Iceberg-tabellen gebruiken met OneLake
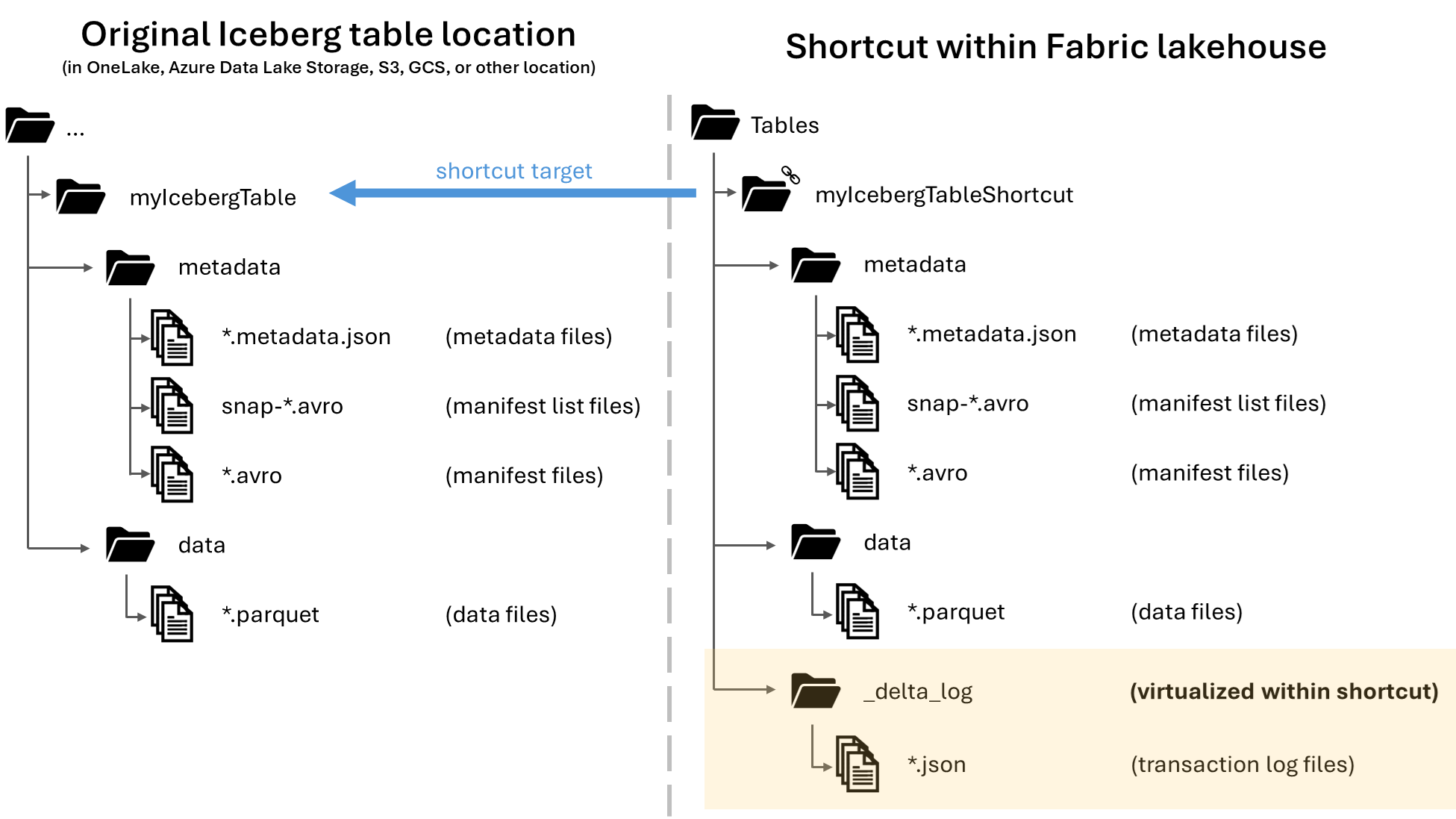
In Microsoft OneLake kunt u snelkoppelingen maken naar uw Apache Iceberg-tabellen, zodat ze kunnen worden gebruikt in de grote verscheidenheid aan Fabric-workloads. Deze functionaliteit wordt mogelijk gemaakt via een functie genaamd metagegevensvirtualisatie, waardoor Iceberg-tabellen vanuit het perspectief van de snelkoppeling kunnen worden geïnterpreteerd als Delta Lake-tabellen. Wanneer u een snelkoppeling naar een iceberg-tabelmap maakt, genereert OneLake automatisch de bijbehorende Delta Lake-metagegevens (het Delta-logboek) voor die tabel, waardoor de Delta Lake-metagegevens toegankelijk zijn via de snelkoppeling.
Belangrijk
Deze functie is beschikbaar als preview-versie.
Hoewel dit artikel richtlijnen bevat voor het schrijven van Iceberg-tabellen van Snowflake naar OneLake, is deze functie bedoeld om te werken met icebergtabellen met Parquet-gegevensbestanden.
Een snelkoppeling maken naar een Iceberg-tabel
Als u al een Iceberg-tabel hebt in een opslaglocatie die wordt ondersteund door OneLake-snelkoppelingen, volgt u deze stappen om een snelkoppeling te maken en uw Iceberg-tabel te laten verschijnen met de Delta Lake-indeling.
Zoek uw Iceberg-tafel. Zoek waar uw Iceberg-tabel is opgeslagen, die zich kan bevinden in Azure Data Lake Storage, OneLake, Amazon S3, Google Cloud Storage of een S3-compatibele opslagservice.
Notitie
Als u Snowflake gebruikt en niet zeker weet waar uw Iceberg-tabel is opgeslagen, kunt u de volgende instructie uitvoeren om de opslaglocatie van uw Iceberg-tabel te bekijken.
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('<table_name>');Als u deze instructie uitvoert, wordt een pad naar het metagegevensbestand voor de Iceberg-tabel geretourneerd. Dit pad geeft aan welk opslagaccount de Iceberg-tabel bevat. Hier volgt bijvoorbeeld de relevante informatie om het pad te vinden van een Iceberg-tabel die is opgeslagen in Azure Data Lake Storage:
{"metadataLocation":"azure://<storage_account_path>/<path_within_storage>/<table_name>/metadata/00001-389700a2-977f-47a2-9f5f-7fd80a0d41b2.metadata.json","status":"success"}De map Iceberg-tabel moet een
metadatamap bevatten, die zelf ten minste één bestand bevat dat eindigt op.metadata.json.Maak in uw Fabric Lakehouse een nieuwe snelkoppeling in het gebied Tabellen van een lakehouse zonder schema .
Notitie
Als u schema's ziet, zoals
dboonder de map Tabellen van uw lakehouse, is het lakehouse schema ingeschakeld en is het nog niet compatibel met deze functie.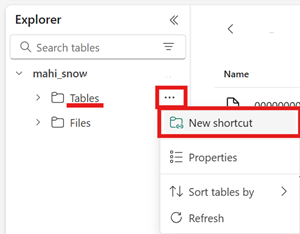
Selecteer de map Iceberg-tabel voor het doelpad van uw snelkoppeling. De tabelmap Iceberg bevat de
metadatamap endatamappen.Zodra uw snelkoppeling is gemaakt, ziet u deze tabel automatisch weergegeven als een Delta Lake-tabel in uw lakehouse, zodat u deze overal in Fabric kunt gebruiken.
Als de nieuwe snelkoppeling naar de Iceberg-tabel niet wordt weergegeven als een bruikbare tabel, raadpleegt u de sectie Probleemoplossing .
Een Iceberg-tabel naar OneLake schrijven met Snowflake
Als u Snowflake in Azure gebruikt, kunt u Iceberg-tabellen schrijven naar OneLake door de volgende stappen uit te voeren:
Zorg ervoor dat uw Fabric-capaciteit zich op dezelfde Azure-locatie bevindt als uw Snowflake-exemplaar.
Identificeer de locatie van de infrastructuurcapaciteit die is gekoppeld aan uw Fabric Lakehouse. Open de instellingen van de Fabric-werkruimte die uw lakehouse bevat.
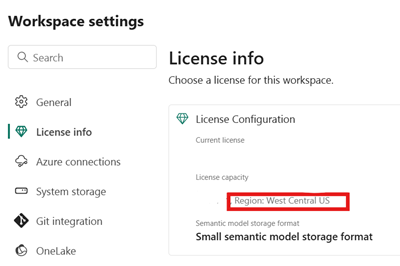
Controleer in de linkerbenedenhoek van uw Snowflake in de Azure-accountinterface de Azure-regio van het Snowflake-account.
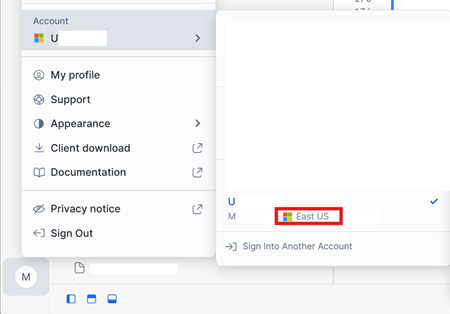
Als deze regio's verschillen, moet u een andere Infrastructuurcapaciteit gebruiken in dezelfde regio als uw Snowflake-account.
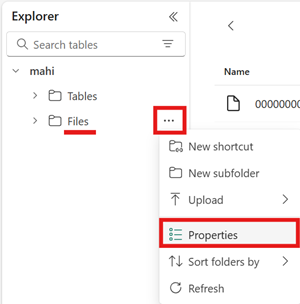
Open het menu voor het gebied Bestanden van uw lakehouse, selecteer Eigenschappen en kopieer de URL (het HTTPS-pad) van die map.
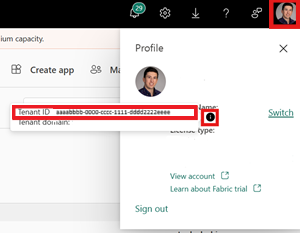
Identificeer uw Fabric-tenant-id. Selecteer uw gebruikersprofiel in de rechterbovenhoek van de infrastructuurgebruikersinterface en plaats de muisaanwijzer op de infoballon naast uw tenantnaam. Kopieer de Tenant-id.
Stel in Snowflake het
EXTERNAL VOLUMEpad naar de map Bestanden in uw lakehouse in. Meer informatie over het instellen van externe Snowflake-volumes vindt u hier.Notitie
Snowflake vereist dat het URL-schema is,
azure://dus zorg ervoor dat u wijzigthttps://inazure://.CREATE OR REPLACE EXTERNAL VOLUME onelake_exvol STORAGE_LOCATIONS = ( ( NAME = 'onelake_exvol' STORAGE_PROVIDER = 'AZURE' STORAGE_BASE_URL = 'azure://<path_to_Files>/icebergtables' AZURE_TENANT_ID = '<Tenant_ID>' ) );In dit voorbeeld worden alle tabellen die met dit externe volume zijn gemaakt, opgeslagen in fabric lakehouse, in de
Files/icebergtablesmap.Nu uw externe volume is gemaakt, voert u de volgende opdracht uit om de toestemmings-URL en de naam op te halen van de toepassing die Snowflake gebruikt om naar OneLake te schrijven. Deze toepassing wordt gebruikt door een ander extern volume in uw Snowflake-account.
DESC EXTERNAL VOLUME onelake_exvol;De uitvoer van deze opdracht retourneert de
AZURE_CONSENT_URLenAZURE_MULTI_TENANT_APP_NAMEeigenschappen. Noteer beide waarden. De naam van de Azure-multitenant-app ziet er ongeveer als volgt<name>_<number>uit, maar u hoeft alleen het<name>gedeelte vast te leggen.Open de toestemmings-URL uit de vorige stap in een nieuw browsertabblad. Als u wilt doorgaan, geeft u toestemming voor de vereiste toepassingsmachtigingen, indien hierom wordt gevraagd.
Open in Fabric uw werkruimte en selecteer Toegang beheren en voeg vervolgens personen of groepen toe. Verdeel de toepassing die wordt gebruikt door uw externe Snowflake-volume de machtigingen die nodig zijn voor het schrijven van gegevens naar Lakehouses in uw werkruimte. U wordt aangeraden de rol Inzender toe te kennen.
Gebruik in Snowflake uw nieuwe externe volume om een Iceberg-tabel te maken.
CREATE OR REPLACE ICEBERG TABLE MYDATABASE.PUBLIC.Inventory ( InventoryId int, ItemName STRING ) EXTERNAL_VOLUME = 'onelake_exvol' CATALOG = 'SNOWFLAKE' BASE_LOCATION = 'Inventory/';Met deze instructie wordt een nieuwe map Iceberg-tabel met de naam Inventory gemaakt binnen het mappad dat is gedefinieerd in het externe volume.
Voeg enkele gegevens toe aan uw Iceberg-tabel.
INSERT INTO MYDATABASE.PUBLIC.Inventory VALUES (123456,'Amatriciana');Ten slotte kunt u in het gebied Tabellen van hetzelfde lakehouse een OneLake-snelkoppeling naar uw Iceberg-tabel maken. Via deze snelkoppeling wordt uw Iceberg-tabel weergegeven als een Delta Lake-tabel voor gebruik in infrastructuurworkloads.
Probleemoplossing
Met de volgende tips kunt u ervoor zorgen dat uw Iceberg-tabellen compatibel zijn met deze functie:
Controleer de mapstructuur van uw Iceberg-tabel
Open uw Iceberg-map in het hulpprogramma opslagverkenner van uw voorkeur en controleer de mappenlijst van uw Iceberg-map op de oorspronkelijke locatie. Als het goed is, ziet u een mapstructuur zoals in het volgende voorbeeld.
../
|-- MyIcebergTable123/
|-- data/
|-- snow_A5WYPKGO_2o_APgwTeNOAxg_0_1_002.parquet
|-- snow_A5WYPKGO_2o_AAIBON_h9Rc_0_1_003.parquet
|-- metadata/
|-- 00000-1bdf7d4c-dc90-488e-9dd9-2e44de30a465.metadata.json
|-- 00001-08bf3227-b5d2-40e2-a8c7-2934ea97e6da.metadata.json
|-- 00002-0f6303de-382e-4ebc-b9ed-6195bd0fb0e7.metadata.json
|-- 1730313479898000000-Kws8nlgCX2QxoDHYHm4uMQ.avro
|-- 1730313479898000000-OdsKRrRogW_PVK9njHIqAA.avro
|-- snap-1730313479898000000-9029d7a2-b3cc-46af-96c1-ac92356e93e9.avro
|-- snap-1730313479898000000-913546ba-bb04-4c8e-81be-342b0cbc5b50.avro
Als u de map met metagegevens niet ziet of als u geen bestanden ziet met de extensies die in dit voorbeeld worden weergegeven, hebt u mogelijk geen correct gegenereerde Iceberg-tabel.
Het conversielogboek controleren
Wanneer een Iceberg-tabel wordt gevirtualiseerd als een Delta Lake-tabel, kunt u een map met de naam _delta_log/ vinden in de snelkoppelingsmap. Deze map bevat de metagegevens van de Delta Lake-indeling (het Delta-logboek) na een geslaagde conversie.
Deze map bevat ook het latest_conversion_log.txt bestand, dat de meest recente geslaagde conversie- of foutdetails bevat.
Als u de inhoud van dit bestand wilt zien nadat u de snelkoppeling hebt gemaakt, opent u het menu voor de snelkoppeling naar de Iceberg-tabel onder het gebied Tabellen van uw lakehouse en selecteert u Bestanden weergeven.
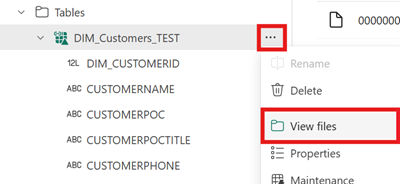
U ziet een structuur zoals in het volgende voorbeeld:
Tables/
|-- MyIcebergTable123/
|-- data/
|-- <data files>
|-- metadata/
|-- <metadata files>
|-- _delta_log/ <-- Virtual folder. This folder doesn't exist in the original location.
|-- 00000000000000000000.json
|-- latest_conversion_log.txt <-- Conversion log with latest success/failure details.
Open het conversielogboekbestand om de meest recente conversietijd of foutdetails weer te geven. Als u geen conversielogboekbestand ziet, is er geen conversiepoging uitgevoerd.
Als er geen conversie is geprobeerd
Als u geen conversielogboekbestand ziet, is de conversie niet geprobeerd. Hier volgen twee veelvoorkomende redenen waarom de conversie niet wordt geprobeerd:
De snelkoppeling is niet op de juiste plaats gemaakt.
Als u een snelkoppeling naar een Iceberg-tabel wilt converteren naar de Delta Lake-indeling, moet de snelkoppeling rechtstreeks onder de map Tabellen van een lakehouse zonder schema worden geplaatst. Plaats de snelkoppeling niet in de sectie Bestanden of onder een andere map als u wilt dat de tabel automatisch wordt gevirtualiseerd als een Delta Lake-tabel.
Het doelpad van de snelkoppeling is niet het pad naar de map Iceberg.
Wanneer u de snelkoppeling maakt, mag het mappad dat u selecteert in de doelopslaglocatie alleen de map Iceberg-tabel zijn. Deze map bevat de
metadataendatamappen.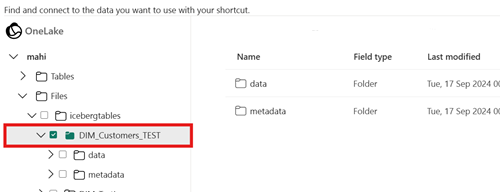
Beperkingen en overwegingen
Houd rekening met de volgende tijdelijke beperkingen wanneer u deze functie gebruikt:
Ondersteunde gegevenstypen
De volgende gegevenstypen van icebergkolommen zijn toegewezen aan de bijbehorende Delta Lake-typen met behulp van deze functie.
Type ijsbergkolom Kolomtype Delta Lake Opmerkingen intintegerlonglongZie Probleem met de breedte van het type. floatfloatdoubledoubleZie Probleem met de breedte van het type. decimal(P, S)decimal(P, S)Zie Probleem met de breedte van het type. booleanbooleandatedatetimestamptimestamp_ntzHet timestampgegevenstype Iceberg bevat geen tijdzonegegevens. Hettimestamp_ntzDelta Lake-type wordt niet volledig ondersteund in Fabric-workloads. U wordt aangeraden tijdstempels te gebruiken met opgenomen tijdzones.timestamptztimestampAls u dit type in Snowflake wilt gebruiken, geeft u timestamp_ltzop als het kolomtype tijdens het maken van de Iceberg-tabel. Meer informatie over iceberggegevenstypen die worden ondersteund in Snowflake vindt u hier.stringstringbinarybinaryProbleem met typebreedte
Als u Snowflake gebruikt om uw Iceberg-tabel te schrijven en de tabel kolomtypen
INT64bevat,doubleofDecimalmet precisie >= 10, kan de resulterende virtuele Delta Lake-tabel mogelijk niet worden gebruikt door alle Fabric-engines. Mogelijk worden er fouten weergegeven, zoals:Parquet column cannot be converted in file ... Column: [ColumnA], Expected: decimal(18,4), Found: INT32.Er wordt gewerkt aan een oplossing voor dit probleem.
Tijdelijke oplossing: als u de preview-gebruikersinterface van de Lakehouse-tabel gebruikt en dit probleem ziet, kunt u deze fout oplossen door over te schakelen naar de weergave SQL-eindpunt (rechterbovenhoek, Lakehouse-weergave te selecteren, over te schakelen naar SQL-eindpunt) en een voorbeeld van de tabel te bekijken. Als u vervolgens terugschakelt naar de Lakehouse-weergave, wordt het voorbeeld van de tabel correct weergegeven.
Als u een Spark-notebook of -taak uitvoert en dit probleem ondervindt, kunt u deze fout oplossen door de
spark.sql.parquet.enableVectorizedReaderSpark-configuratie in te stellen opfalse. Hier volgt een voorbeeld van een PySpark-opdracht die moet worden uitgevoerd in een Spark-notebook:spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")Opslag van metagegevens van icebergtabel is niet draagbaar
De metagegevensbestanden van een Iceberg-tabel verwijzen naar elkaar met behulp van absolute padverwijzingen. Als u de mapinhoud van een Iceberg-tabel naar een andere locatie kopieert of verplaatst zonder de metagegevensbestanden van iceberg opnieuw te schrijven, wordt de tabel onleesbaar door Iceberg-lezers, waaronder deze OneLake-functie.
Tijdelijke oplossing:
Als u uw Iceberg-tabel naar een andere locatie wilt verplaatsen om deze functie te gebruiken, gebruikt u het hulpprogramma dat oorspronkelijk de Iceberg-tabel heeft geschreven om een nieuwe Iceberg-tabel op de gewenste locatie te schrijven.
Ijsbergtabellen moeten dieper zijn dan het hoofdniveau
De map Iceberg-tabel in opslag moet zich in een map bevinden die dieper is dan bucket- of containerniveau. IJsbergtabellen die rechtstreeks in de hoofdmap van een bucket of container zijn opgeslagen, worden mogelijk niet gevirtualiseerd naar de Delta Lake-indeling.
We werken aan een verbetering om deze vereiste te verwijderen.
Tijdelijke oplossing:
Zorg ervoor dat ijsbergtabellen worden opgeslagen in een map die dieper is dan de hoofdmap van een bucket of container.
Iceberg-tabelmappen mogen slechts één set metagegevensbestanden bevatten
Als u een Iceberg-tabel in Snowflake neer zet en opnieuw maakt, worden de metagegevensbestanden niet opgeschoond. Dit gedrag wordt ondersteund door de
UNDROPfunctie in Snowflake. Omdat uw snelkoppeling echter rechtstreeks naar een map verwijst en die map nu meerdere sets metagegevensbestanden bevat, kunnen we de tabel pas converteren als u de metagegevensbestanden van de oude tabel verwijdert.Op dit moment wordt geprobeerd de conversie in dit scenario uit te voeren. Dit kan ertoe leiden dat oude inhoudsopgaven en schemagegevens worden weergegeven in de gevirtualiseerde Delta Lake-tabel.
Er wordt gewerkt aan een oplossing waarbij de conversie mislukt als er meer dan één set metagegevensbestanden in de map met metagegevens van de Iceberg-tabel wordt gevonden.
Tijdelijke oplossing:
Om ervoor te zorgen dat de geconverteerde tabel de juiste versie van de tabel weerspiegelt:
- Zorg ervoor dat u niet meer dan één Iceberg-tabel in dezelfde map opslaat.
- Schoon alle inhoud van een Iceberg-tabelmap op nadat deze is neergeslagen, voordat u de tabel opnieuw maakt.
Wijzigingen in metagegevens worden niet onmiddellijk doorgevoerd
Als u metagegevens aanbrengt in uw Iceberg-tabel, zoals het toevoegen van een kolom, het verwijderen van een kolom, het wijzigen van de naam van een kolom of het wijzigen van een kolomtype, wordt de tabel mogelijk niet opnieuw ingesteld totdat een gegevenswijziging is aangebracht, zoals het toevoegen van een rij met gegevens.
Er wordt gewerkt aan een oplossing waarmee het juiste meest recente metagegevensbestand wordt opgehaald dat de meest recente wijziging van de metagegevens bevat.
Tijdelijke oplossing:
Nadat u het schema hebt gewijzigd in uw Iceberg-tabel, voegt u een rij met gegevens toe of breng u een andere wijziging aan in de gegevens. Na deze wijziging moet u de meest recente weergave van uw tabel in Fabric kunnen vernieuwen en bekijken.
Werkruimten waarvoor schema is ingeschakeld, worden nog niet ondersteund
Als u een Iceberg-snelkoppeling maakt in een lakehouse met schema's, vindt de conversie niet plaats voor die snelkoppeling.
We werken aan een verbetering om deze beperking te verwijderen.
Tijdelijke oplossing:
Gebruik een lakehouse zonder schema met deze functie. U kunt deze instelling configureren tijdens het maken van Lakehouse.
Beperking van beschikbaarheid van regio's
De functie is nog niet beschikbaar in de volgende regio's:
- Qatar - centraal
- Noorwegen - west
Tijdelijke oplossing:
Werkruimten die zijn gekoppeld aan infrastructuurcapaciteiten in andere regio's, kunnen deze functie gebruiken. Bekijk de volledige lijst met regio's waar Microsoft Fabric beschikbaar is.
Privékoppelingen worden niet ondersteund
Deze functie wordt momenteel niet ondersteund voor tenants of werkruimten waarvoor privékoppelingen zijn ingeschakeld.
We werken aan een verbetering om deze beperking te verwijderen.
Beperking van tabelgrootte
We hebben een tijdelijke beperking voor de grootte van de Iceberg-tabel die door deze functie wordt ondersteund. Het maximaal ondersteunde aantal Parquet-gegevensbestanden is ongeveer 5.000 gegevensbestanden, of ongeveer 1 miljard rijen, afhankelijk van de limiet die het eerst wordt aangetroffen.
We werken aan een verbetering om deze beperking te verwijderen.
OneLake-snelkoppelingen moeten dezelfde regio zijn
We hebben een tijdelijke beperking voor het gebruik van deze functie met sneltoetsen die verwijzen naar OneLake-locaties: de doellocatie van de snelkoppeling moet zich in dezelfde regio bevinden als de snelkoppeling zelf.
We werken aan een verbetering om deze vereiste te verwijderen.
Tijdelijke oplossing:
Als u een OneLake-snelkoppeling naar een Iceberg-tabel in een ander lakehouse hebt, moet u ervoor zorgen dat het andere lakehouse is gekoppeld aan een capaciteit in dezelfde regio.
tenantswitch externe toegang toestaan
We hebben een tijdelijke beperking waarvoor de 'Gebruikers hebben toegang tot gegevens die zijn opgeslagen in OneLake met apps buiten Fabric' tenantinstelling moeten worden ingeschakeld.
Als deze tenantinstelling is uitgeschakeld, zal de virtualisatie van Iceberg-tabellen naar de Delta Lake-indeling mislukken.
Tijdelijke oplossing:
Laat, indien mogelijk, uw Fabric-tenantbeheerder de tenantinstelling 'Gebruikers kunnen met apps buiten Fabric toegang krijgen tot gegevens die zijn opgeslagen in OneLake' inschakelen.
nl-NL: Iceberg-tabellen moeten copy-on-write zijn (en niet merge-on-read)
Op dit moment moeten Iceberg-tabellen worden copy-on-write-. Dit betekent dat ze geen bestanden kunnen verwijderen of samenvoegen-op-lezen.
Snowflake maakt momenteel copy-on-write Iceberg-tabellen, maar andere Iceberg-schrijvers kunnen een andere benadering volgen.
We werken aan ondersteuning voor merge-on-read Iceberg-tabellen.
Gerelateerde inhoud
- Meer informatie over Fabric- en OneLake-beveiliging.
- Meer informatie over OneLake-snelkoppelingen.