Multidimensionale anomaliedetectie
Zie het overzicht van multivariate anomaliedetectie in Realtime Intelligence voor algemene informatie over multivariate anomaliedetectie in Microsoft Fabric. In deze zelfstudie gebruikt u voorbeeldgegevens om een multivariate anomaliedetectiemodel te trainen met behulp van de Spark-engine in een Python-notebook. Vervolgens voorspelt u afwijkingen door het getrainde model toe te passen op nieuwe gegevens met behulp van de Eventhouse-engine. Met de eerste paar stappen stelt u uw omgevingen in en met de volgende stappen traint u het model en voorspelt u afwijkingen.
Vereisten
- Een werkruimte met een Capaciteit met Microsoft Fabric
- Rol van beheerder, inzender of lidin de werkruimte. Dit machtigingsniveau is nodig om items zoals een omgeving te maken.
- Een gebeurtenishouse in uw werkruimte met een database.
- De voorbeeldgegevens downloaden uit de GitHub-opslagplaats
- Het notebook downloaden vanuit de GitHub-opslagplaats
Deel 1: Beschikbaarheid van OneLake inschakelen
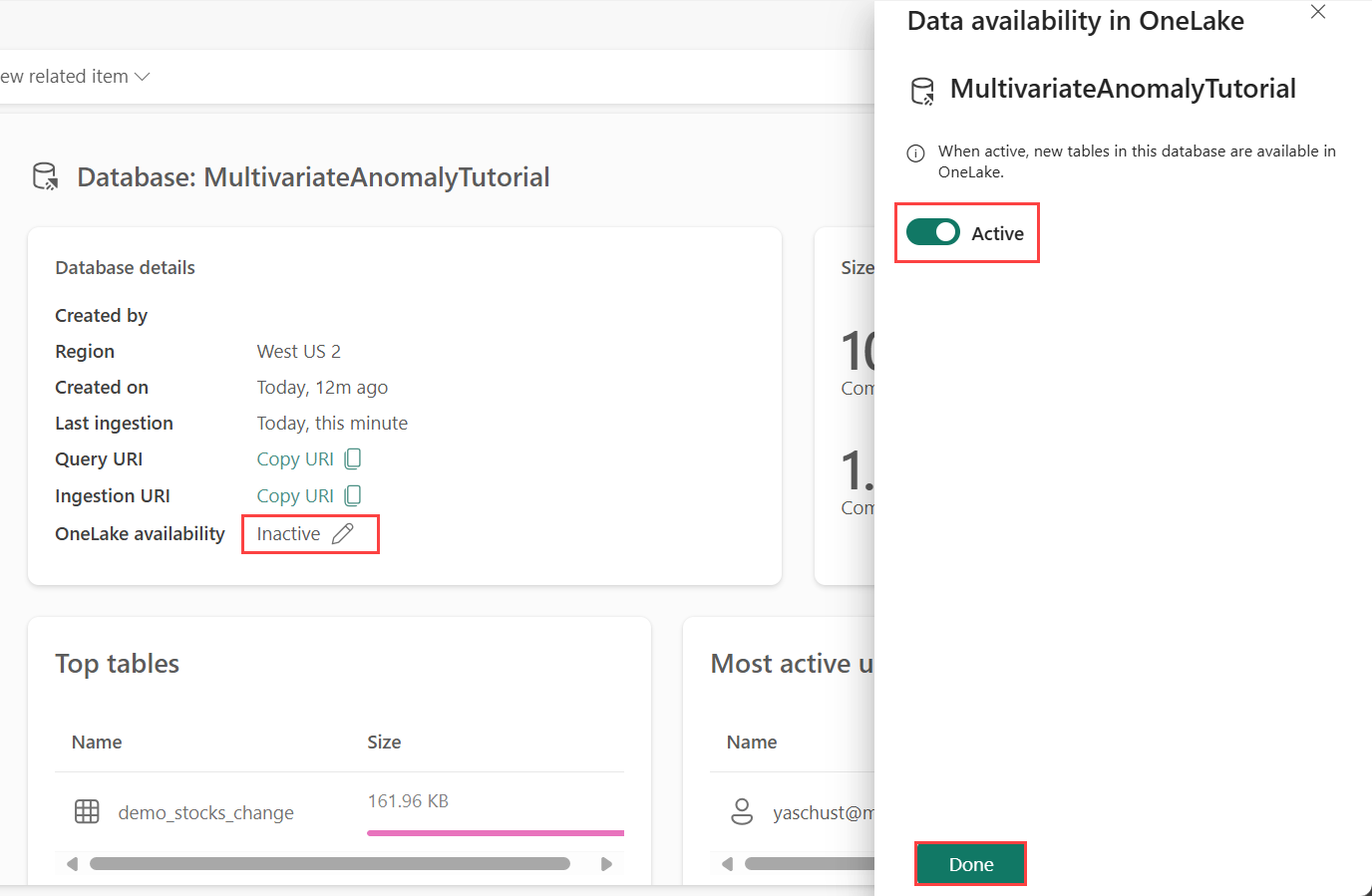
De beschikbaarheid van OneLake moet zijn ingeschakeld voordat u gegevens in Eventhouse krijgt. Deze stap is belangrijk, omdat hiermee de gegevens die u opneemt, beschikbaar zijn in OneLake. In een latere stap opent u dezelfde gegevens uit uw Spark Notebook om het model te trainen.
Selecteer in uw werkruimte het Eventhouse dat u hebt gemaakt in de voorwaarden. Kies de database waarin u uw gegevens wilt opslaan.
Schakel in het deelvenster Databasedetails de knop OneLake-beschikbaarheid naar Aan.
Deel 2: KQL Python-invoegtoepassing inschakelen
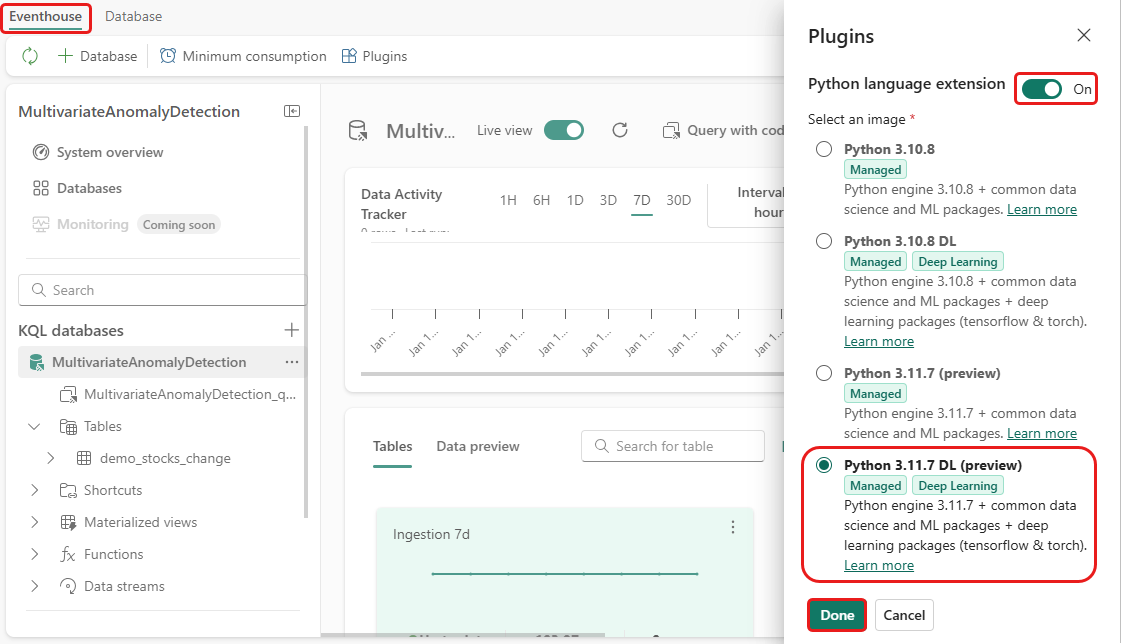
In deze stap schakelt u de Python-invoegtoepassing in uw Eventhouse in. Deze stap is vereist om de Python-code voor afwijkingen voorspellen uit te voeren in de KQL-queryset. Het is belangrijk om de juiste afbeelding te kiezen die het pakket time-series-anomaly-detector bevat.
Selecteer in het scherm Eventhouse Eventhouse>Plugins op het lint.
Schakel in het deelvenster Invoegtoepassingen de python-taalextensie in opAan.
Selecteer Python 3.11.7 DL (preview).
Selecteer Gereed.

Deel 3: Een Spark-omgeving maken
In deze stap maakt u een Spark-omgeving om het Python-notebook uit te voeren waarmee het multivariate anomaliedetectiemodel wordt getraind met behulp van de Spark-engine. Zie Omgevingen maken en beheren voor meer informatie over het maken van omgevingen.
In uw werkruimte selecteert u + Nieuw item en vervolgens Omgeving.
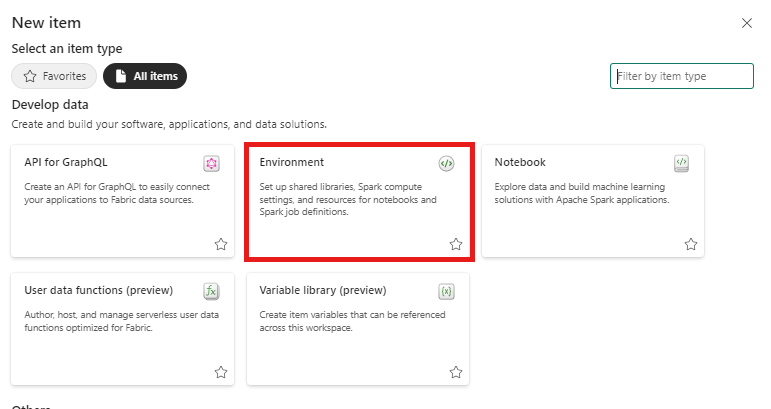
Voer de naam MVAD_ENV voor de omgeving in en selecteer Maken.
Selecteer op het tabblad Start van de omgeving Runtime>1.2 (Spark 3.4, Delta 2.4).
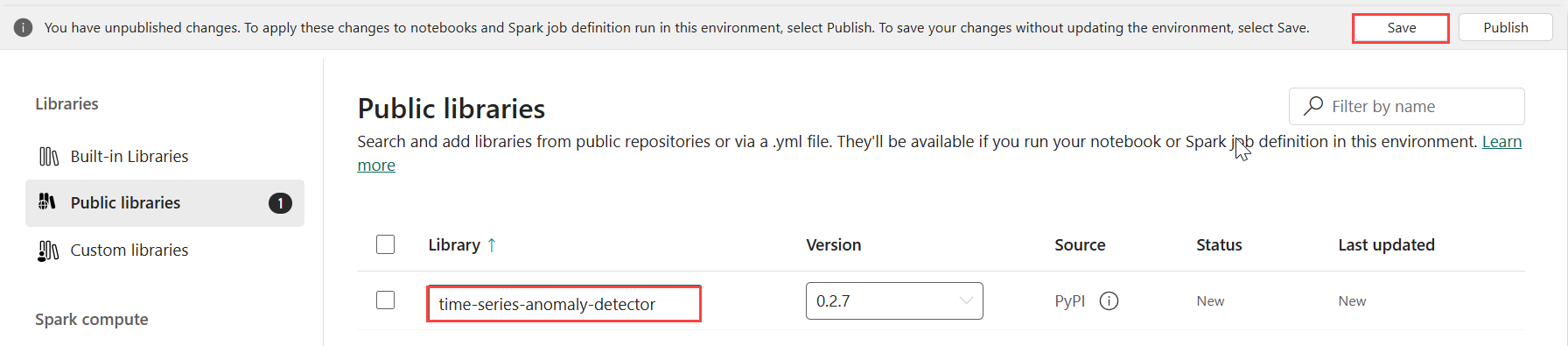
Selecteer openbare bibliotheken onder Bibliotheken.
Selecteer Toevoegen in PyPI.
Voer in het zoekvak tijdreeks-anomaliedetector in. De versie wordt automatisch gevuld met de meest recente versie. Deze zelfstudie is gemaakt met versie 0.3.2.
Selecteer Opslaan.
Selecteer het tabblad Start in de omgeving.
Selecteer het pictogram Publiceren op het lint.

Selecteer Alles publiceren. Het kan enkele minuten duren voordat deze stap is voltooid.


Deel 4: Gegevens ophalen in eventhouse
Beweeg de muisaanwijzer over de KQL-database waar u uw gegevens wilt opslaan. Selecteer het menu Meer [...]>>Gegevens lokaal bestand ophalen.
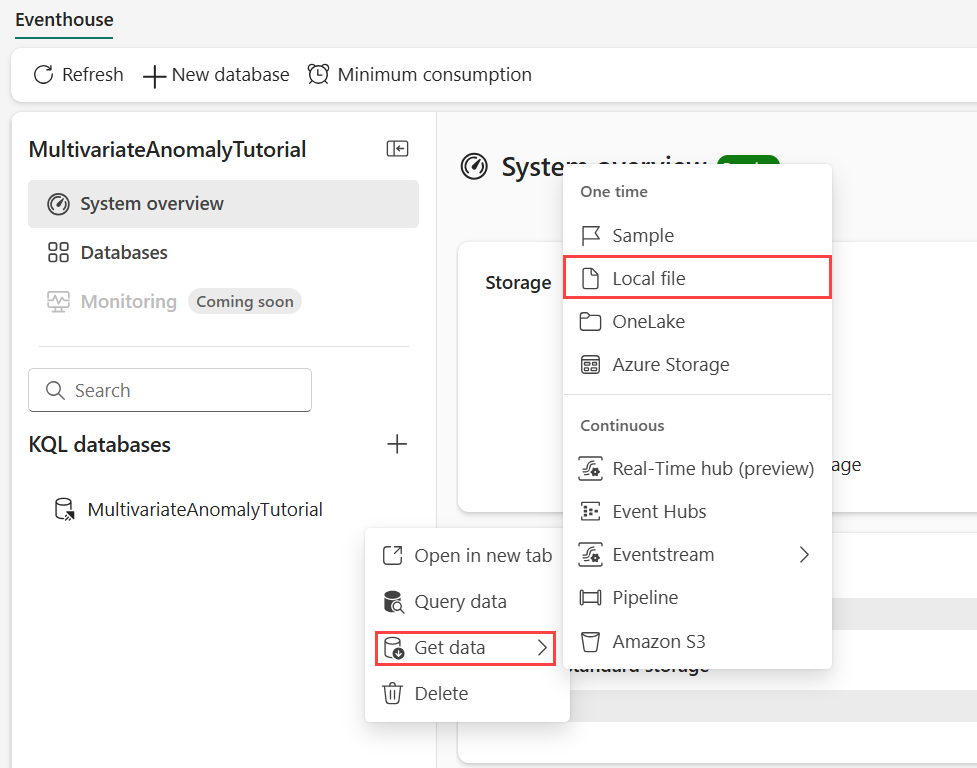
Selecteer + Nieuwe tabel en voer demo_stocks_change in als tabelnaam.
Selecteer Bladeren naar bestanden in het dialoogvenster Gegevens uploaden en upload het voorbeeldgegevensbestand dat is gedownload in de vereisten
Selecteer Volgende.
Schakel in de sectie Gegevens controleren de kolomkop Eerste rij in op Aan.
Selecteer Voltooien.
Wanneer de gegevens worden geüpload, selecteert u Sluiten.
Deel 5: OneLake-pad naar de tabel kopiëren
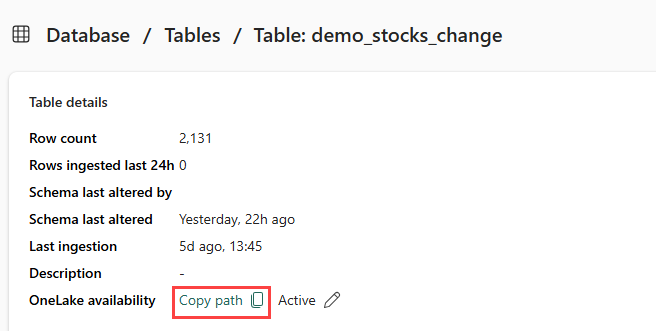
Zorg ervoor dat u de demo_stocks_change tabel selecteert. Selecteer in het deelvenster Tabeldetails de OneLake-map om het pad van OneLake naar uw klembord te kopiëren. Sla deze gekopieerde tekst op in een teksteditor die in een latere stap moet worden gebruikt.
Deel 6: Het notitieblok voorbereiden
Selecteer uw werkruimte.
Selecteer Importeren, Notitieblok en vervolgens vanaf deze computer.
Selecteer Uploaden en kies het notitieblok dat u hebt gedownload in de vereisten.
Nadat het notitieblok is geüpload, kunt u uw notitieblok zoeken en openen vanuit uw werkruimte.
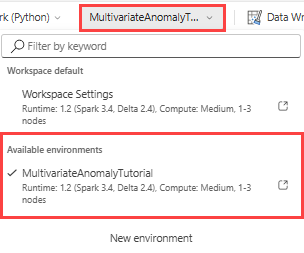
Selecteer in het bovenste lint de standaard vervolgkeuzelijst Werkruimte en selecteer de omgeving die u in de vorige stap hebt gemaakt.
Deel 7: Het notebook uitvoeren
Standaardpakketten importeren.
import numpy as np import pandas as pdSpark heeft een ABFSS-URI nodig om veilig verbinding te maken met OneLake-opslag. In de volgende stap wordt deze functie gedefinieerd om de OneLake-URI te converteren naar de ABFSS-URI.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriVervang de tijdelijke aanduiding OneLakeTableURI door uw gekopieerde OneLake-URI uit Deel 5 - Kopieer het OneLake-pad naar de tabel om de demo_stocks_change tabel in een pandas-gegevensframe te laden.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Voer de volgende cellen uit om de trainings- en voorspellingsgegevensframes voor te bereiden.
Notitie
De werkelijke voorspellingen worden uitgevoerd op gegevens door eventhouse in deel 9: Predict-anomalies-in-the-kql-queryset. Als u in een productiescenario gegevens naar het eventhouse streamt, worden de voorspellingen gedaan op de nieuwe streaminggegevens. Voor de zelfstudie is de gegevensset gesplitst op datum in twee secties voor training en voorspelling. Dit is om historische gegevens en nieuwe streaminggegevens te simuleren.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Voer de cellen uit om het model te trainen en op te slaan in het register van Fabric MLflow-modellen.
import mlflow from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name="mvad_5_stocks_model", )Voer de volgende cel uit om het geregistreerde modelpad te extraheren dat moet worden gebruikt voor voorspelling met behulp van de Kusto Python-sandbox.
mi = mlflow.search_registered_models(filter_string="name='mvad_5_stocks_model'")[0] model_abfss = mi.latest_versions[0].source print(model_abfss)Kopieer de model-URI uit de laatste celuitvoer voor gebruik in een latere stap.
Deel 8: Uw KQL-queryset instellen
Zie Een KQL-queryset maken voor algemene informatie.
- Selecteer in uw werkruimte +Nieuw item>KQL Queryset.
- Voer de naam MultivariateAnomalyDetectionTutorialin en selecteer Maken.
- Selecteer in het venster van de OneLake-gegevenshub de KQL-database waarin u de gegevens hebt opgeslagen.
- Selecteer Verbinding maken.
Deel 9: Afwijkingen voorspellen in de KQL-queryset
Voer de volgende query '.create-or-alter function' uit om de opgeslagen
predict_fabric_mvad_fl()functie te definiëren:.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Voer de volgende voorspellingsquery uit, waarbij u de URI van het uitvoermodel vervangt door de URI die aan het einde van stap 7is gekopieerd.
De query detecteert afwijkingen met meerdere variabelen op de vijf aandelen, op basis van het getrainde model, en geeft de resultaten weer als
anomalychart. De afwijkende punten worden weergegeven op het eerste aandeel (AAPL), hoewel ze multivariate anomalieën vertegenwoordigen (met andere woorden, afwijkingen van de gezamenlijke wijzigingen van de vijf voorraden op de specifieke datum).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Het resulterende anomaliediagram moet eruitzien als de volgende afbeelding:

Resources opschonen
Wanneer u klaar bent met de zelfstudie, kunt u de resources verwijderen die u hebt gemaakt om andere kosten te voorkomen. Voer de volgende stappen uit om de resources te verwijderen:
- Blader naar de startpagina van uw werkruimte.
- Verwijder de omgeving die u in deze zelfstudie hebt gemaakt.
- Verwijder het notitieblok dat u in deze zelfstudie hebt gemaakt.
- Verwijder de Eventhouse- of database die in deze zelfstudie wordt gebruikt.
- Verwijder de KQL-queryset die in deze zelfstudie is gemaakt.