Recept: Azure AI-services - Anomaliedetectie met meerderevariaties
Dit recept laat zien hoe u SynapseML- en Azure AI-services op Apache Spark kunt gebruiken voor anomaliedetectie met meerdere variabelen. Met multivariate anomaliedetectie kunnen afwijkingen tussen veel variabelen of tijdreeksen worden gedetecteerd, rekening houdend met alle intercorrelaties en afhankelijkheden tussen de verschillende variabelen. In dit scenario gebruiken we SynapseML om een model te trainen voor multivariate anomaliedetectie met behulp van de Azure AI-services. Vervolgens gebruiken we het model om afwijkingen met meerdere variabelen af te leiden in een gegevensset die synthetische metingen van drie IoT-sensoren bevat.
Belangrijk
Vanaf 20 september 2023 kunt u geen nieuwe Anomaly Detector-resources maken. De Anomaly Detector-service wordt op 1 oktober 2026 buiten gebruik gesteld.
Raadpleeg deze documentatiepagina voor meer informatie over de Azure AI Anomaly Detector.
Vereisten
- Een Azure-abonnement - Een gratis abonnement maken
- Koppel uw notitieblok aan een lakehouse. Selecteer aan de linkerkant Toevoegen om een bestaand lakehouse toe te voegen of een lakehouse te maken.
Instellingen
Volg de instructies voor het maken van een Anomaly Detector resource met behulp van Azure Portal of u kunt ook de Azure CLI gebruiken om deze resource te maken.
Nadat u een Anomaly Detectorhebt ingesteld, kunt u methoden voor het verwerken van gegevens van verschillende formulieren verkennen. De catalogus met services in Azure AI biedt verschillende opties: Vision, Speech, Language, Web search, Decision, Translation en Document Intelligence.
Een Anomaly Detector-resource maken
- Selecteer maken in de Azure-portal in uw resourcegroep en typ vervolgens Anomaly Detector. Selecteer de Anomaly Detector-resource.
- Geef de resource een naam en gebruik idealiter dezelfde regio als de rest van uw resourcegroep. Gebruik de standaardopties voor de rest en selecteer Vervolgens Beoordelen + Maken en vervolgens Maken.
- Zodra de Anomaly Detector-resource is gemaakt, opent u deze en selecteert u het
Keys and Endpointsdeelvenster in het linkernavigatievenster. Kopieer de sleutel voor de Anomaly Detector-resource naar deANOMALY_API_KEYomgevingsvariabele of sla deze op in deanomalyKeyvariabele.
Een opslagaccountresource maken
Als u tussenliggende gegevens wilt opslaan, moet u een Azure Blob Storage-account maken. Maak binnen dat opslagaccount een container voor het opslaan van de tussenliggende gegevens. Noteer de containernaam en kopieer de verbindingsreeks naar die container. U hebt deze later nodig om de containerName variabele en de BLOB_CONNECTION_STRING omgevingsvariabele te vullen.
Voer uw servicesleutels in
Laten we beginnen met het instellen van de omgevingsvariabelen voor onze servicesleutels. In de volgende cel worden de ANOMALY_API_KEY en de BLOB_CONNECTION_STRING omgevingsvariabelen ingesteld op basis van de waarden die zijn opgeslagen in Azure Key Vault. Als u deze zelfstudie uitvoert in uw eigen omgeving, moet u deze omgevingsvariabelen instellen voordat u verdergaat.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Laten we nu de ANOMALY_API_KEY en BLOB_CONNECTION_STRING omgevingsvariabelen lezen en de containerName en location variabelen instellen.
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Eerst maken we verbinding met ons opslagaccount, zodat anomaliedetector daar tussenliggende resultaten kan opslaan:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Laten we alle benodigde modules importeren.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Laten we nu onze voorbeeldgegevens lezen in een Spark DataFrame.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
We kunnen nu een estimator object maken dat wordt gebruikt om ons model te trainen. We geven de begin- en eindtijden op voor de trainingsgegevens. We geven ook de invoerkolommen op die moeten worden gebruikt en de naam van de kolom die de tijdstempels bevat. Ten slotte geven we het aantal gegevenspunten op dat moet worden gebruikt in het schuifvenster voor anomaliedetectie en stellen we de verbindingsreeks in op het Azure Blob Storage-account.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Nu we de gegevens estimatorhebben gemaakt, passen we deze aan de gegevens:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Toen we in de vorige cel aanbelden .show(5) , werden de eerste vijf rijen in het dataframe weergegeven. De resultaten waren allemaal null omdat ze zich niet in het deductievenster bevonden.
Als u alleen de resultaten voor de uitgestelde gegevens wilt weergeven, kunt u de kolommen selecteren die we nodig hebben. Vervolgens kunnen we de rijen in het gegevensframe op oplopende volgorde rangschikken en het resultaat filteren om alleen de rijen weer te geven die zich in het bereik van het deductievenster bevinden. In ons geval inferenceEndTime is hetzelfde als de laatste rij in het dataframe, dus kan dat negeren.
Ten slotte kunt u de resultaten beter uitzetten door het Spark-gegevensframe te converteren naar een Pandas-gegevensframe.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Maak de contributors kolom op waarin de bijdragescore van elke sensor wordt opgeslagen in de gedetecteerde afwijkingen. In de volgende cel worden deze gegevens opgemaakt en wordt de bijdragescore van elke sensor gesplitst in een eigen kolom.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Mooi! We hebben nu de bijdragescores van sensoren 1, 2 en 3 in respectievelijk de series_0, series_1en series_2 kolommen.
Voer de volgende cel uit om de resultaten uit te tekenen. De minSeverity parameter specificeert de minimale ernst van de afwijkingen die moeten worden weergegeven.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
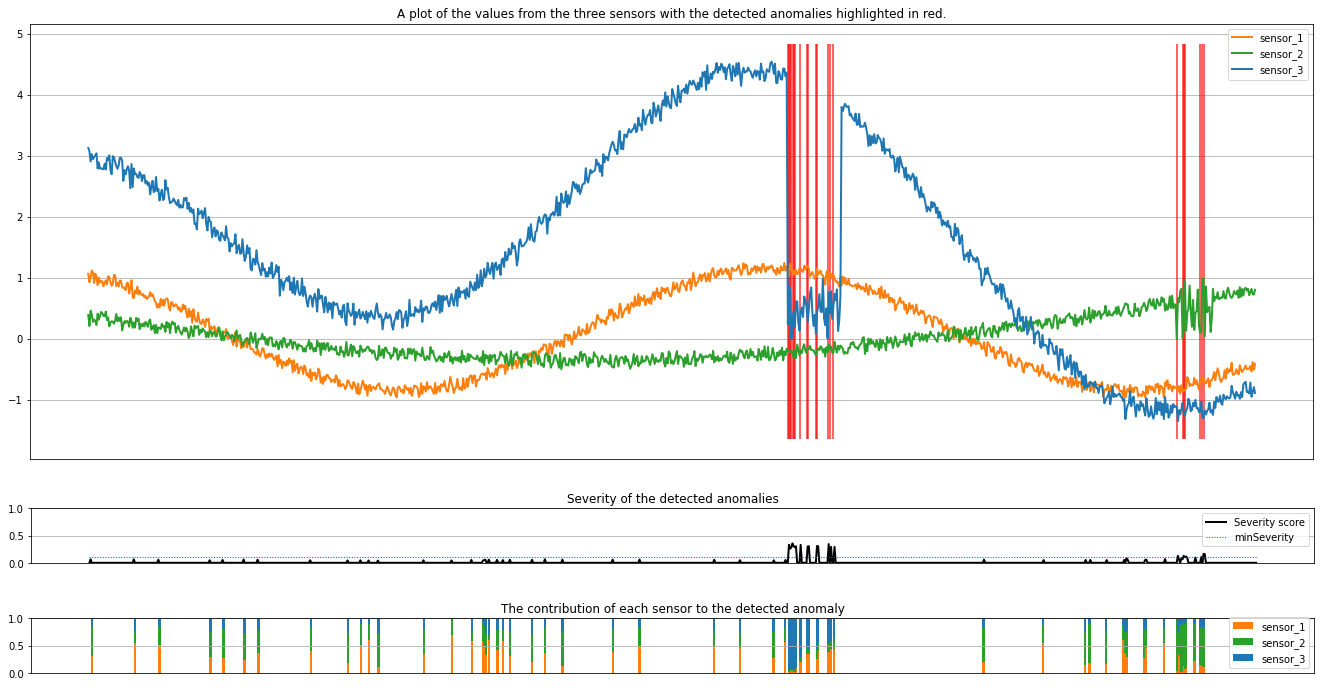
De plots tonen de onbewerkte gegevens van de sensoren (in het deductievenster) in oranje, groen en blauw. De rode verticale lijnen in de eerste afbeelding tonen de gedetecteerde afwijkingen met een ernst die groter is dan of gelijk is aan minSeverity.
In het tweede diagram ziet u de ernstscore van alle gedetecteerde afwijkingen, met de minSeverity drempelwaarde die wordt weergegeven in de rode stippellijn.
Ten slotte toont de laatste plot de bijdrage van de gegevens van elke sensor aan de gedetecteerde afwijkingen. Het helpt ons bij het vaststellen en begrijpen van de meest waarschijnlijke oorzaak van elke anomalie.