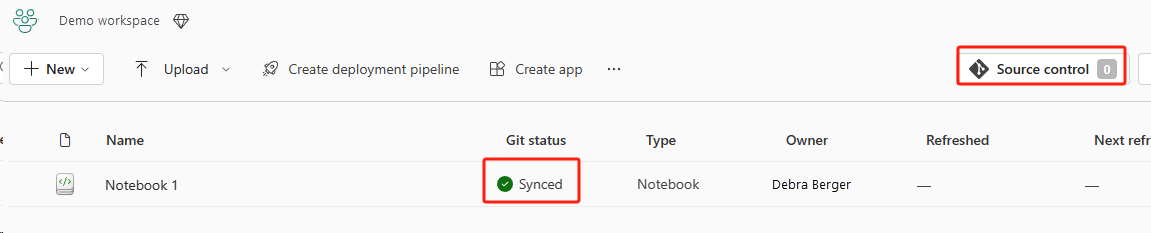
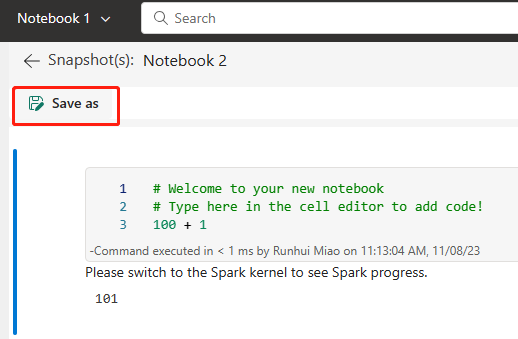
In de volgende afbeelding ziet u het gesynchroniseerde notitieblok.
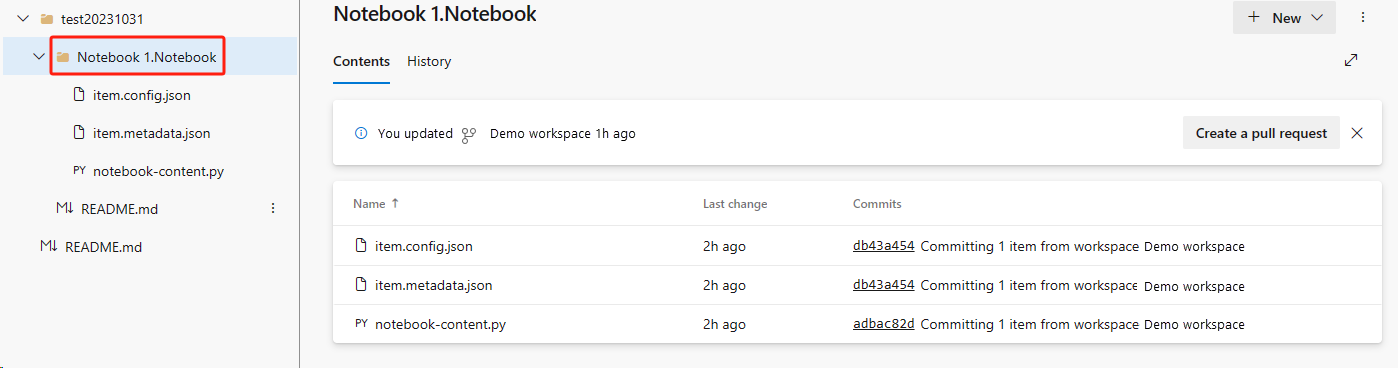
Herstel het notitieblok uit de ADO-opslagplaats.
Maak opnieuw verbinding met uw Azure ADO-opslagplaats in de zojuist gemaakte werkruimte.
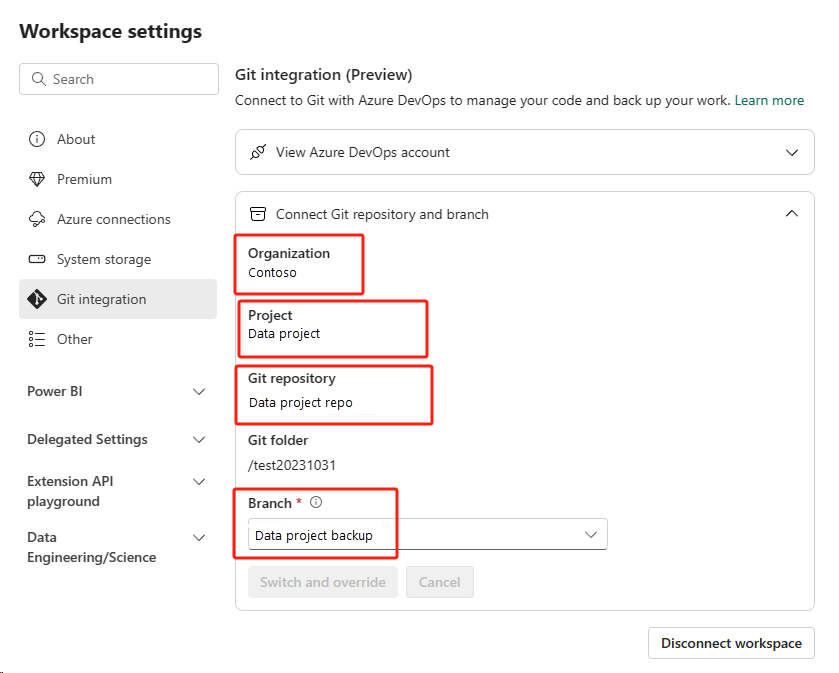
Selecteer de knop Broncodebeheer. Selecteer vervolgens de relevante vertakking van de opslagplaats. Selecteer vervolgens Alles bijwerken. Het oorspronkelijke notitieblok wordt weergegeven.
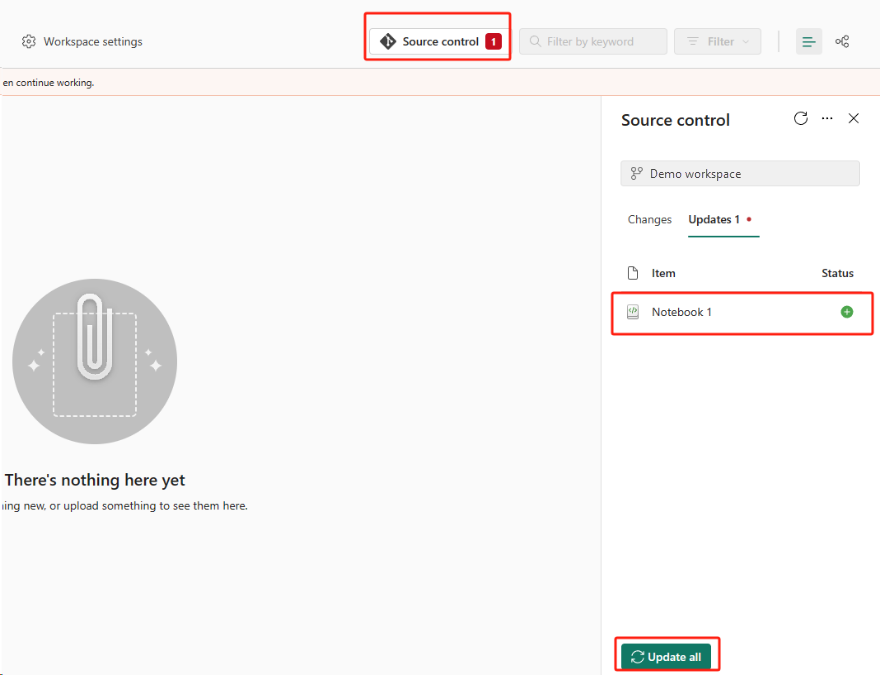
Als het oorspronkelijke notitieblok een standaard lakehouse heeft, kunnen gebruikers verwijzen naar de sectie Lakehouse om het lakehouse te herstellen en vervolgens het zojuist herstelde lakehouse te verbinden met het zojuist herstelde notitieblok.
De Git-integratie biedt geen ondersteuning voor het synchroniseren van bestanden, mappen of momentopnamen van notitieblokken in de resourceverkenner van notebooks.
Als het oorspronkelijke notitieblok bestanden bevat in de resourceverkenner van het notitieblok:
Zorg ervoor dat u bestanden of mappen opslaat op een lokale schijf of op een andere locatie.
Upload het bestand opnieuw vanaf uw lokale schijf of cloudstations naar het herstelde notebook.
Als het oorspronkelijke notitieblok een momentopname van het notitieblok heeft, slaat u de momentopname van het notitieblok ook op in uw eigen versiebeheersysteem of lokale schijf.
Zie Inleiding tot Git-integratie voor meer informatie over Git-integratie.
Benadering 2: Handmatige benadering voor het maken van back-ups van code-inhoud
Als u niet de Git-integratiebenadering gebruikt, kunt u de nieuwste versie van uw code, bestanden in resourceverkenner en momentopname van notebooks opslaan in een versiebeheersysteem zoals Git, en de inhoud van het notitieblok handmatig herstellen na een noodgeval:
Gebruik de functie Notebook importeren om de notebookcode te importeren die u wilt herstellen.
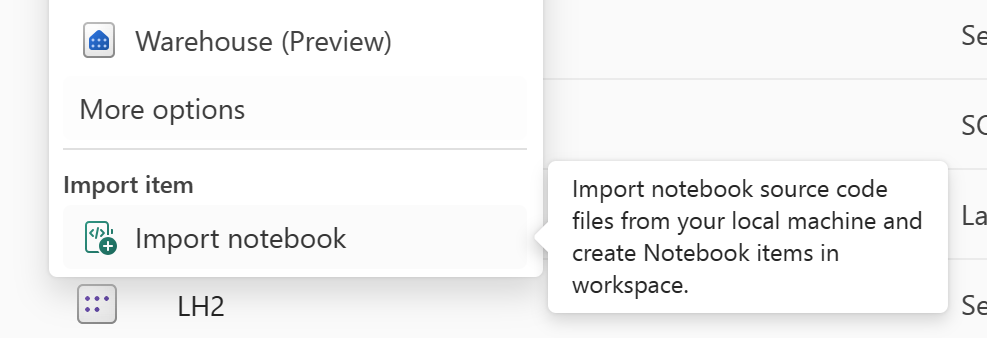
Ga na het importeren naar de gewenste werkruimte (bijvoorbeeld 'C2. W2") om er toegang toe te krijgen.
Als het oorspronkelijke notitieblok een standaard lakehouse heeft, raadpleegt u de sectie Lakehouse. Verbind vervolgens het zojuist herstelde lakehouse (dat dezelfde inhoud heeft als de oorspronkelijke standaard lakehouse) met het zojuist herstelde notebook.
Als het oorspronkelijke notitieblok bestanden of mappen bevat in de resourceverkenner, uploadt u de bestanden of mappen die zijn opgeslagen in het versiebeheersysteem van de gebruiker.
Spark-taakdefinitie
Spark-taakdefinities (SJD) uit de primaire regio blijven niet beschikbaar voor klanten en het hoofddefinitiebestand en het referentiebestand in het notebook worden gerepliceerd naar de secundaire regio via OneLake. Als u de SJD in de nieuwe regio wilt herstellen, kunt u de handmatige stappen volgen die hieronder worden beschreven om de SJD te herstellen. Houd er rekening mee dat historische uitvoeringen van de SJD niet worden hersteld.
U kunt de SJD-items herstellen door de code uit de oorspronkelijke regio te kopiëren met behulp van Azure Storage Explorer en na het noodgeval handmatig opnieuw verbinding te maken met Lakehouse-verwijzingen.
Maak een nieuw SJD-item (bijvoorbeeld SJD1) in de nieuwe werkruimte C2. W2, met dezelfde instellingen en configuraties als het oorspronkelijke SJD-item (bijvoorbeeld taal, omgeving, enzovoort).
Gebruik Azure Storage Explorer om bibliotheken, mains en momentopnamen van het oorspronkelijke SJD-item te kopiëren naar het nieuwe SJD-item.
De code-inhoud wordt weergegeven in de zojuist gemaakte SJD. U moet de zojuist herstelde Lakehouse-verwijzing handmatig toevoegen aan de taak (raadpleeg de herstelstappen van Lakehouse). Gebruikers moeten de oorspronkelijke opdrachtregelargumenten handmatig opnieuw opgeven.
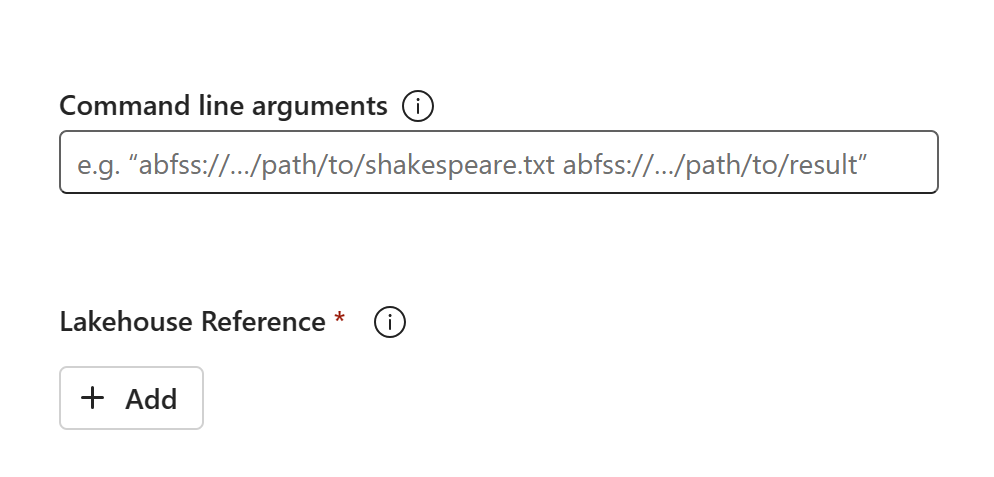
U kunt nu uw zojuist herstelde SJD uitvoeren of plannen.
Zie OneLake integreren met Azure Storage Explorer voor meer informatie over Azure Storage Explorer.
Gegevenswetenschap
In deze handleiding wordt u begeleid bij de herstelprocedures voor de Datawetenschap ervaring. Hierin worden ML-modellen en -experimenten behandeld.
ML-model en -experiment
Datawetenschap items uit de primaire regio niet beschikbaar blijven voor klanten en de inhoud en metagegevens in ML-modellen en experimenten worden niet gerepliceerd naar de secundaire regio. Als u ze volledig wilt herstellen in de nieuwe regio, slaat u de code-inhoud op in een versiebeheersysteem (zoals Git) en voert u de code-inhoud handmatig opnieuw uit na het noodgeval.
Herstel het notitieblok. Raadpleeg de stappen voor notebookherstel.
Configuratie, historisch uitgevoerde metrische gegevens en metagegevens worden niet gerepliceerd naar de gekoppelde regio. U moet elke versie van uw data science-code opnieuw uitvoeren om ML-modellen en experimenten volledig te herstellen na het noodgeval.
Datawarehouse
In deze handleiding wordt u begeleid bij de herstelprocedures voor de datawarehouse-ervaring. Het behandelt magazijnen.
Magazijn
Magazijnen uit de oorspronkelijke regio blijven niet beschikbaar voor klanten. Gebruik de volgende twee stappen om magazijnen te herstellen.
Maak een nieuw interim lakehouse in werkruimte C2. W2 voor de gegevens die u uit het oorspronkelijke magazijn kopieert.
Vul de Delta-tabellen van het magazijn in door gebruik te maken van warehouse Explorer en de T-SQL-mogelijkheden (zie Tabellen in datawarehousing in Microsoft Fabric).
Notitie
Het is raadzaam om uw warehousecode (schema, tabel, weergave, opgeslagen procedure, functiedefinities en beveiligingscodes) op een veilige locatie (zoals Git) op te slaan op basis van uw ontwikkelprocedures.
Gegevensopname via Lakehouse en T-SQL-code
In nieuw gemaakte werkruimte C2. W2:
Maak een interim lakehouse "LH2" in C2. W2.
Herstel de Delta-tabellen in het interim lakehouse van het oorspronkelijke magazijn door de stappen voor het herstel van Lakehouse te volgen.
Maak een nieuw magazijn 'WH2' in C2. W2.
Verbind de interim lakehouse in uw magazijnverkenner.
Afhankelijk van hoe u tabeldefinities gaat implementeren voordat u gegevens importeert, kan de werkelijke T-SQL die voor import wordt gebruikt, variëren. U kunt INSERT INTO, SELECT INTO of CREATE TABLE AS SELECT gebruiken om magazijntabellen te herstellen uit lakehouses. Verder in het voorbeeld gebruiken we INSERT INTO smaak. (Als u de onderstaande code gebruikt, vervangt u voorbeelden door werkelijke tabel- en kolomnamen)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOWijzig ten slotte de verbindingsreeks in toepassingen met behulp van uw Fabric-magazijn.
Notitie
Voor klanten die noodherstel in meerdere regio's en volledig geautomatiseerde bedrijfscontinuïteit nodig hebben, raden we u aan om twee fabricwarehouse-instellingen in afzonderlijke Fabric-regio's te bewaren en code en gegevenspariteit te onderhouden door regelmatige implementaties en gegevensopname op beide sites uit te voeren.
Gespiegelde database
Gespiegelde databases uit de primaire regio blijven niet beschikbaar voor klanten en de instellingen worden niet gerepliceerd naar de secundaire regio. Als u deze wilt herstellen in het geval van een regionale fout, moet u de gespiegelde database opnieuw maken in een andere werkruimte vanuit een andere regio.
Data Factory
Data Factory-items uit de primaire regio blijven niet beschikbaar voor klanten en de instellingen en configuratie in gegevenspijplijnen of gegevensstroom gen2-items worden niet gerepliceerd naar de secundaire regio. Als u deze items wilt herstellen in het geval van een regionale fout, moet u de Data-Integratie items in een andere werkruimte opnieuw maken vanuit een andere regio. In de volgende secties worden de details beschreven.
Gegevensstromen Gen2
Als u een Dataflow Gen2-item in de nieuwe regio wilt herstellen, moet u een PQT-bestand exporteren naar een versiebeheersysteem zoals Git en de Inhoud van Dataflow Gen2 na het noodgeval handmatig herstellen.
Selecteer in uw Dataflow Gen2-item op het tabblad Start van de Power Query-editor de optie Sjabloon Exporteren.
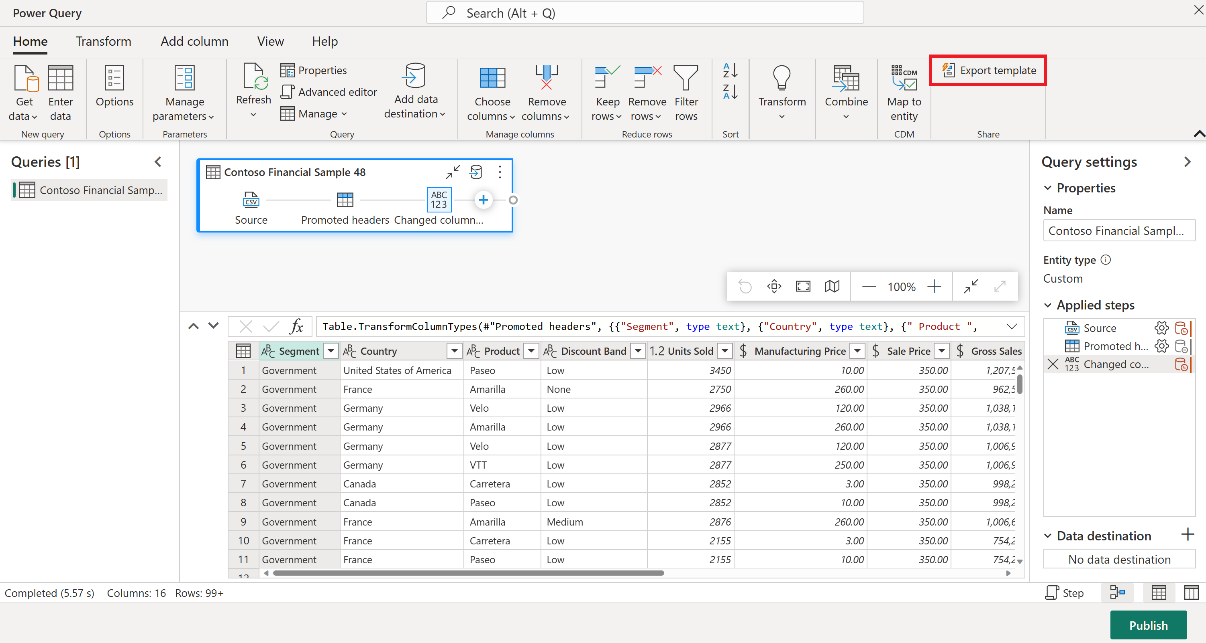
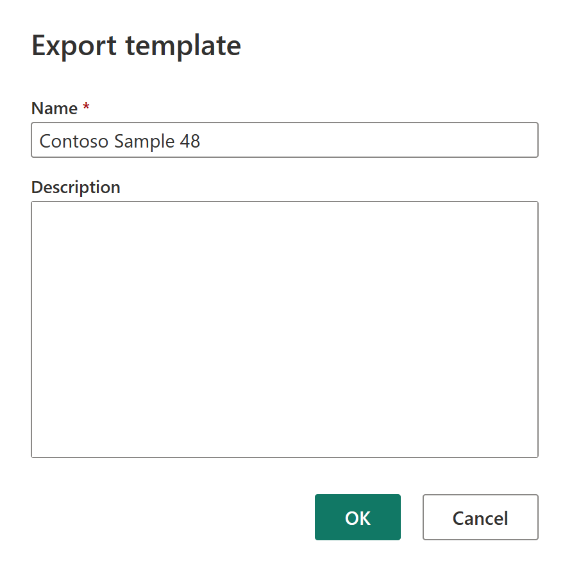
Voer in het dialoogvenster Sjabloon exporteren een naam (verplicht) en een beschrijving (optioneel) in voor deze sjabloon. Selecteer OK als u klaar bent.
Maak na het noodgeval een nieuw Dataflow Gen2-item in de nieuwe werkruimte C2. W2".
Selecteer Importeren uit een Power Query-sjabloon in het huidige weergavevenster van de Power Query-editor.
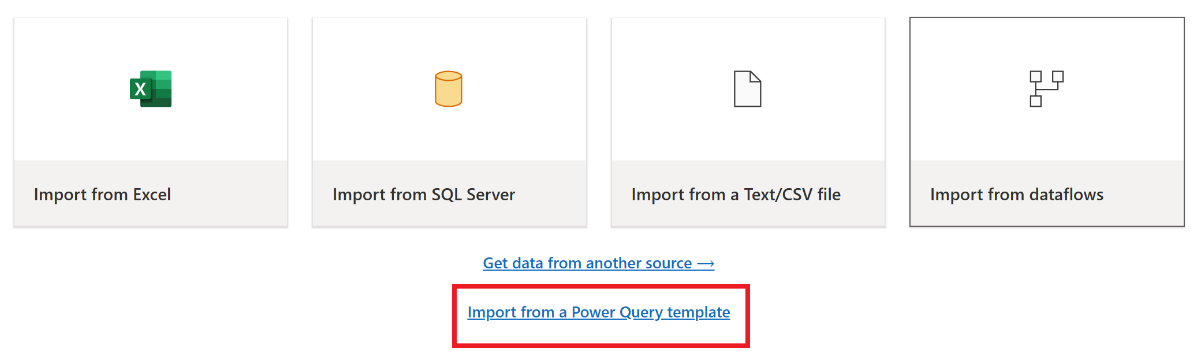
Blader in het dialoogvenster Openen naar de standaardmap downloads en selecteer het PQT-bestand dat u in de vorige stappen hebt opgeslagen. Selecteer vervolgens Openen.
De sjabloon wordt vervolgens geïmporteerd in uw nieuwe Dataflow Gen2-item.
Gegevenspijplijnen
Klanten hebben geen toegang tot gegevenspijplijnen in het geval van regionale noodgevallen en de configuraties worden niet gerepliceerd naar de gekoppelde regio. We raden u aan uw kritieke gegevenspijplijnen in meerdere werkruimten in verschillende regio's te bouwen.
Kopieer Taak
CopyJob-gebruikers moeten proactieve maatregelen nemen om te beschermen tegen een regionale ramp. De volgende aanpak zorgt ervoor dat na een regionale ramp de CopyJobs van een gebruiker beschikbaar blijven.
Door de gebruiker beheerde redundantie met Git-integratie (in openbare preview)
De beste manier om dit proces eenvoudig en snel te maken, is door Fabric Git-integratie te gebruiken en vervolgens uw CopyJob te synchroniseren met uw ADO-opslagplaats. Nadat de service een failover naar een andere regio heeft uitgevoerd, kunt u de opslagplaats gebruiken om de CopyJob opnieuw te bouwen in de nieuwe werkruimte die u hebt gemaakt.
Configureer de Git-integratie van uw werkruimte en selecteer verbinden en synchroniseren met ADO-repository.
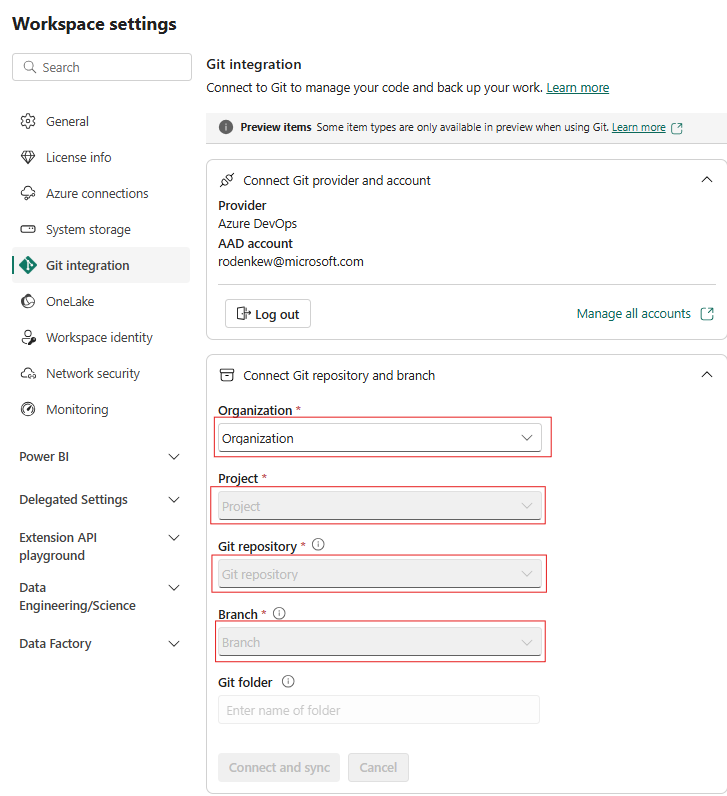
In de volgende afbeelding ziet u de gesynchroniseerde CopyJob.
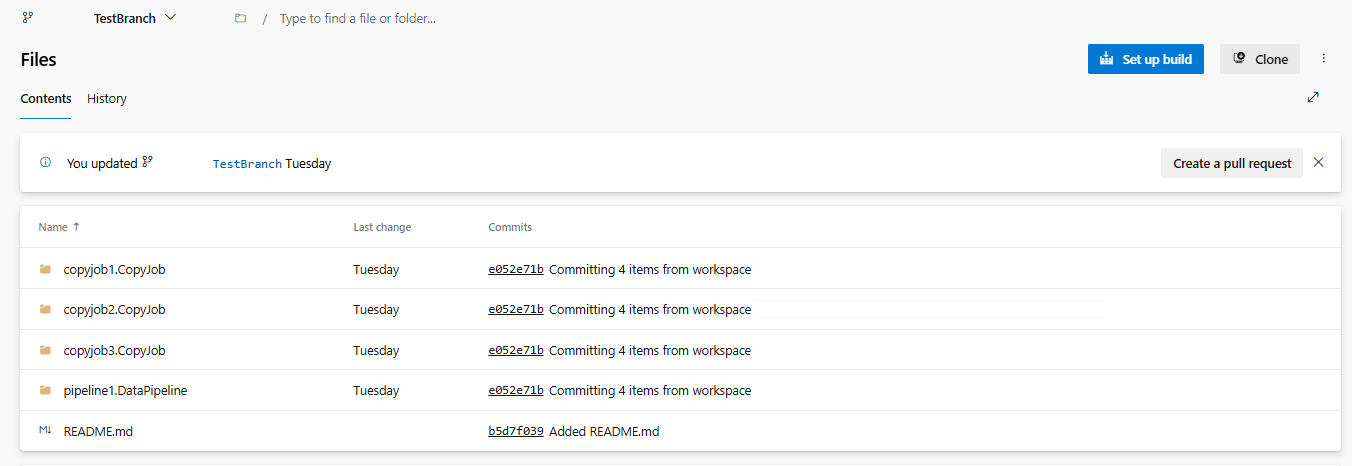
Herstel de CopyJob uit de ADO-opslagplaats.
Maak in de zojuist gemaakte werkruimte opnieuw verbinding met uw Azure ADO-opslagplaats en synchroniseer deze. Alle Fabric-items in deze opslagplaats worden automatisch gedownload naar uw nieuwe werkruimte.
Als de oorspronkelijke CopyJob gebruikmaakt van een Lakehouse, kunnen gebruikers verwijzen naar de sectie Lakehouse om het Lakehouse te herstellen en vervolgens de zojuist herstelde CopyJob te verbinden met het zojuist herstelde Lakehouse.
Zie Inleiding tot Git-integratie voor meer informatie over Git-integratie.
Realtime intelligentie
In deze handleiding wordt u begeleid bij de herstelprocedures voor de realtime intelligence-ervaring. Hierin worden KQL-databases/querysets en eventstreams behandeld.
KQL-database/queryset
KQL-database-/querysetgebruikers moeten proactieve maatregelen treffen om te beschermen tegen een regionaal noodgeval. De volgende aanpak zorgt ervoor dat in het geval van een regionale ramp gegevens in uw KQL-databasesquerysets veilig en toegankelijk blijven.
Gebruik de volgende stappen om een effectieve oplossing voor herstel na noodgevallen te garanderen voor KQL-databases en querysets.
Onafhankelijke KQL-databases tot stand brengen: configureer twee of meer onafhankelijke KQL-databases/querysets voor toegewezen fabric-capaciteiten. Deze moeten worden ingesteld in twee verschillende Azure-regio's (bij voorkeur gekoppelde Azure-regio's) om de tolerantie te maximaliseren.
Beheeractiviteiten repliceren: alle beheeracties die in de ene KQL-database worden uitgevoerd, moeten in de andere worden gespiegeld. Dit zorgt ervoor dat beide databases gesynchroniseerd blijven. Belangrijke activiteiten die moeten worden gerepliceerd, zijn onder andere:
Tabellen: zorg ervoor dat de tabelstructuren en schemadefinities consistent zijn in de databases.
Toewijzing: eventuele vereiste toewijzingen dupliceren. Zorg ervoor dat gegevensbronnen en bestemmingen correct zijn uitgelijnd.
Beleid: zorg ervoor dat beide databases vergelijkbare gegevensretentie, toegang en ander relevant beleid hebben.
Verificatie en autorisatie beheren: Stel voor elke replica de vereiste machtigingen in. Zorg ervoor dat de juiste autorisatieniveaus tot stand zijn gebracht, waarbij toegang wordt verleend tot het vereiste personeel, terwijl de beveiligingsstandaarden behouden blijven.
Parallelle gegevensopname: als u de gegevens consistent en gereed wilt houden in meerdere regio's, laadt u dezelfde gegevensset in elke KQL-database op hetzelfde moment als u deze opneemt.
Eventstream
Een eventstream is een gecentraliseerde locatie in het Fabric-platform voor het vastleggen, transformeren en routeren van realtime gebeurtenissen naar verschillende bestemmingen (bijvoorbeeld lakehouses, KQL-databases/querysets) met een ervaring zonder code. Zolang de bestemmingen worden ondersteund door herstel na noodgevallen, gaan eventstreams geen gegevens kwijt. Daarom moeten klanten de mogelijkheden voor herstel na noodgevallen van deze doelsystemen gebruiken om de beschikbaarheid van gegevens te garanderen.
Klanten kunnen ook georedundantie bereiken door identieke Eventstream-workloads in meerdere Azure-regio's te implementeren als onderdeel van een actieve/actieve strategie voor meerdere sites. Met een actieve/actieve benadering voor meerdere sites hebben klanten toegang tot hun workload in een van de geïmplementeerde regio's. Deze benadering is de meest complexe en kostbare benadering van herstel na noodgevallen, maar kan de hersteltijd in de meeste situaties verminderen tot bijna nul. Om volledig geografisch redundant te zijn, kunnen klanten
Maak replica's van hun gegevensbronnen in verschillende regio's.
Eventstream-items maken in de bijbehorende regio's.
Verbind deze nieuwe items met de identieke gegevensbronnen.
Voeg identieke bestemmingen toe voor elke eventstream in verschillende regio's.